作业①
1)熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
代码部分
booksspider.py
import scrapy
from ..items import BooksproItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class BooksspiderSpider(scrapy.Spider):
name = 'booksspider'
#allowed_domains = ['www.xxx.com']
key = 'python'
source_url = "http://search.dangdang.com/"
def start_requests(self):
url = BooksspiderSpider.source_url + "?key=" + BooksspiderSpider.key #拼接得到带有搜索关键词的url
yield scrapy.Request(url = url , callback=self.parse) #回调请求,用的都是同一个parse方法
def parse(self, response):
try:
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
#li_list = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
li_list = selector.xpath("//*[@id='component_59']/li") #先以ul的id值定位到相应的ul,再定位下面的li标签即可
for li in li_list:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()= last()-1]/text()").extract_first()
publisher = li.xpath(
"./p[@class='search_book_author']/span [position()=last()]/a/@title").extract_first()
#有的detail值为空
detail = li.xpath("./p[@class='detail']/text()").extract_first()
item = BooksproItem()
item['title'] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
# link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
# if link:
# url = response.urljoin(link)
# yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
items.py
import scrapy
class BooksproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
pass
settings.py
BOT_NAME = 'booksPro'
SPIDER_MODULES = ['booksPro.spiders']
NEWSPIDER_MODULE = 'booksPro.spiders'
LOG_LEVEL = 'ERROR' #这样设置就可以只看到提示错误的日志信息了
USER_AGENT = 'Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre' #UA伪装
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'booksPro (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'booksPro.pipelines.BooksproPipeline': 300,
}
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class BooksproPipeline(object):
def open_spider(self,spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="chu836083241",db="test",charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
#self.cursor.execute("detele from books")
self.opened = True
self.count = 1
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取",self.count,"本书籍")
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute(
"insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values(%s,%s,%s,%s,%s,%s)",
(item["title"], item["author"], item["publisher"], item["date"], item["price"], item["detail"]))
self.count+=1
except Exception as err:
print('err')
return item
结果如下

2)心得体会
本次实验主要是对书上代码的复现,本次实验后我能够更加熟练地使用Scrapy框架,并且明白了通过python中的语句来操作mysql中的表格,要注意mysql中设置表格的列名要和python语句中的一致,还有就是通过使用xpath来解析数据,确实非常灵活。
作业②
1)熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
代码部分
stockspider.py
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from ..items import StockItem
