使用的是python的pytesser模块,原先想做的是图片中文识别,搞了一段时间了,在中文的识别上还是有很多问题,这里做记录分享。
pytesser,OCR in Python using the Tesseract engine from Google。是谷歌OCR开源项目的一个模块,可将图片中的文字转换成文本(主要是英文)。
1.pytesser安装
使用设备:win8 64位
PyTesser使用Tesseract OCR引擎,将图像转换到可接受的格式,然后执行tesseract提取出文本信息。使用PyTesser ,你无须安装Tesseract OCR引擎,但必须要先安装PIL模块(Python Image Library,python的图形库)
pytesser下载:http://code.google.com/p/pytesser/ 若打不开,可通过百度网盘下载:http://pan.baidu.com/s/1o69LL8Y
PIL官方下载:http://www.pythonware.com/products/pil/
其中PIL可直接点击exe安装,pytesser无需安装,解压后可以放在python安装文件夹的Libsite-packages 下直接使用(需要添加pytesser.pth)
Ubuntu安装
sudo pip install pytesseract sudo apt-get install tesseract-ocr
2.pytesser源码
通过查看pytesser.py的源码,可以看到几个主要函数:
(1)call_tesseract(input_filename, output_filename)
该函数调用tesseract外部执行程序,提取图片中的文本信息
(2)image_to_string(im, cleanup = cleanup_scratch_flag)
该函数处理的是image对象,所以需用使用im = open(filename)打开文件,返回一个image对象。其中调用util.image_to_scratch(im, scratch_image_name)将内存中的图像文件保存为bmp,以便tesserac程序能正常处理。
(3)image_file_to_string(filename, cleanup = cleanup_scratch_flag, graceful_errors=True)
该函数直接使用Tesseract读取图像文件,如果图像是不相容的,会先转换成兼容的格式,然后再提取图片中的文本信息。
"""OCR in Python using the Tesseract engine from Google http://code.google.com/p/pytesser/ by Michael J.T. O'Kelly V 0.0.1, 3/10/07""" import Image import subprocess import util import errors tesseract_exe_name = 'tesseract' # Name of executable to be called at command line scratch_image_name = "temp.bmp" # This file must be .bmp or other Tesseract-compatible format scratch_text_name_root = "temp" # Leave out the .txt extension cleanup_scratch_flag = False # Temporary files cleaned up after OCR operation def call_tesseract(input_filename, output_filename): """Calls external tesseract.exe on input file (restrictions on types), outputting output_filename+'txt'""" args = [tesseract_exe_name, input_filename, output_filename] proc = subprocess.Popen(args) retcode = proc.wait() if retcode!=0: errors.check_for_errors() def image_to_string(im, cleanup = cleanup_scratch_flag): """Converts im to file, applies tesseract, and fetches resulting text. If cleanup=True, delete scratch files after operation.""" try: util.image_to_scratch(im, scratch_image_name) call_tesseract(scratch_image_name, scratch_text_name_root) text = util.retrieve_text(scratch_text_name_root) finally: if cleanup: util.perform_cleanup(scratch_image_name, scratch_text_name_root) return text def image_file_to_string(filename, cleanup = cleanup_scratch_flag, graceful_errors=True): """Applies tesseract to filename; or, if image is incompatible and graceful_errors=True, converts to compatible format and then applies tesseract. Fetches resulting text. If cleanup=True, delete scratch files after operation.""" try: try: call_tesseract(filename, scratch_text_name_root) text = util.retrieve_text(scratch_text_name_root) except errors.Tesser_General_Exception: if graceful_errors: im = Image.open(filename) text = image_to_string(im, cleanup) else: raise finally: if cleanup: util.perform_cleanup(scratch_image_name, scratch_text_name_root) return text if __name__=='__main__': im = Image.open('phototest.tif') text = image_to_string(im) print text try: text = image_file_to_string('fnord.tif', graceful_errors=False) except errors.Tesser_General_Exception, value: print "fnord.tif is incompatible filetype. Try graceful_errors=True" print value text = image_file_to_string('fnord.tif', graceful_errors=True) print "fnord.tif contents:", text text = image_file_to_string('fonts_test.png', graceful_errors=True) print text
3.pytesser使用
在代码中加载pytesser模块,简单的测试代码如下:
from pytesser import * im = Image.open('fonts_test.png') text = image_to_string(im) print "Using image_to_string(): " print text text = image_file_to_string('fonts_test.png', graceful_errors=True) print "Using image_file_to_string():" print text

识别结果如下:基本能将英文字符提取出来,但对一些复杂点的图片,比如说我尝试对一些英文论文图片进行识别,但结果实在不理想。
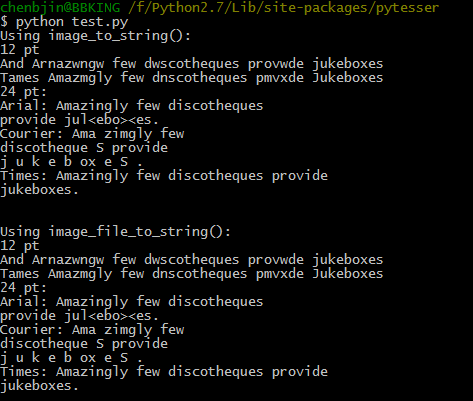
由于在中文识别方面还有很多问题,以后再进一步研究分享。
参考:HK_JH的专栏 http://blog.csdn.net/hk_jh/article/details/8961449