Dapr的全称是 “Distributed Application Runtime”,即 “分布式应用运行时”。Dapr 是一个开源项目,由微软发起,目前已加入CNCF孵化器项目。
在ServiceMesh初步成功,Sidecar模式被云原生社区普遍接受之后,效仿ServiceMesh,将应用需要的其他分布式能力外移到各种Runtime变成为一个趋势。这些Runtime会逐渐整合,最后和应用 Runtime 共同组成微服务,形成所谓的“Multi-Runtime”架构,又称Mecha:
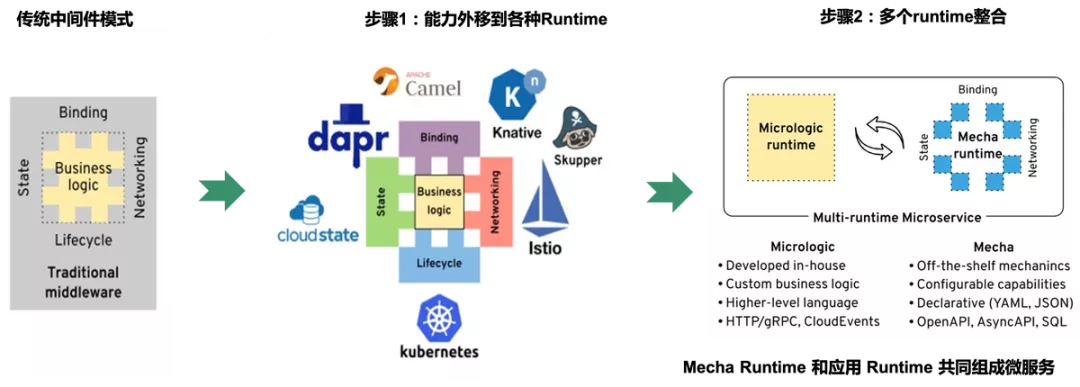
Dapr项目是目前业界第一个Multi-Runtime / Mecha实践项目,下图来自Dapr官方,比较完善的概括了 Dapr 的能力和层次架构:
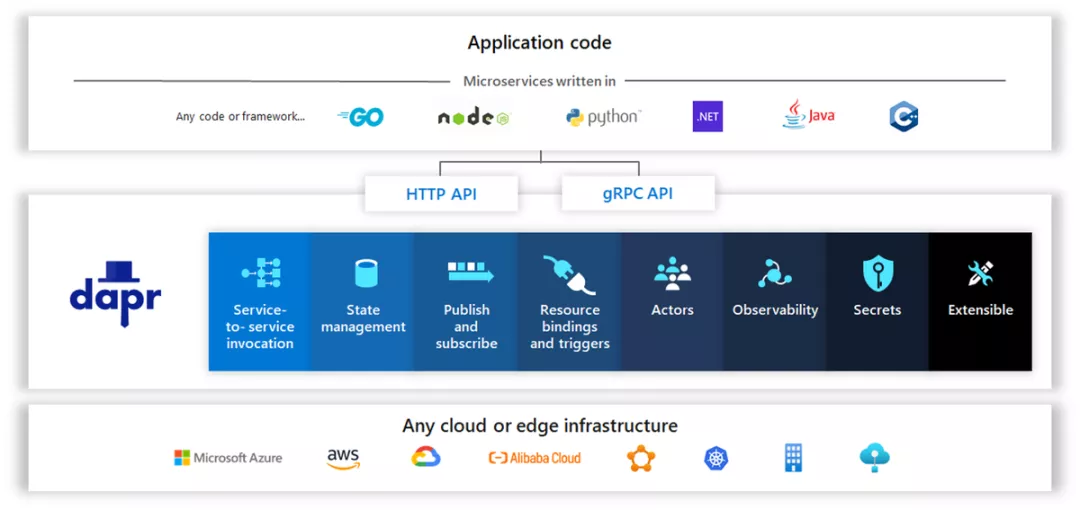
Dapr的愿景:any language, any framework, anywhere
Dapr的本质:面向云原生应用的分布式能力抽象层
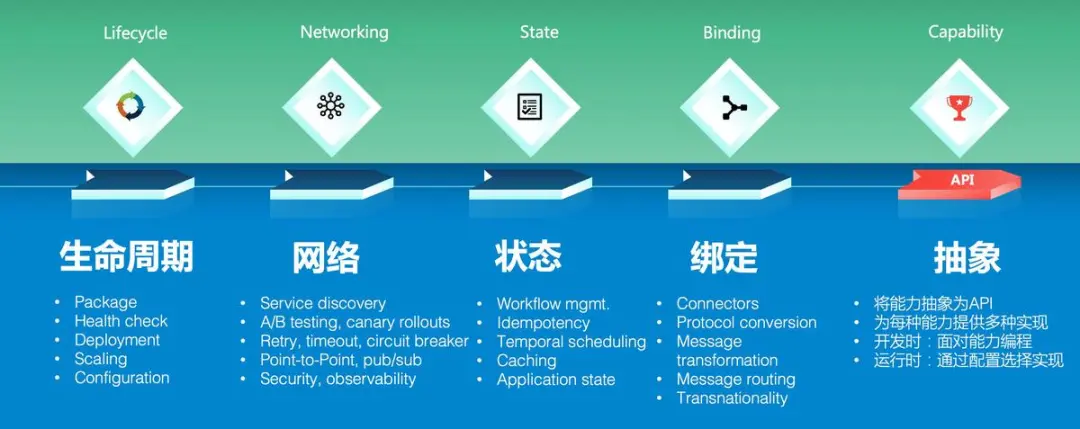
可移植性是Dapr的重要目标和核心价值。Dapr 的愿景, “any language, any framework, anywhere",这里的 anywhere 包括:
- 公有云
- 私有云
- 混合云
- 边缘网络
而 Dapr 可移植性的基石在于标准API + 可拔插可替换的组件,下面这张来自 Dapr 官方网站的图片非常形象的展示了Dapr的这一特性:
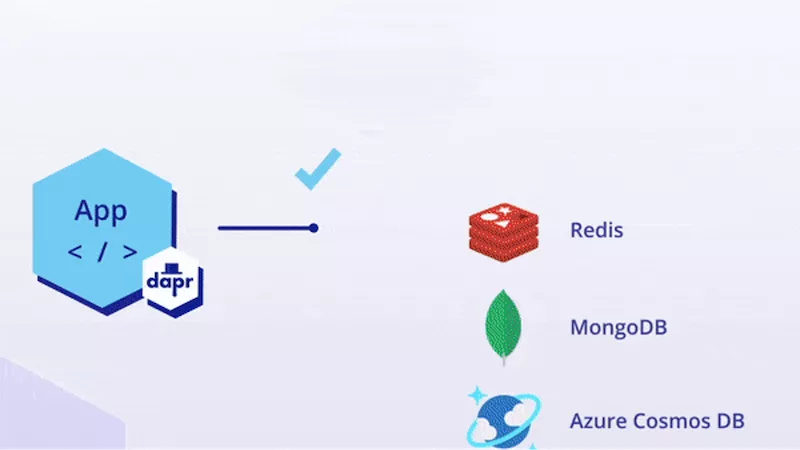
从架构设计的角度看,Dapr 的精髓在于:通过抽象/隔离/可替换,解耦能力和实现,从而实现可移植性。
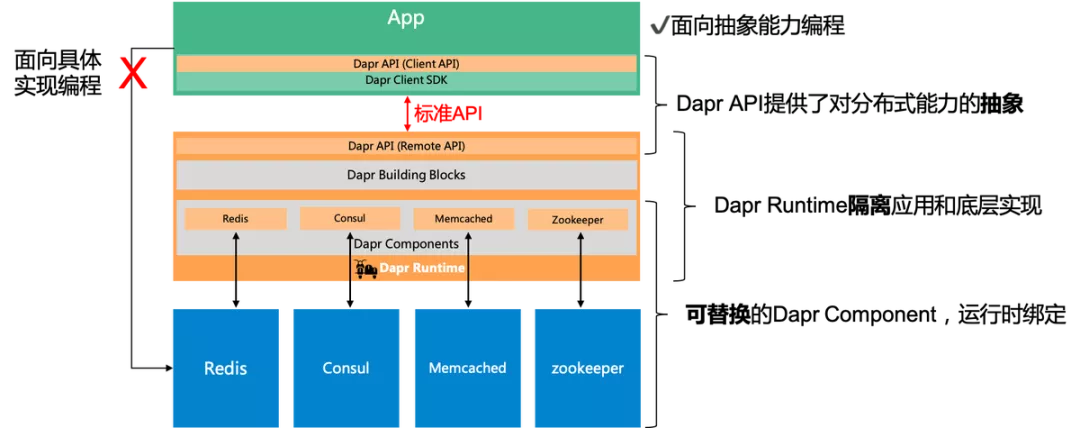
