今天辰哥带大家来看看一个爬虫框架:Feapder,看完本文之后,别再说你不会Feapder了。本文辰哥将带你了解什么是Feapder?、如何去创建一个Feapder入门项目(实战:采集易车网轿车数据)。
其中实战部分包括爬虫数据和存储到Mysql数据库,让大家能够感受一下,数据从网页经框架Feapder采集后,直接存储到数据库的过程。
之前我们已经用了Scrapy爬虫框架来爬取数据(以『B站』为实战案例!手把手教你掌握爬虫必备框架『Scrapy』),今天来试试使用Feapder写爬虫是一种怎么样的体验,请往下看!!!!!
01、Feapder框架
1.Feapder框架介绍
Feapder 是一款上手简单、功能强大、快速、轻量级的爬虫框架的Python爬虫框架。支持轻量爬虫、分布式爬虫、批次爬虫、爬虫集成,以及完善的爬虫报警机制。
具体feapder项目结构每一块的功能是什么?怎么样用?接着往下看,下面的实战中有详细的讲解。
2.Feapder的安装
feapder的安装很简单,通过下面的命令安装即可!
pip install feapder
出现下面的界面说明feapder成功安装!

feapder的介绍和环境安装就完成了,下面开始真正去使用fepader来爬取易车网数据,并存储到mysql数据库。
02、实战
1.新建feapder项目
通过下方的命令去创建一个名为:chenge_yc_spider的的爬虫项目
feapder create -p chenge_yc_spider

创建好之后,我们看一下项目结构

2.编写爬虫
在终端中进入到项目(chenge_yc_spider)下的spiders文件夹下,通过下面的命令创建一个目标爬虫文件(target_spider)
feapder create -s target_spider

此刻项目结构如下:

编辑target_spider.py文件
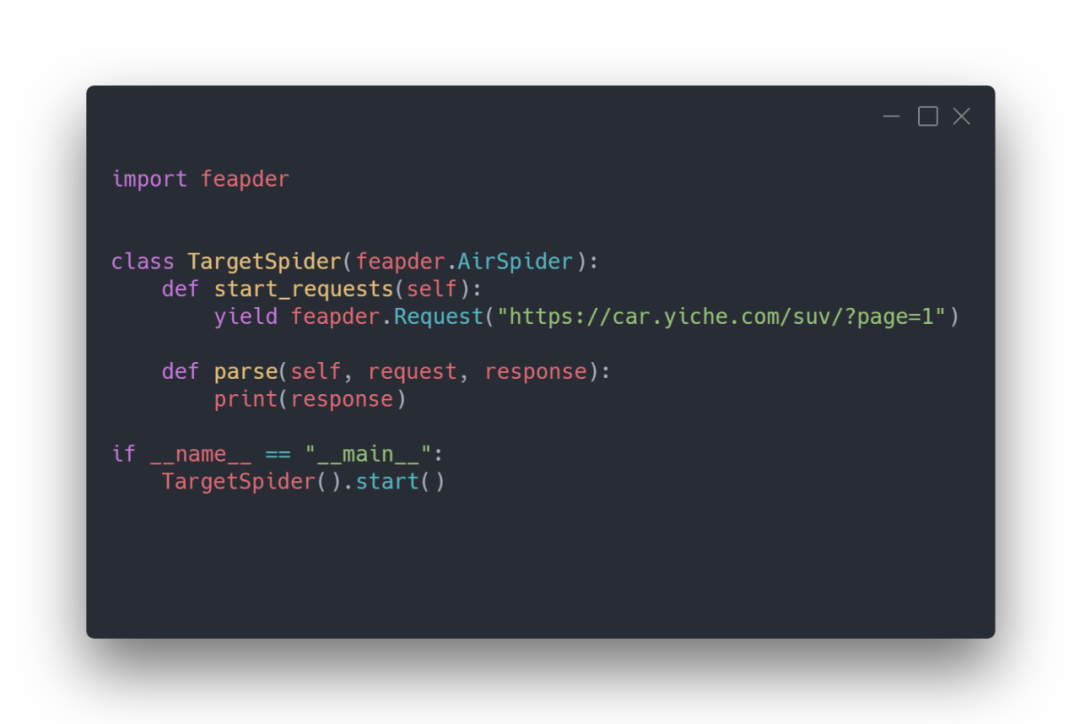
这里实战案例:采集易车网数据。直接执行这个py文件,先看一下请求有没有没问题。
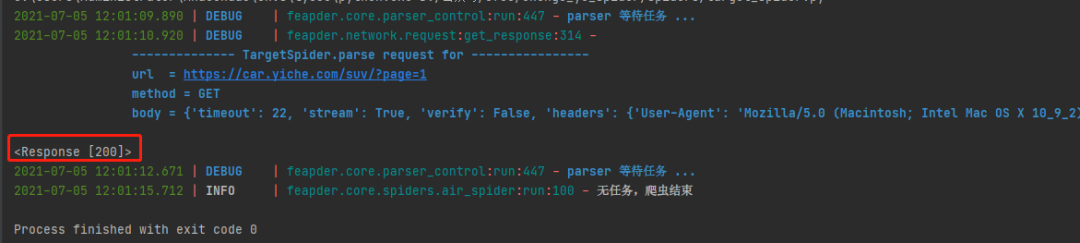
可以看到请求返回响应200,说明请求成功。下一步我们开始解析网页数据并设置爬虫框架自动采集下一页数据。
3.解析网页
网页结果(待采集的数据)如下:

