实例代码
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge, LogisticRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
from sklearn.externals import joblib
from sklearn.metrics import r2_score
from sklearn.neural_network import MLPRegressor
import pandas as pd
import numpy as np
# 加载数据集
lb = load_boston()
#划分数据集
# train_test_split()函数用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签
# train_data:被划分的样本特征集
# train_target:被划分的样本标签
# test_size:如果是浮点数,在0-1之间,表示样本占比;如果是整数的话就是样本的数量
# random_state:是随机数的种子。种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.2)
# 为数据增加一个维度,相当于把 [1, 5, 10] 变成 [[1, 5, 10],](把它变为只有一列的)
y_train = y_train.reshape(-1, 1)
y_test = y_test.reshape(-1, 1)
# 进行标准化
# 作用:去均值和方差归一化。可保存训练集中的均值、方差参数,然后直接用于转换测试集数据。
# 使得新的X数据集方差为1,均值为0,fit_transform(X_train) 意思是找出X_train的μ和σ,并应用在X_train上
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
# 正规方程预测
# 调用sklearn中LR模型并训练模型
lr = LinearRegression()
#fit()简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性,可以理解为一个训练过程
lr.fit(x_train, y_train)
# 用r2_score()函数对模型进行打分。注:最好的得分为1.0,一般的得分都比1.0低,得分越低代表结果越差。
print("r2 score of Linear regression is",r2_score(y_test,lr.predict(x_test)))
#岭回归
from sklearn.linear_model import RidgeCV
cv = RidgeCV(alphas=np.logspace(-3, 2, 100))
cv.fit (x_train , y_train)
print("r2 score of Linear regression is",r2_score(y_test,cv.predict(x_test)))
#梯度下降
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
print("r2 score of Linear regression is",r2_score(y_test,sgd.predict(x_test)))
#构建神经网络模型
from keras.models import Sequential
from keras.layers import Dense
#基准NN
#使用标准化后的数据
seq = Sequential()
#input_dim来隐含的指定输入数据shape
seq.add(Dense(64, activation='relu',input_dim=lb.data.shape[1]))
seq.add(Dense(64, activation='relu'))
seq.add(Dense(1, activation='relu'))
seq.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
#fit()简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性,可以理解为一个训练过程
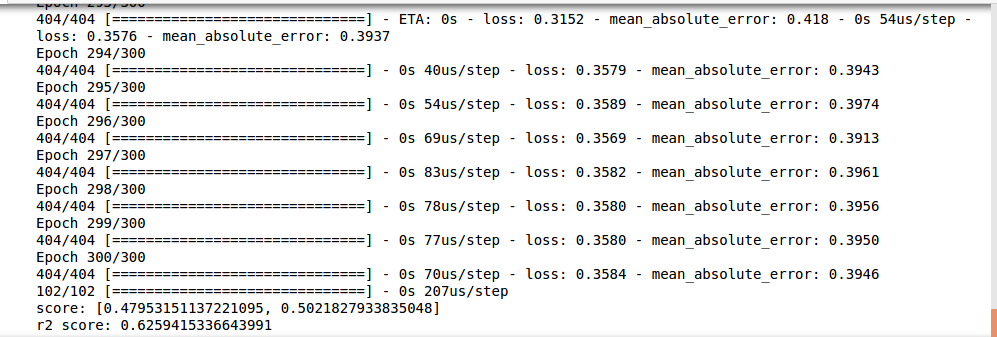
seq.fit(x_train, y_train, epochs=300, batch_size = 16, shuffle = False)
score = seq.evaluate(x_test, y_test,batch_size=16) #loss value & metrics values
print("score:",score)
print('r2 score:',r2_score(y_test, seq.predict(x_test)))
运行截图
- 正规方程

-
岭回归

-
梯度下降

-
神经网