Tensorflow监控指标可视化




参考文献
强烈推荐Tensorflow实战Google深度学习框架
实验平台:
Tensorflow1.4.0
python3.5.0
MNIST数据集将四个文件下载后放到当前目录下的MNIST_data文件夹下
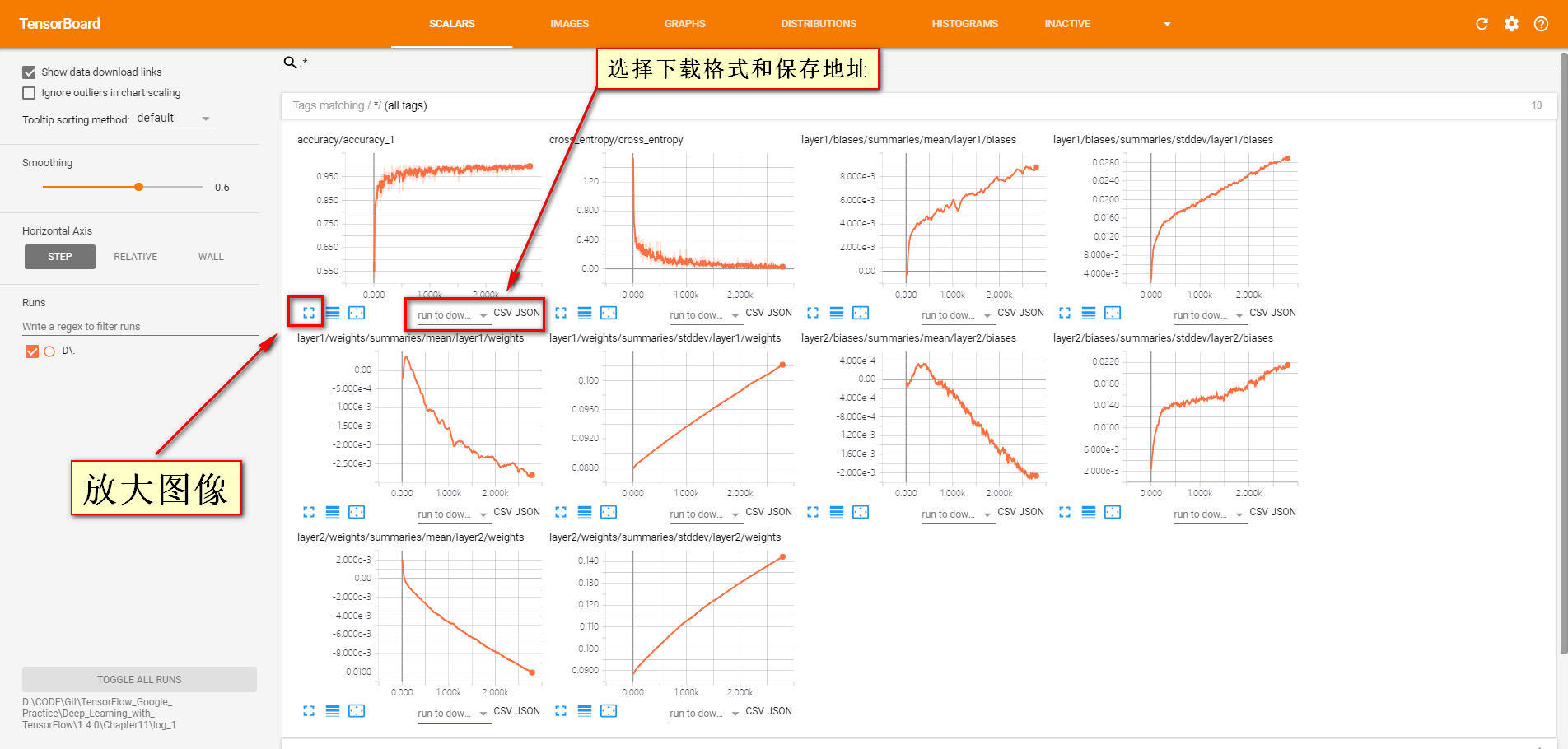
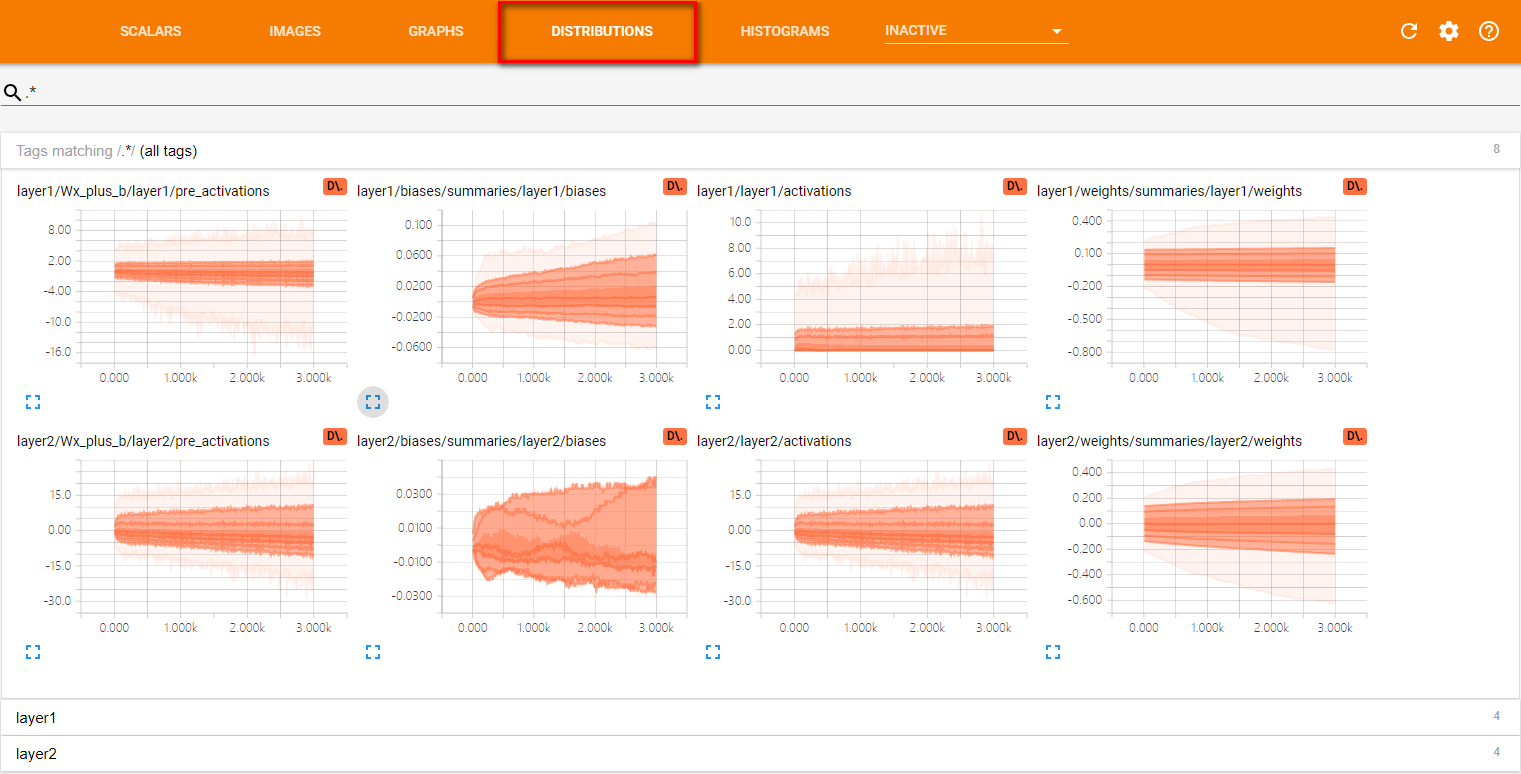
