APQ
2020-CVPR-APQ Joint Search for Network Architecture Pruning and Quantization Policy
来源:ChenBong 博客园
- Institute:SJTU,MIT
- Author:Tianzhe Wang,Han Song
- GitHub:https://github.com/mit-han-lab/apq 60+
- Citation:9+
Introduction
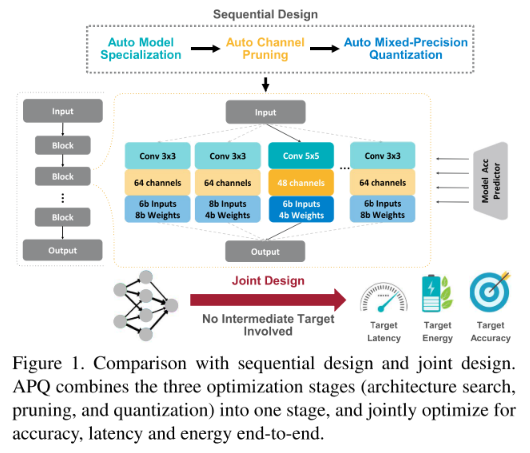
端到端的结构搜索,通道剪枝,混合精度量化 联合优化。
pipeline:
Motivation
模型的部署分为 模型结构设计(Architecture),剪枝(Pruning),量化(Quantization)三个步骤。
这三步的pipeline可以显著减少模型开销,但当同时考虑这三个优化目标时,待优化的参数/时间开销会急剧增加;且三个步骤单独搜索可能会导致最终的结果陷入局部最优(如,全精度下最佳的结构,可能并不适合量化)。
因此我们提出一种将 结构搜索,剪枝,量化三个步骤联合进行端到端的搜索的方法。
Contribution
- 将3个步骤整合为1个端到端的搜索方案
- 提出了使用 量化感知精度预测器(quantization-aware accuracy predictor),直接根据训练好的全精度网络结构,权重,以及混合量化的方案,直接预测量化后的精度
- 对 量化感知精度预测器 采用先在全精度网络数据集 <Arch,Acc> 上训练,再迁移到量化网络数据集 <Quantization Arch,Quantization Acc> 上训练的 predictor-transfer 方法
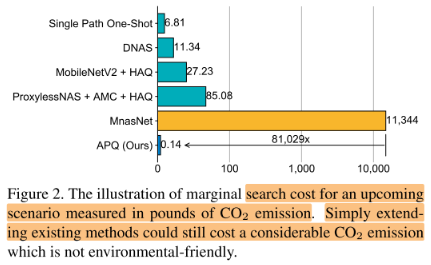
- 整个搜索方案开销小
Method
Pipeline
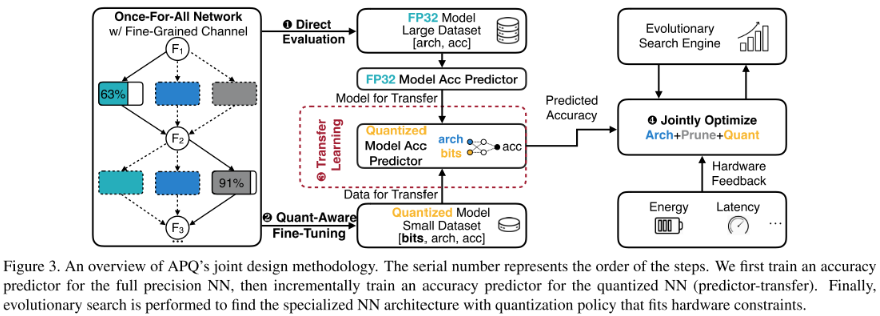
- 将通道搜索(剪枝)结合到 结构搜索(NAS)的步骤中
- 搜索空间:模型结构空间(包括通道结构)+ 混合精度量化策略空间
- 指标:量化网络精度
- 现在pipeline变为:
- 模型结构空间 => 全精度网络结构 (=> 全精度网络精度)
- 全精度网络结构 => 施加混合精度量化策略 => 量化网络结构 => 预测器预测 => 量化网络精度
- 其中的预测器是一个全连接网络(3 layer FC)
- 问题:训练 预测器 需要大量的数据对 <量化网络结构,量化网络精度>,但获得这些数据对是很耗时的:
- 训练全精度的网络,获得全精度网络的数据对:<Arch,Acc>
- 对训练后的全精度网络采用某种混合量化方案后,fine-tune,得到。
- 解决:
- 对于第 1 点,我们使用nas中supernet的思想,训练一个supernet,从supernet中采样subnet直接eval,可以直接得到很多全精度网络的数据对:<全精度网络结构,全精度网络精度>
- 对于第 2 点,采用 transfer 的思想,先在大量全精度网络的数据对(容易获得:直接采样subnet,eval)上训练,再在少量的量化网络的数据对上fine-tune
Once-For-All Network with Fine-grained Channel Pruning
这个阶段主要任务就是训练supernet:
使用mobilenet v2 的block作为基本blcok(conv 1×1 => dw conv 3×3 => conv 1×1)
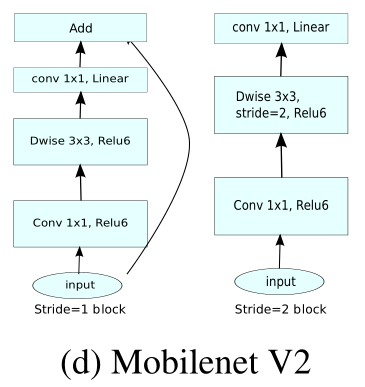
block的结构空间:
- (dw conv) kernel size:3, 5, 7
- channel num:16, 24, 32, 40
使用 one-hot vector 进行编码,例如某一 dw conv 的 kernel size=3(1,0,0),channel num=32(0,0,1,0)
则该 block 的结构编码为(1,0,0, 0,0,1,0)
Quantization-Aware Accuracy Predictor
block的混合精度量化策略空间:
- weight bit:4, 8
- activation bit:4, 8
使用 one-hot vector 进行编码,例如某一 block 的4个layer 的 weight bit=(8,4,4,8),activation bit=(4,8,8,4)
则该blcok的 Quantization policy 编码为(1,0,0,1,0,1,1,0)
则该block的总结构编码为:(1,0,0, 0,0,1,0, 1,0,0,1, 0,1,1,0)
Architecture and Quantization Policy Encoding
若一个网络有5个blcok,则整个网络编码长度为75-dim: (5×(3+4+2×4)=75)
Transfer Predictor to Quantized Models
Predictor 的迁移学习:先在大量 全精度网络数据对 上学习,再少量 量化网络数据对 上学习:
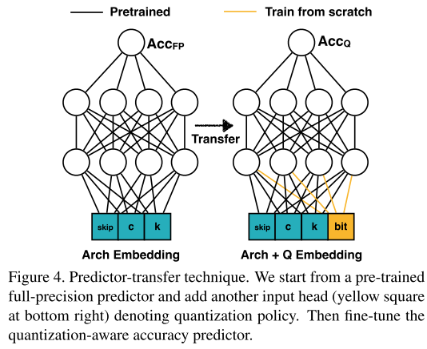
Data Preparation for Quantization-aware Accuracy Predictor
全精度网络数据对:
The number of data to train a full precision predictor is 80,000.