在传统的应用开发方式中,应用需要面向具体的实现编程,即当应用需要使用到某个能力时,就需要找到能提供该能力的底层组件,如上图中的 redis / consul / memcached / zookeeper 都可以提供分布式状态的存储能力。应用在选择具体组件之后,就需要针对该组件进行编程开发,典型如引入该组件的客户端SDK,然后基于这些SDK实现需要的分布式能力,如缓存、状态、锁、消息通讯等具体功能。
在 Dapr 中,Dapr 倡导 “面向能力编程",即:
- Dapr API 提供了对分布式能力的抽象,并提取为标准API
- Dapr 的 Runtime 隔离 应用和底层组件的具体实现
而这些组件都是可替换的,可以在运行时才进行绑定。
Dapr 通过这样的方式,实现了能力和实现的解耦,并给出了一个美好的愿景:在有一个业界普遍认可并遵循的标准化API的基础上,用户可以自由选择编程语言开发云原生,这些云原生可以在不同的平台上运行,不被厂商和平台限制——终极目标是使得云原生应用真正具备跨云跨平台的可移植性。
理想很美好,但现实依然残酷:和 ServiceMesh 相比,Dapr 在落地时存在一个无可回避的问题——应用改造是有成本的。
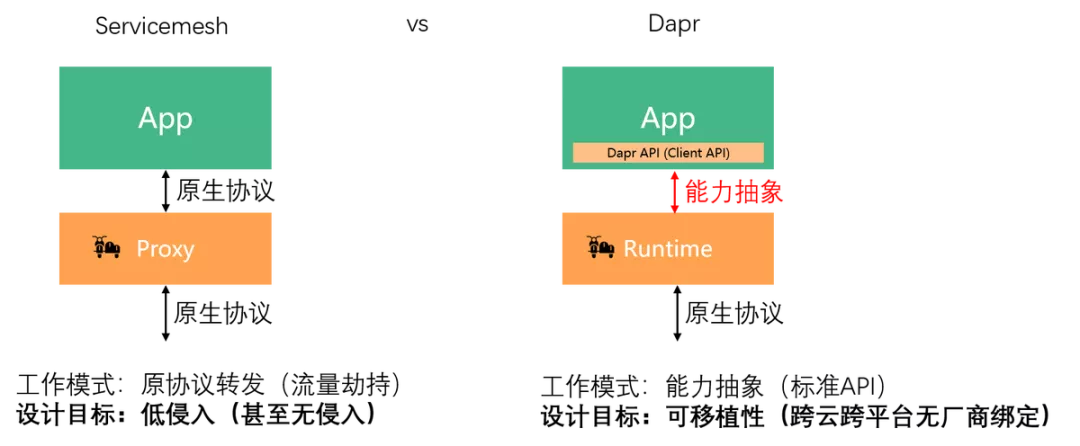
从落地的角度来看, ServiceMesh 的低侵入性使得应用在迁移到 ServiceMesh 时无需太大的改动,只需要像往常一样向 sidecar 发出原生协议的请求即可,甚至在流量劫持的帮助下可以做到应用完全无感知。从工作模式上说,基于原生协议转发的 ServiceMesh 天然对旧应用友好。而 Dapr 出于对可移植性目标的追求,需要为应用提供一个标准的分布式能力抽象层来屏蔽底层分布式能力的具体实现方式,应用需要基于这个抽象层进行开发,才能获得跨云跨平台无厂商绑定等可移植性方面的收益。因此,在 Dapr 落地过程中,新应用需要基于 Dapr API 全新开发,老应用则不可避免的需要进行改造以对接 Dapr API。