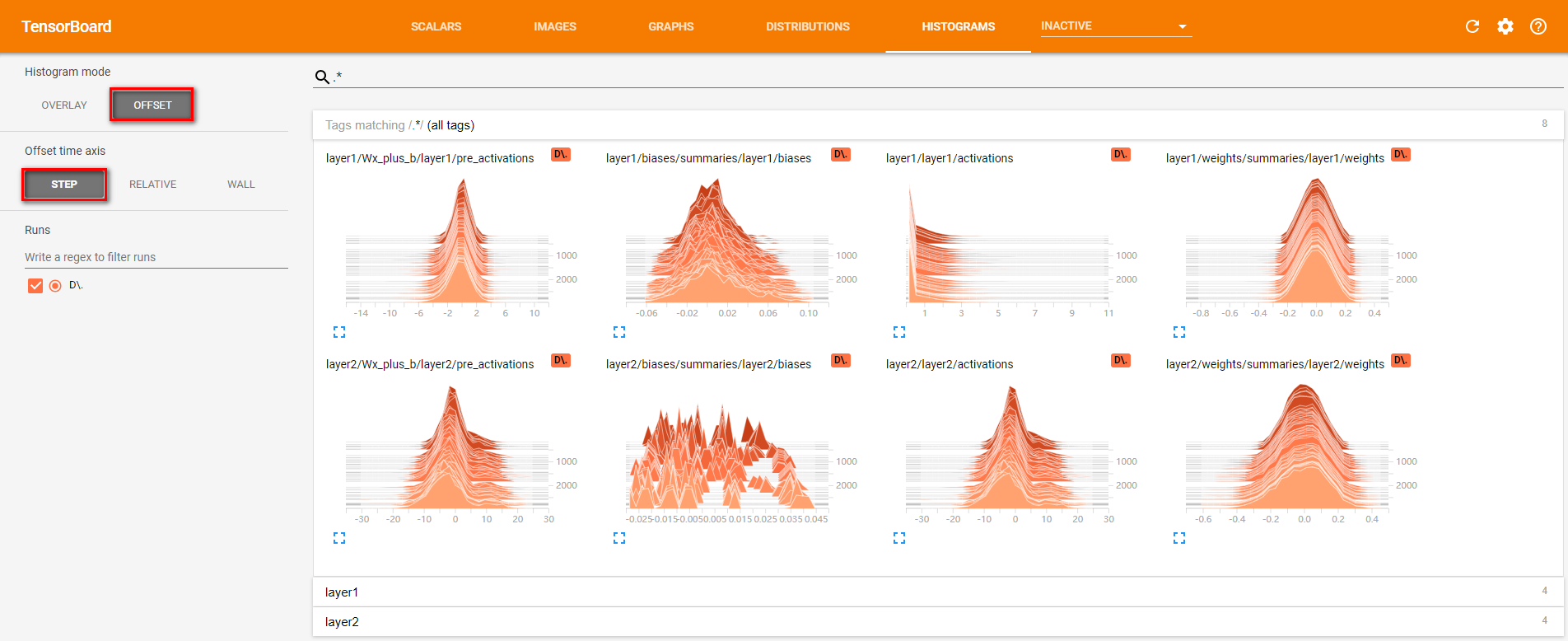
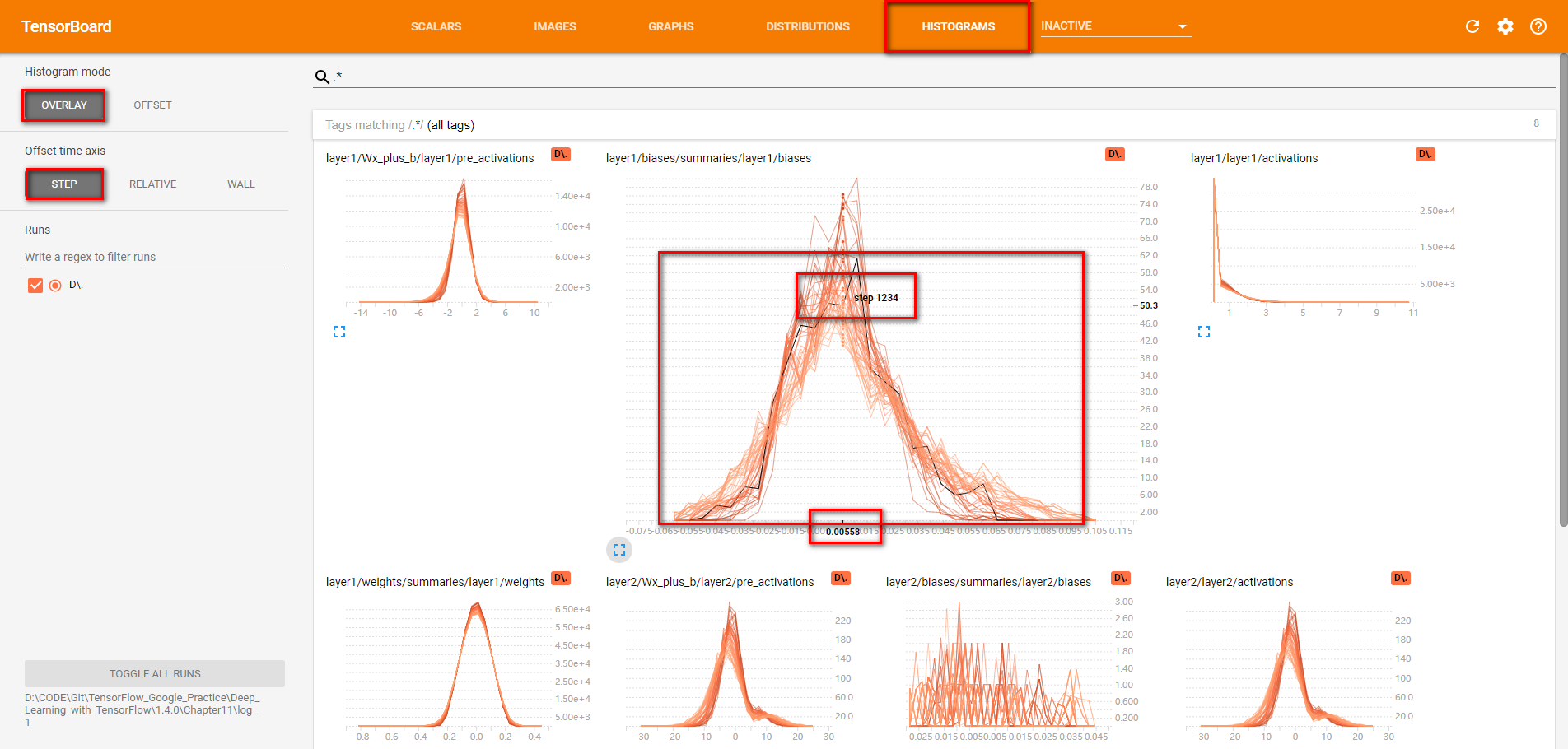
- Tensorflow命名空间与计算图可视化介绍了通过TensorBoard的GRAPHS可视化TensorFlow计算图的结构以及在计算图上的信息。