量化网络数据对:
We generate two kinds of data (2,500 for each):
- random sample both architecture and quantization policy;
- random sample architecture, and sample 10 quantization policies for each architecture configuration.
We mix the data (5000 total) for training the quantization-aware accuracy predictor, and use full-precision pretrained predictor’s weights to transfer.
Hardware-Aware Evolutionary Search
Measuring Latency and Energy
根据不同类型的网络层,在目标机器上的(延时,能耗),构造查找表,之后就可以根据量化网络结构,直接估计其(延时,能耗)
Resource-Constrained Evolution Search
使用进化算法,对不符合(延时,能耗)目标的后代进行淘汰。
Experiments

Effectiveness of Joint Design
Comparison with MobileNetV2+HAQ
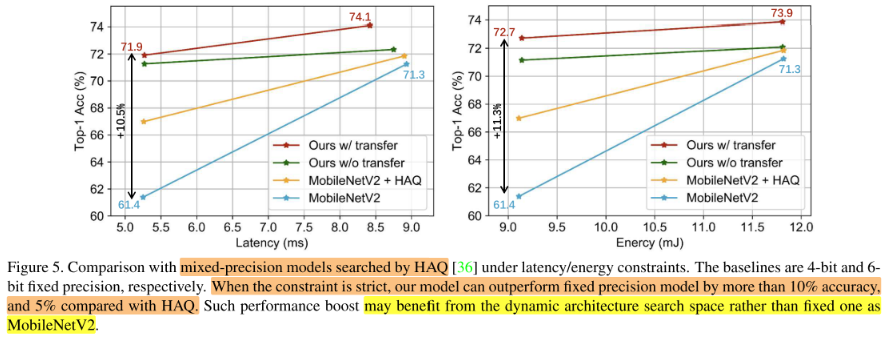
Comparison with Multi-Stage Optimized Model.
Comparison under Limited BitOps
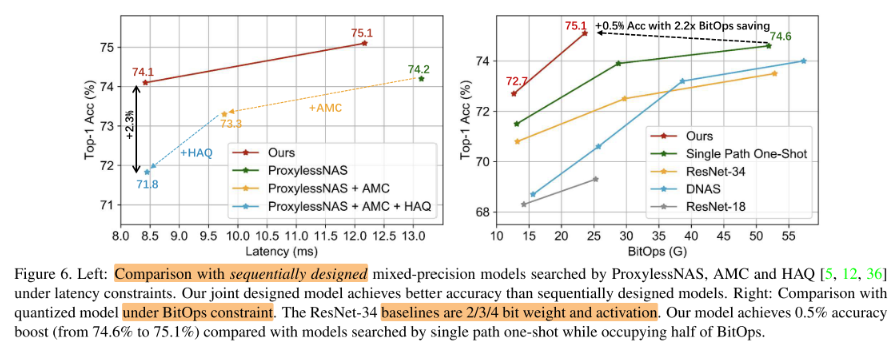
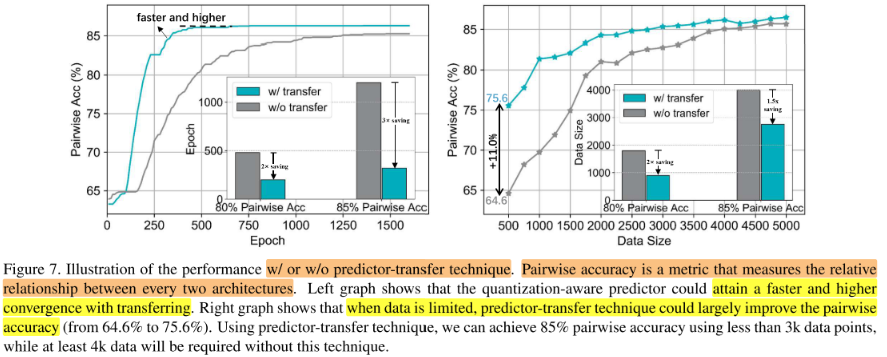
Effectiveness of Predictor-Transfer