API 标准化是 Dapr 成败的关键,为Dapr的发展建立起良性循环:
1.API 标准化
定义Dapr API,对某一个分布式能力进行良好的抽象,覆盖日常使用的大部分场景,满足应用的常见需求
2.提供组件支持
基于标准Dapr API,为开源产品和公有云商业产品提供支持组件,覆盖主流产品和厂商
3.具备可移植性
基于标准Dapr API开发的应用,可以在主流开源产品和公有云商业产品之间自行选择适合的组件,不受平台和厂商的限制
4.API 得到更多认可
可移植性为Dapr构建核心价值,Dapr API得到更多的认可,逐渐成为业界的事实标准
5.更广泛的组件支持
Dapr API越接近业界标准,就会有越多的产品和厂商愿意提供支持Dapr API的组件
6.可移植性更强
越来越多的组件支持,可以覆盖更多的开源产品和厂商,从而更接近Anywhere的愿景
理想情况下,“标准化” / “组件支持” / “可移植性” 之间的相互促进和支撑将成为Dapr发展源源不断的动力。反之,如果API标准化出现问题,则组件的支持必然受影响,大大削弱可移植性,Dapr存在的核心价值将受到强烈挑战。
左右为难:取舍之间何去何从
既然API标准化如此重要,那Dapr该如何去定义 API 并推动其标准化呢?我们以Dapr State API 为例,介绍在API定义和标准化过程中常见的问题。
State API的基本定义
State形式上是key-value存储,即状态信息被序列化为 byte[]然后以value的形式存储并关联到 key,当然实践中非 kv 存储也可以实现State的功能,比如mysql等关系型数据库。Dapr的 State API 的定义非常简单明了,除了基于key的CRUD基本操作外,还有CRUD的批量操作,以及一个原子执行多个操作的事务操作:

上述API定义貌似非常简单,毕竟kv基本操作的语义非常容易理解。但是,一旦各种高级特性陆续加入之后,API就会逐渐复杂:数据一致性 / 并发保护 / 过期时间 / 批量操作等。
State API的高级特性