TensorBoard 除了可以可视化TensorFlow 的计算图,还可以可视化TensorFlow 程序运行过程中各种有助于了解程序运行状态的监控指标。在本节中将介绍如何利用TensorBoard 中其他栏目可视化这些监控指标。除了GRAPHS以外,TensorBoard界面中还提供了SCALARS(标量),IMAGESAUDIO(图片),DISTRIBUTIONS(统计分布)HISTOGRAMS(直方图统计分布)和TEXT(文本)六个界面来可视化其他的监控指标。以下程序展示了如何将TensorFlow程序运行时的信息输出到TensorBoard 日志文件中。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import tqdm
# #### 1. 生成变量监控信息并定义生成监控信息日志的操作。
SUMMARY_DIR = "log_1"
BATCH_SIZE = 100
TRAIN_STEPS = 3000
# var给出了需要记录的张量,name给出了在可视化结果中显示的图表名称,这个名称一般和变量名一致
def variable_summaries(var, name):
# 将生成监控信息的操作放在同一个命名空间下
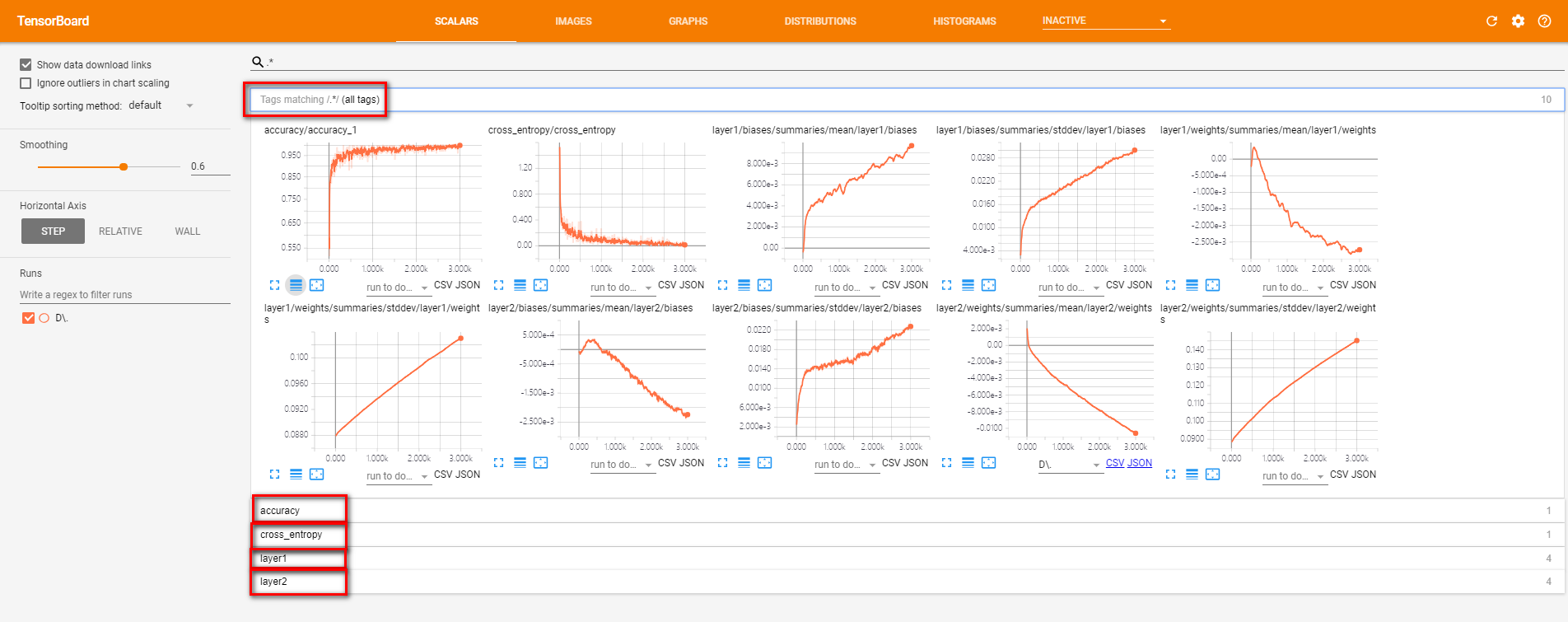
with tf.name_scope('summaries'):