通过查看源代码,分析数据所对应的网页标签
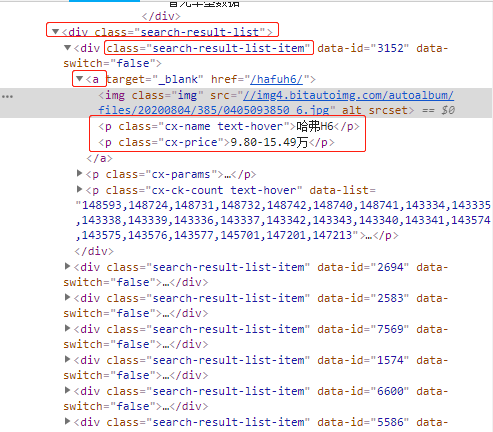
通过网页源码可以分析,汽车列表数据都是在class为search-result-list下。每一个class为search-result-list-item表示一条数据,每一条数据下都有汽车对应的属性(如:汽车名称、价格等)
这里仅作为实战案例去学习feapder爬虫框架,因此这里就只爬取汽车名称、价格;这两个字段属性。
4.创建Mysql数据库
采集的数据需要存储到数据库(mysql)中,因此我们先来定义好数据库和表
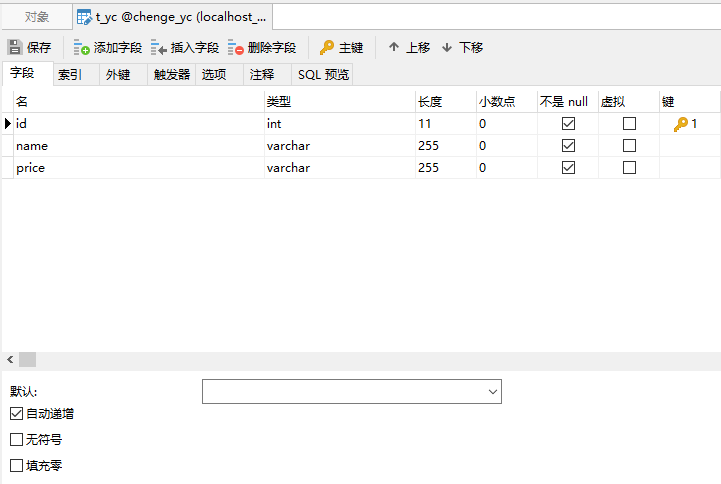
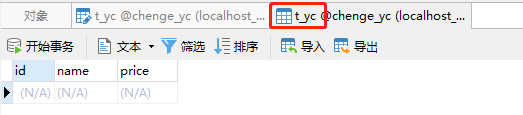
这里辰哥创建了一个数据库:chenge_yc,并在里面建了应该表:t_yc,其表结构如上图,这里如果不不熟悉mysql如何建立数据库表的可以参考辰哥的这篇文章(实战|教你用Python玩转Mysql)
在爬虫项目中配置数据库,打开根目录下的setting.py文件
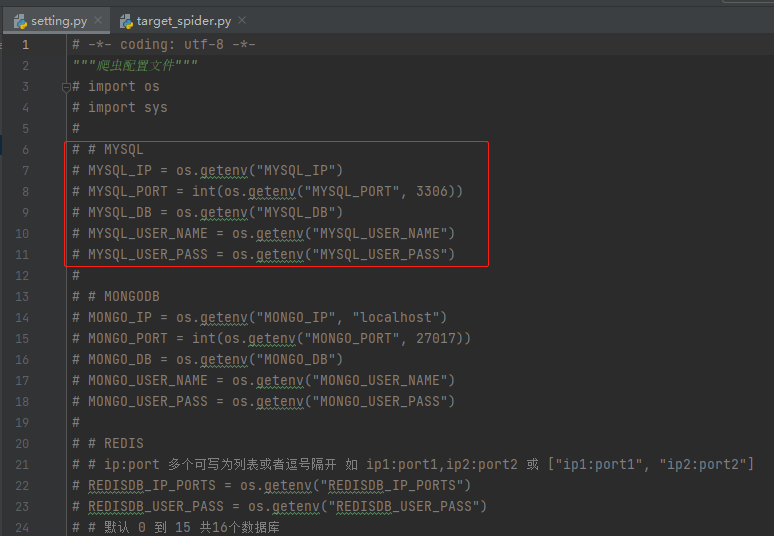
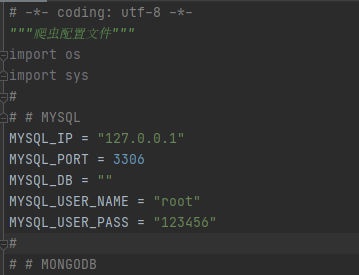
可以看到feapder支持多种数据库的对接,咱们这里使用的是mysql,其配置如下:
接着在终端下,进入到根目录下的items文件夹,执行下面命令生成数据库表对于的item
feapder create -i t_yc