以 GetState() 为例,我们展开GetStateRequest和GetStateResponse这两个消息的定义,了解一下数据一致性 / 并发保护这两个高级特性:
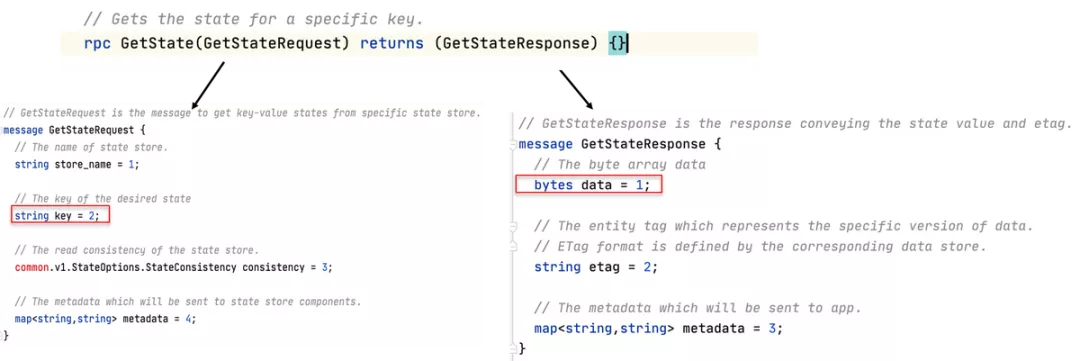
可以看到GetStateRequest 中的字段key和GetStateResponse 中以bytes[] 格式定义的字段 data,对应于key-value中的key和value。GetState()的基本语义非常明显的呈现:请求中给出 key,在应答中返回对应的 value。除此之外,在API的设计中还有三个字段:
请求中的consistency字段用于数据一致性
当组件支持多副本时,consistency字段将用于指定对数据一致性的要求,其取值有两种:eventual:(最终一致性)和 strong:(强一致性)。除了getState()方法外,这个参数也适用于saveState()和 deleteState() 方法。
应答中的 etag 字段用于并发,实现乐观锁
乐观锁的工作原理如上图所示,假定有三个请求同时查询同一个key,三个应答中都会返回当前key的etag(值为"10”)。当这三个线程同时进行并发修改时,在saveState()的请求中需要设置之前获取到的etag,第一个save请求将被接受然后对应key的etag将修改为"11”,而后续的两个save请求会因为etag不匹配而被拒绝。
etag 参数在 getState() 方法中返回,在 saveState() 方法中设置,每次对key进行写操作都要求必须修改etag。
concurrency 参数在 saveState()方法中设置,有两个值可选:first_write(启用乐观锁) 和 last_write(无乐观锁,简单覆盖)。
请求和应答中都有的metadata
类型定义为map,可以方便的传递未在 API 中定义的参数,为 API 提供扩展性:即提供实现个性化功能(而不是通用功能)的扩展途径。