# 通过tf.histogram_summary函数记录张量中元素的取值分布
# tf.summary.histogram函数会生成一个Summary protocol buffer.
# 将Summary 写入TensorBoard 门志文件后,在HISTOGRAMS 栏,和
# DISTRIBUTION 栏下都会出现对应名称的图表。和TensorFlow 中其他操作类似,
# tf.summary.histogram 函数不会立刻被执行,只有当sess.run 函数明确调用这个操作时, TensorFlow
# 才会具正生成并输出Summary protocol buffer.
tf.summary.histogram(name, var)
# 计算变量的平均值,并定义生成平均值信息日志的操作,记录变量平均值信息的日志标签名
# 为'mean/'+name,其中mean为命名空间,/是命名空间的分隔符
# 在相同命名空间中的监控指标会被整合到同一栏中,name则给出了当前监控指标属于哪一个变量
mean = tf.reduce_mean(var)
tf.summary.scalar('mean/' + name, mean)
# 计算变量的标准差,并定义生成其日志文件的操作
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev/' + name, stddev)
# #### 2. 生成一层全链接的神经网络。
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
# 将同一层神经网络放在一个统一的命名空间下
with tf.name_scope(layer_name):
# 声明神经网络边上的权值,并调用权重监控信息日志的函数
with tf.name_scope('weights'):
weights = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1))
variable_summaries(weights, layer_name + '/weights')
# 声明神经网络边上的偏置,并调用偏置监控信息日志的函数
with tf.name_scope('biases'):
biases = tf.Variable(tf.constant(0.0, shape=[output_dim]))
variable_summaries(biases, layer_name + '/biases')