请注意:命令中的t_yc是对于数据库表中的t_yc
最后生成 t_yc_item.py 文件:
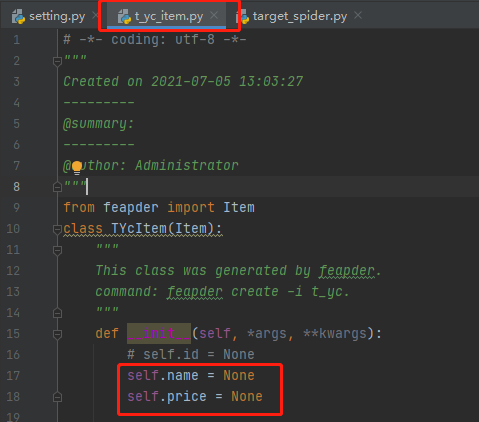
里面的name和price则是对应数据库中的字段。
5.提取网页字段
上面已经获取到网页源码,也知道数据所在的标签,现在开始编写代码进行解析。

执行结果:

可以看到数据已经成功提出来,下一步将这些数据存储到数据库中。
6.存储到数据库
import feapder
引入刚刚的 t_yc_item.py,并创建对象TycItem。把爬取的name和price初始化到对象中。最后yieId TycItem,实际上就直接存储到数据库了(因为数据库表和item是对应连接关系,这样就直接存储到数据库了)。
这太方便了,连sql语句都省了,6666666666
执行结果如下:

查看数据库:
同样可以看到数据直接就存储到数据库中。大功告成!!!!!!
03、小结
相信看到这里的你已经完完全全掌握了 爬虫框架: Feapder ,你不仅知道了什么是feapder,同时还学会了如何使用feapder。
此外实战部分包括 爬虫数据和存储到Mysql数据库,让大家能够感受一下,数据从网页经框架Feapder采集后,直接存储到数据库的过程。
一定要 动手尝试 ! 一定要 动手尝试 ! 一定要 动手尝试!