class StockspiderSpider(scrapy.Spider):
name = 'stockspider'
#allowed_domains = ['www.xxx.com']
start_urls = ['http://quote.eastmoney.com/center/gridlist.html#hs_a_board']
def __init__(self): #只需要执行一次
self.chrome_options = Options()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu') #设置启动chrome时不可见
self.driver = webdriver.Chrome(chrome_options=self.chrome_options)
def parse(self, response):
tr_list = response.xpath('//*[@id="table_wrapper-table"]/tbody/tr')
for tr in tr_list:
Id = tr.xpath('./td[1]/text()').extract_first().strip()
code = tr.xpath('./td[2]/a/text()').extract_first().strip()
name = tr.xpath('./td[3]/a/text()').extract_first().strip()
new_price = tr.xpath('./td[5]/span/text()').extract_first().strip()
zhangdiefu = tr.xpath('./td[6]/span/text()').extract_first().strip()
zhangdiee = tr.xpath('./td[7]/span/text()').extract_first().strip()
# print(Id,code,name,new_price,zhangdiefu,zhangdiee)
item = StockItem()
item['Id'] = Id
item['code'] = code
item['name'] = name
item['new_price'] = new_price
item['zhangdiefu'] = zhangdiefu
item['zhangdiee'] = zhangdiee
yield item
def closed(self,spider): #只要执行一次就行,关闭浏览器驱动程序
self.driver.quit()
settings.py
# Obey robots.txt rules
USER_AGENT = 'Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre' #UA伪装
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
DOWNLOADER_MIDDLEWARES = { #开启下载中间件
'stock.middlewares.StockDownloaderMiddleware': 543,
}
ITEM_PIPELINES = { #开启管道
'stock.pipelines.StockPipeline': 300,
}
pipelines.py
from itemadapter import ItemAdapter
import pymysql
class StockPipeline:
def open_spider(self,spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="chu836083241",db="test",charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
#self.cursor.execute("detele from books")
self.opened = True
self.count = 1
except Exception as err:
print(err)
self.opened = False
def process_item(self, item, spider):
try:
print(item['Id'])
print(item['code'])
print(item['name'])
print(item['new_price'])
print(item['zhangdiefu'])
print(item['zhangdiee'])
if self.opened:
self.cursor.execute(
"insert into stock (Id,code,name,new_price,zhangdiefu,zhangdiee) values(%s,%s,%s,%s,%s,%s)",
(item['Id'], item['code'], item['name'], item['new_price'], item['zhangdiefu'], item['zhangdiee']))
self.count+=1
except Exception as err:
print('err')
return item
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取",self.count-1,"条记录")
这次的不同就是要多写一个py文件,主要改动的是里面的process_response方法,要对我们的响应对象进行拦截与修改,得到页面的源码数据,方便我们在stockspider.py中得到新的响应对象,直接用xpath进行解析。
middlewares.py
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
#挑选指定的响应对象进行篡改
#通过url指定request
#通过request指定response
#spider爬虫对象
bro = spider.driver
if request.url in spider.start_urls:
#response # 进行篡改 实例化新的响应对象(包含动态加载的新闻数据)替代原来的旧响应对象