对批量操作的处理
State API 提供的批量操作,用于一次性操作多个key,和应用多次调用单个操作的 API 相比,减少了多次往返的性能开销和延迟。考虑到组件原生对批量操作的支持程度,Dapr 中的批量操作的实现方式有两种:
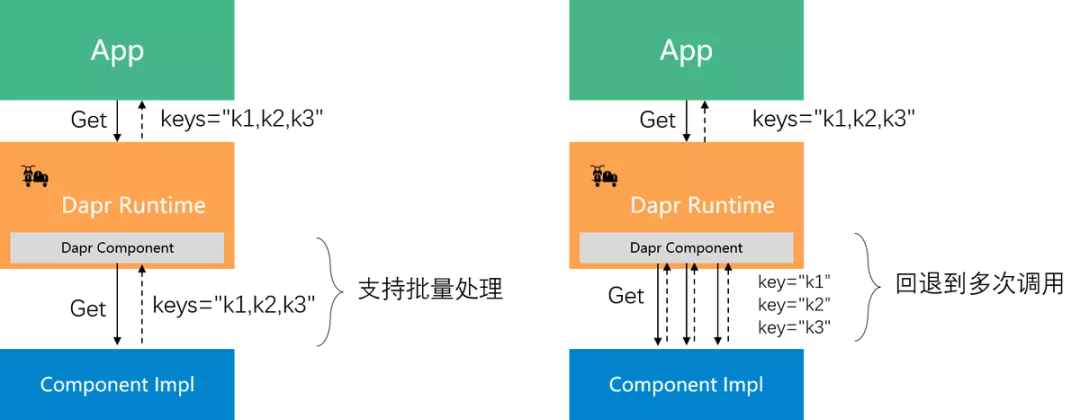
- 原生支持批量操作:Dapr 组件将多个key一起打包提交给组件的后端实现,此时批量操作的实现由后端完成,Dapr 只是简单转发了多个key
- 原生不支持批量操作:Dapr 组件将多次调用组件的后端实现,此时批量操作的实现由 Dapr 组件完成
展开细节看一下 Dapr 中 GetBulkState() 方法的代码实现,忽略细节代码和加密处理,只看主体逻辑:
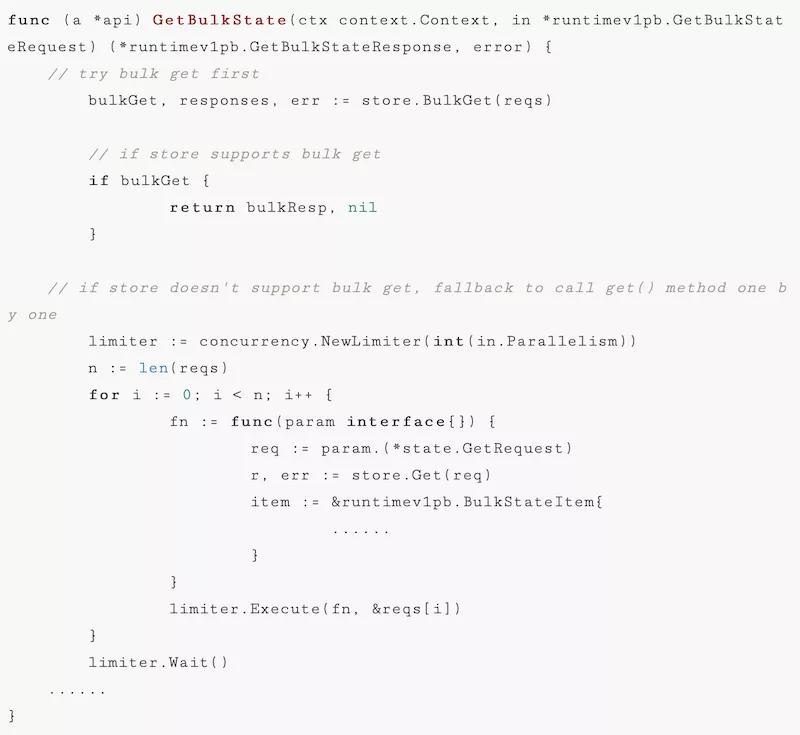
Dapr的GetBulkState()方法先尝试调用组件实现的BulkGet(),如果组件支持批量操作则直接返回结果。而当组件不支持批量操作时,GetBulkState()方法会做两个事情:
1.兜底:Dapr 通过多次调用单个 getState() 方法来模拟实现批量操作,对于应用来说是没有感知的
2.优化:如果只是简单的循环调用,当key比较多时延迟累加会比较大,因此 Dapr 做了一个并行查询的优化,容许启动多线程同时发起多个查询,然后将结果汇总起来后再一起返回。
Dapr 这样做的好处是:对于支持批量操作的组件可以充分发挥其功能,同时对于不支持批量操作的 组件由 Dapr 模拟出了批量操作的功能并提供了基本的性能优化。最终使得批量操作的API可以被所有组件都支持,从而让使用者在使用批量API时可以有统一的体验。
对事务操作的处理
相对于批量操作的简单处理方式,事务的支持在 Dapr 中就要麻烦的多,是目前 State API 在实现中最大的挑战,其根源在于:很多组件不支持事务!而且,事务性也无法像批量操作那边在 Dapr 侧进行简单补救。