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
# 记录神经网络节点输出在经过激活函数之前的分布
tf.summary.histogram(layer_name + '/pre_activations', preactivate)
activations = act(preactivate, name='activation')
# 记录神经网络节点输出在经过激活函数之后的分布。
"""
对于layerl ,因为使用了ReLU函数作为激活函数,所以所有小于0的值部被设为了0。于是在激活后
的layerl/activations 图上所有的值都是大于0的。而对于layer2 ,因为没有使用激活函数,
所以layer2/activations 和layer2/pre_activations 一样。
"""
tf.summary.histogram(layer_name + '/activations', activations)
return activations
def main():
mnist = input_data.read_data_sets("./datasets/MNIST_data", one_hot=True)
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
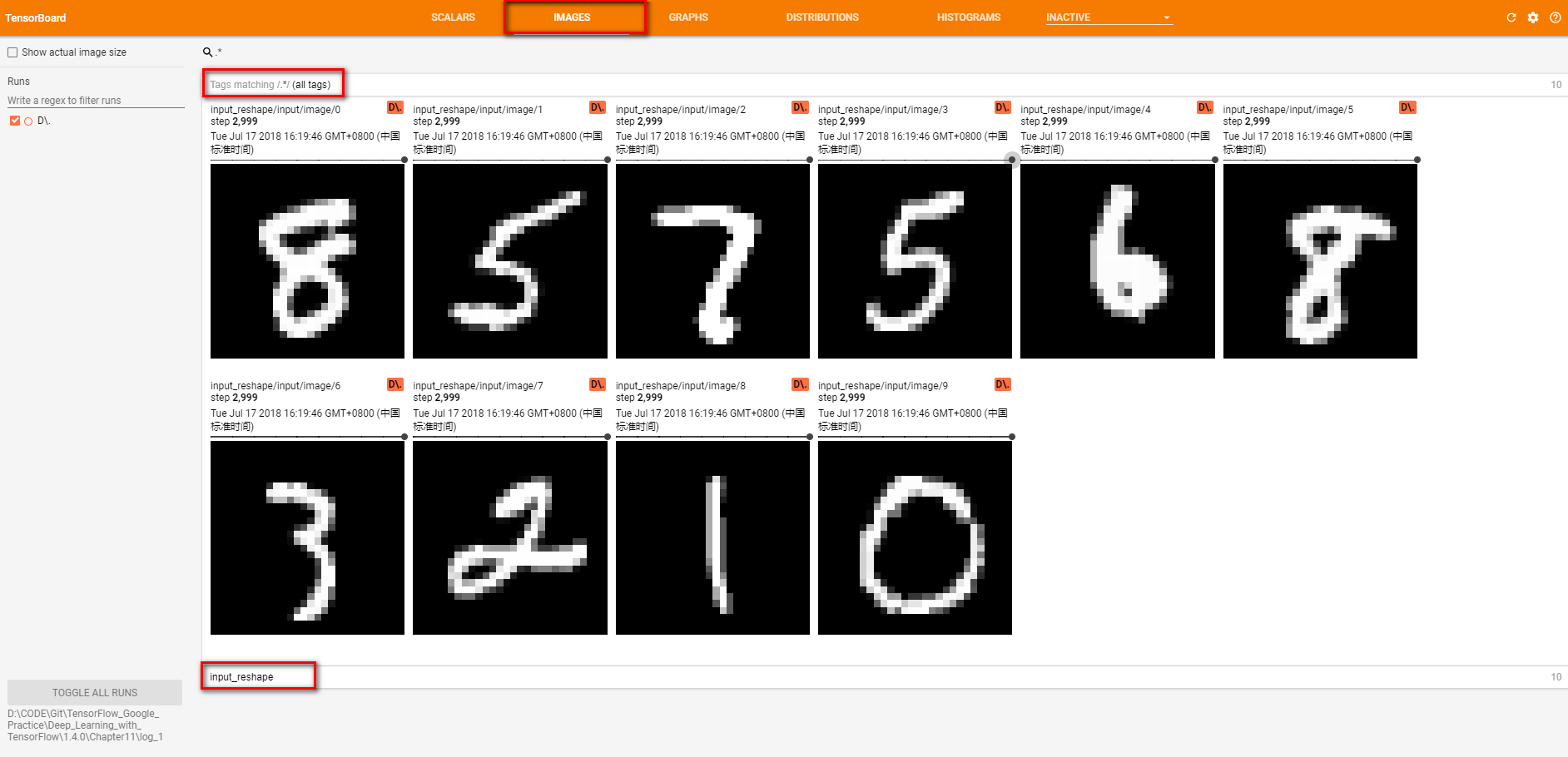
tf.summary.image('input', image_shaped_input, 10)
# 将输入变量还原成图片的像素矩阵,并通过tf.iamge_summary函数定义将当前的图片信息写入日志的操作
hidden1 = nn_layer(x, 784, 500, 'layer1')
y = nn_layer(hidden1, 500, 10, 'layer2', act=tf.identity)
# 计算交叉熵并定义生成交叉熵监控日志的操作。
with tf.name_scope('cross_entropy'):
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_))
tf.summary.scalar('cross_entropy', cross_entropy)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