# 基于seleium便捷获取动态数据
bro.get(request.url)
sleep(3)
page_text = bro.page_source
new_response = HtmlResponse(url =request.url,body = page_text,encoding = 'utf-8',request=request)
return new_response
else:
return response
结果展示
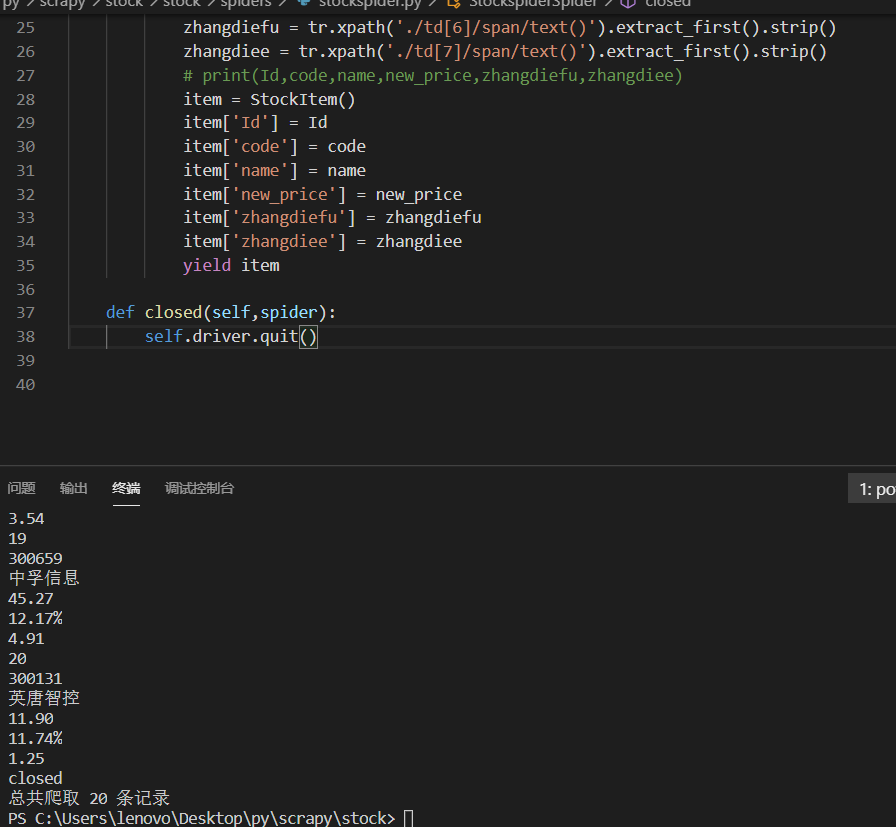

2)心得体会
本次实验将selenium和scrapy结合起来,我了解到scrapy中下载中间件的作用。本次实验主要是要写process_response方法,通过篡改响应对象,直接解析页面的源代码,这样就可以使用xpath来进行数据解析了,不过由于时间比较紧张,还没实现翻页操作,之后自己会尝试实现一下(通过xpath来定位到下一页按钮,再结合click()方法实现翻页)。另外也了解了下载中间件中也能篡改请求对象,例如设置UA池、IP代理等。本次实验后,我对scrapy框架有了更深入的了解,收获颇丰。
作业③
1)熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
代码部分
myspider.py
import scrapy
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
from ..items import CurrencyItem
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
#allowed_domains = ['www.xxx.com']
start_url = 'http://fx.cmbchina.com/hq/'
def start_requests(self):
url = MyspiderSpider.start_url
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
#原先用table/tbody/tr来定位,但是加了tbody就定位不到了
tr_list = selector.xpath('//*[@id="realRateInfo"]/table//tr')
self.index = 0
for tr in tr_list:
if(self.index == 0):
self.index += 1
continue
else:
item = CurrencyItem()
Currency = tr.xpath('./td[1]/text()').extract_first().strip()
TSP = tr.xpath('./td[4]/text()').extract_first().strip()
CSP = tr.xpath('./td[5]/text()').extract_first().strip()
TBP = tr.xpath('./td[6]/text()').extract_first().strip()
CBP = tr.xpath('./td[7]/text()').extract_first().strip()
Time = tr.xpath('./td[8]/text()').extract_first().strip()
item['Currency'] = Currency
item['TSP'] = TSP
item['CSP'] = CSP
item['TBP'] = TBP
item['CBP'] = CBP
item['Time'] = Time
yield item
items.py
import scrapy
class CurrencyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
pass
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class CurrencyPipeline(object):
def open_spider(self,spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="chu836083241",db="test",charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
#self.cursor.execute("detele from books")
self.opened = True
self.count = 1
except Exception as err:
print(err)
self.opened = False
def process_item(self, item, spider):
try:
print(self.count)
print(item['Currency'])
print(item['TSP'])
print(item['CSP'])
print(item['TBP'])
print(item['CBP'])
print(item['Time'])
if self.opened:
self.cursor.execute(
"insert into currency (Id,Currency,TSP,CSP,TBP,CBP,Time) values(%s,%s,%s,%s,%s,%s,%s)",
(self.count,item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"]))
self.count+=1
except Exception as err:
print('err')
return item
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取",self.count-1,"条记录")
结果展示
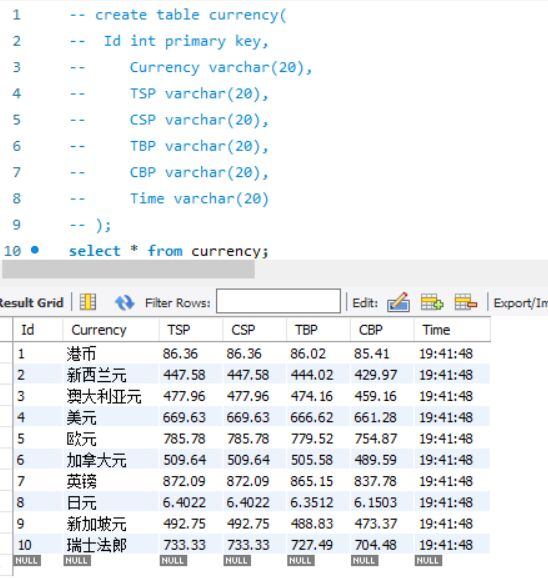
2)心得体会
本次实验的页面源码数据并非动态加载的,所以难度不是很大,不过有个坑点就是在xpath中用了tbody标签来定位,结果返回值是空的,但是在第二题中却没出现这种情况。这个疑惑暂时还没解决。