| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/zswxy/computer-science-class3-2018/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/computer-science-class3-2018/homework/11879 |
| 这个作业的目标 | 学习使用gitee |
| 学号 | 20188472 |
| 其他参考文献 | 《构建之法》 |
1.gitee地址
https://gitee.com/HazelnutC/project-java
https://gitee.com/HazelnutC/project-java/tree/master/
2.代码规范链接
https://gitee.com/HazelnutC/project-java/blob/master/20188472/代码规范.TXT
3.设计与实现过程
整个程序除了WordCount类,有两个类,类名分别为Lib和Frequency。将除了统计词频的所有功能写入Lib.java文件,统计词频功能写入Frequency.java文件,WordCount类只要写一个主函数调用即可。
Lib类有三个函数,分别统计字符数量、单词数量、有效行数:
public class Lib {
//统计字符数量
//传入参数:文件名
//返回值:字符数量
public static int numOfChar(String filename);
//统计单词数量
//传入参数:文件名
//返回值:单词数量
public static int numOfWord(String filename) ;
//统计有效行数
//传入参数:文件名
//返回值:有效行数
public static int numOfLine(String filename);
}
Frequency类主要是统计词频功能,包含两个函数。一个是构造函数,用于将读入的数据分成一个一个单词,然后压入map集合;另一个为结果函数,主要用来排序并保存。还有几个函数要用到的类变量:
public class Frequency {
//指定文件路径和文件名
private static String path;
//定义一个结果集字符串
public static String result = "";
//定义一个map集合保存单词和单词出现的个数
private TreeMap<String,Integer> tm;
public Frequency(String path);
public static String saveResult(Map<String,Integer> map);
}
3.1 统计文件的字符数
读入文件之后,逐个字符扫描,直到文件结束为止,即可:
readFile = new InputStreamReader(new FileInputStream(file),"UTF-8");
int tempChar;
while ((tempChar=readFile.read()) != -1) {
count++;
}
readFile.close();
3.2 统计文件的单词总数
一开始的想法是硬编码,引入一个标志位(初始值为false),表示当前是不是一个单词。
读入第一个字符,判断是不是字母,如果是,标志位置为true;之后如果遇到数字,判断是不是在前四个,如果是,标志位置为false。直到遇到下一个分隔符才统计单词数量。
for (int i = 0; (tempchar=readFile.read()) != -1; ) {
char ch = (char)tempchar;
//是字母
if (ch >= 'A' && ch <= 'Z' || ch >= 'a' && ch <='z'){
i++;
flag = true;
}
//是数字,判断是不是在第五个及之后出现
else if (ch >= '0' && ch <= '9'){
i++;
if (i < 5) {
i = 0;
flag = false;
}
}
//分割符情况
else {
if (i >= 4 && flag == true) countWord++;
flag = false;
i = 0;
}
}
后面发现似乎可以和后面的“统计文件中各单词的出现次数”用同样思路(利用正则表达式判断),并且上面的程序段有bug,因为最后一行末尾可能没有分隔符,故修改:
//读入文件、变量声明省略
bufferedReadFile = new BufferedReader(new FileReader(file));
while ((tempString = bufferedReadFile.readLine()) != null){
tempString = tempString.toLowerCase();
String reg1 = "[^a-zA-Z0-9]+";
String reg2 ="[a-z]{4}[a-z0-9]*";
//将读取的文本进行分割
String[] str = tempString.split(reg1);
for (String s: str){
if (s.matches(reg2)){
countWord++;
}
}
}
3.3 统计文件的有效行数
读入文件之后,逐行扫描,去除空白字符,若该行一个字符都没有,则代表一行空白(也即是无效行):
bufferedReadFile = new BufferedReader(new FileReader(file));
String tempString;
while ((tempString = bufferedReadFile.readLine()) != null){
countSum++;
//去掉空白字符
tempString=tempString.replace("f","");
tempString=tempString.replace("","");
tempString=tempString.replace("
","");
tempString=tempString.replace(" ","");
tempString=tempString.replace("
","");
tempString=tempString.replace(" ","");
if (tempString.equals("")) {
countNull++;
}
}
二者相减即是文件的有效行数。
3.4 统计文件中各单词的出现次数
此功能比较复杂,函数体也比较大,和前三个功能混子一起似乎不是很合适。考虑用一个类进行封装,类名为Frequency。
过程大致是:获取文件;利用正则表达式分割文本;先判断集合中是否已经存在该单词再压入集合;最后进行排序。
除了最后的排序,剩下的功能全部写入同一函数,部分代码如下:
while ((tempString=bufferedReadFile.readLine())!=null){
tempString = tempString.toLowerCase();
String reg1 = "[^a-zA-Z0-9]";
String reg2 ="[a-z]{4}[a-z0-9]*";
//将读取的文本进行分割
String[] str = tempString.split(reg1);
for (String s: str){
if (s.matches(reg2)){
//判断集合中是否已经存在该单词,如果存在则个数加1,否则将单词添加到集合中,且个数置为1
if (!tm.containsKey(s)){
tm.put(s,1);
}
else {
tm.put(s,tm.get(s)+1);
}
}
}
}
//...