以下是实现了 Dapr State API 的组件对事务支持的情况,其中支持事务的组件有:
- Cosmosdb
- Mongodb
- Mysql
- Postgresql
- Redis
- Rethinkdb
- Sqlserver
不支持事务的组件有: - Aerospike
- Aws/dynamodb
- Azure/blobstorage
- Azure/tablestorage
- Cassandra
- Cloudstate
- Couchbase
- Gcp/firestore
- Hashicorp/consul
- hazelcase
- memcached
- zookeeper
因此,Dapr State API 的组件被是否支持事务分成了两大类。这些组件在开发时和运行时调用上需要就是否支持事务进行区分:
1.组件在初始化时需要指明是否支持事务
2.Dapr 在启动时进行过滤,支持事务的组件单独放在一个集合中

3.Dapr 在启动时进行过滤,支持事务的组件单独放在一个集合中
这直接导致了一个严重的后果:当用户使用 Dapr State API 时,就必须先明确自己是否会使用到事务操作,如果是,则只能选择支持事务的组件。
残酷的现实:高级特性的支持度
在前面我们讲述API标准化的价值时,是基于一个基本假设:在能力抽象和API标准化之后,各种组件都可以提供对 Dapr API 的良好实现,从而使得基于这些标准API开发的应用在功能得到满足的同时也可以获得可移植性。
这是一个非常美好的想法,但这个假设的成立是有前提条件的:
1.API定义全部特性:即API 提供的完整的能力,包括各种高级特性,从功能的角度满足用户对分布式能力的各种需求
2.所有组件都完美支持:每个组件可以完整的实现API抽象和标准化的这些能力,不存在功能缺失,从而保证在任意一个平台上都可以以相同的体验获取同样的功能
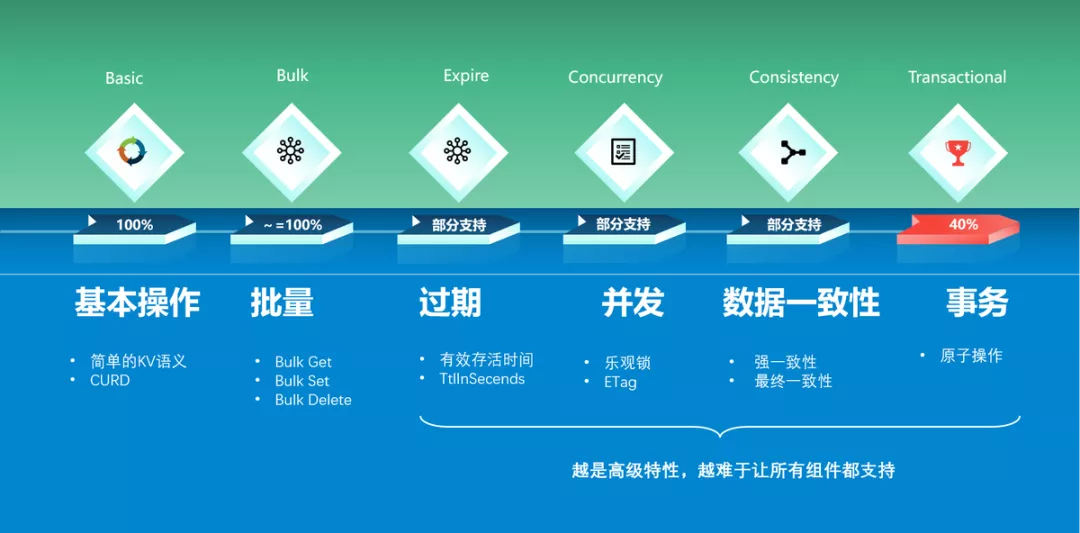