"""
计算模型在当前给定数据上的正确率,并定义生成正确率监控日志的操作。如果在sess.run()
时给定的数据是训练batch,那么得到的正确率就是在这个训练batch上的正确率;如果
给定的数据为验证或者测试数据,那么得到的正确率就是在当前模型在验证或者测试数据上
的正确率。
"""
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# tf.scalar_summary,tf.histogram_summary,tf.image_summary函数都不会立即执行,需要通过sess.run来调用这些函数
# 因为程序重定义的写日志的操作非常多,一一调用非常麻烦,所以Tensorflow提供了tf.merge_all_summaries函数来整理所有的日志生成操作。
# 在Tensorflow程序执行的过程中只需要运行这个操作就可以将代码中定义的所有日志生成操作全部执行一次,从而将所有日志文件写入文件。
merged = tf.summary.merge_all()
with tf.Session() as sess:
# 初始化写日志的writer,并将当前的Tensorflow计算图写入日志
summary_writer = tf.summary.FileWriter(SUMMARY_DIR, sess.graph)
tf.global_variables_initializer().run()
for i in tqdm.tqdm(range(TRAIN_STEPS)):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
# 运行训练步骤以及所有的日志生成操作,得到这次运行的日志。
summary, _ = sess.run([merged, train_step], feed_dict={x: xs, y_: ys})
# 将得到的所有日志写入日志文件,这样TensorBoard程序就可以拿到这次运行所对应的
# 运行信息。
summary_writer.add_summary(summary, i)
summary_writer.close()
if __name__ == '__main__':
main()
TensorFlow日志生成函数与Tensorboard界面栏对应关系

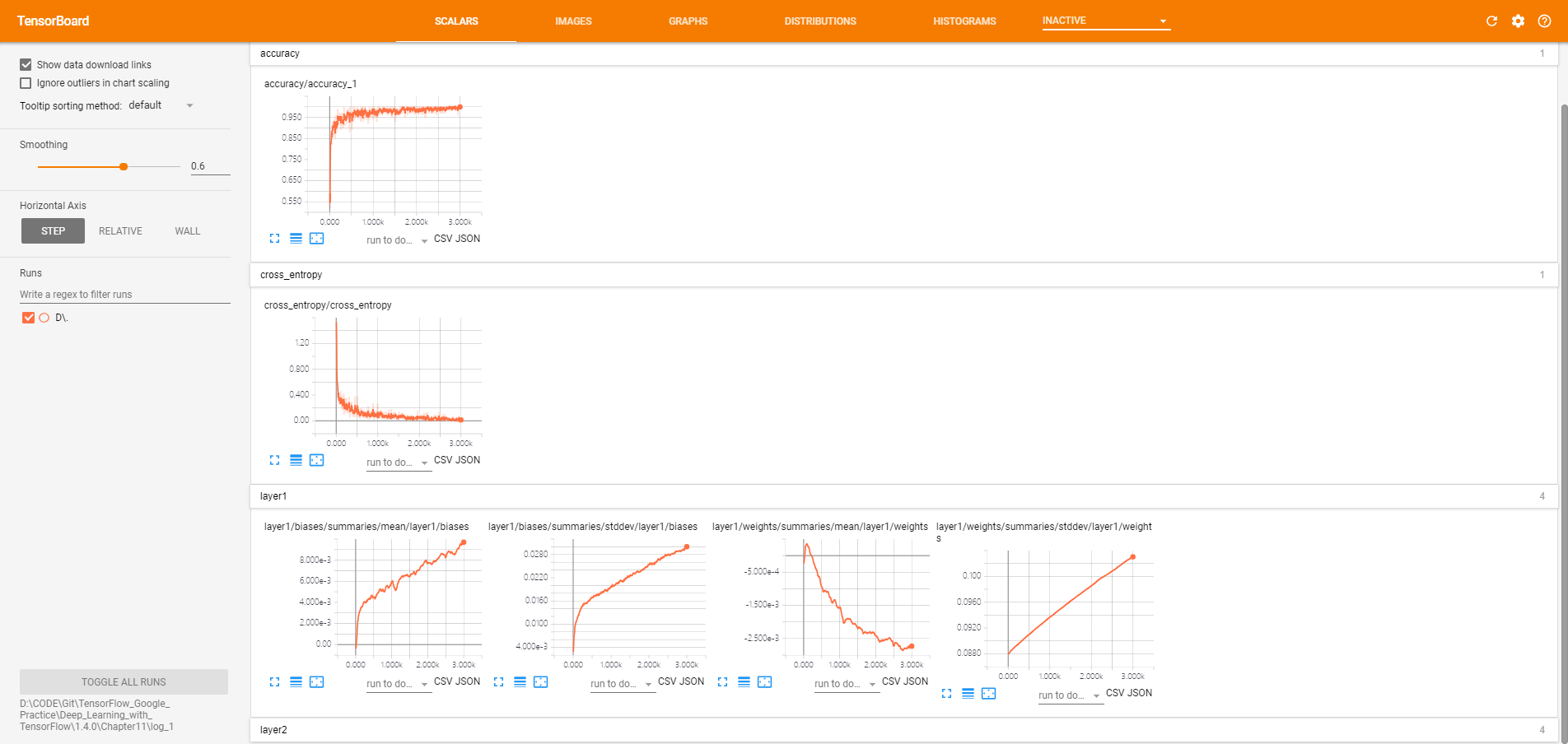
按命名空间分类的监控指标