排序过程:将Map类型转换成的List,利用Map.Entry输出map键值对,并且获取list列表中存放的数据。还需要自定义比较器实现降序排序:
public static void printResult(Map<String,Integer> map) {
List<Map.Entry<String,Integer>> list = new ArrayList<Map.Entry<String,Integer>>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return (o2.getValue().compareTo(o1.getValue()) ); //降序排序,当o2小于、等于、大于o1时,返回-1,0,1
}
});
int num = list.size();
//System.out.println(num);
for (int i = 0; i < num && i < 10; i++) {
Map.Entry<String,Integer> entry = list.get(i);
//输出...
}
}
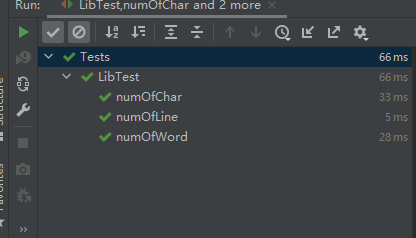
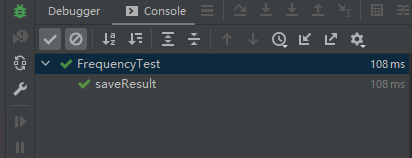
4.单元测试
测试结果如下:
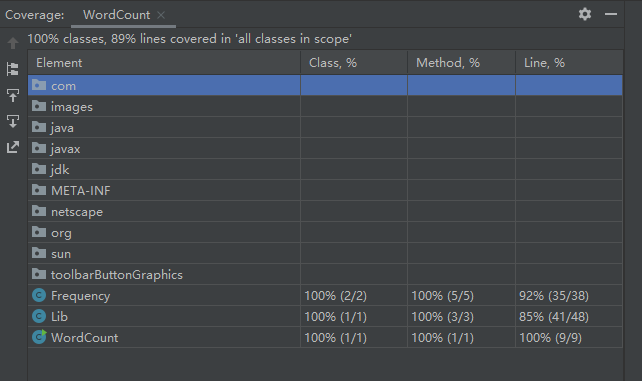
代码覆盖率:
5.异常处理说明
当且仅当文件不存在时会抛出异常。
try {
//读文件
//处理文件
}
catch (Exception e){
System.err.println("文件不存在");
}
利用不存在的文件名进行测试。
5.psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| Estimate | 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 1000 | 1200 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 150 |
| Design Spec | 生成设计文档 | 90 | 60 |
| Design Review | 设计复审 | 40 | 50 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| Design | 具体设计 | 70 | 60 |
| Coding | 具体编码 | 300 | 600 |
| Code Review | 代码复审 | 10 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 50 | 60 |
| Reporting | 报告 | 10 | 20 |
| Test Repor | 测试报告 | 30 | 50 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 15 |
| 合计 | 1760 | 2395 |
心路历程与收获
这次作业感觉挺难的,主要是在之前没有使用github或者gitee的习惯,导致从根本不会fork、commit和pull request,加上github这玩意老是抽风,登不上去(之前看本班的同学都没用github,所以准备装个b,结果github不给力啊),所以浪费了不少时间在研究github上,到头来还是得用gitee。有些作业要求没看清楚就开始写,导致经常性修改,比如代码规范制定,写代码的时候意外发现不合要求,只能花更多时间修改。