- 而现实是残酷的:特性越是高级,就越难于让所有组件都支持。以Dapr State API为例,如上图所示从做向右的各种特性,组件的支持程度越来越差:
- 基本操作:这些是基本的KV语义,CURD操作,而且是每次操作单个key。所有组件都支持,支持度=100%
- 批量操作:在基本操作的基础上增加对多个key同时操作的支持,部分组件不能原生支持,但是Dapr可以在单个的基本操作上模拟出批量操作来进行弥补,因此也可以视为都支持,支持度~=100%
- 过期时间:可选特性,设置过期时间可以让key在该时间之后自动被清理,有部分组件原生支持这个特性,但也有部分组件无法支持。这是一个可选特性,Dapr的设计是通过在请求中提供名为 TtlInSeconds的metadata来指定。
- 并发支持:乐观锁机制,要求组件为每个key提供一个etag字段(或者称为version),每次修改时都要比对etag,修改后要更新etag。这个特性也是只有部分组件支持,需要在组件支持特性中明确指出是否支持。
- 数据一致性:容许在请求中提供参数指定操作对数据一致性的要求,可以是强一致性或最终一致性,组件如果支持就可以依照这个参数的指示进行操作。这个特性同样只有部分组件支持
- 事务:提供对多个写操作的原子性支持,只有部分组件支持(按照前面列出来的组件支持情况,大概是40%),需要在组件支持特性中明确指出是否支持。
但实际上,在API定义和标准化的过程中,我们不得不面对这样一个残酷的现实:API定义全部特性 和 所有组件都完美支持 无法同时满足!
这导致在定义 Dapr API 时不得不面对这么一个痛苦的抉择:向左?还是向右?

- 向左,只定义基本特性,最终得到的API倾向于功能最小集
优点:所有组件都支持,可移植性好
缺点:功能有限,很可能不满足需求
- 向右,定义各种高级特性,最终得到的API倾向于功能最大集
优点:功能齐全,很好的满足需求
缺点:组件只提供部分支持,可移植性差
API定义的核心挑战
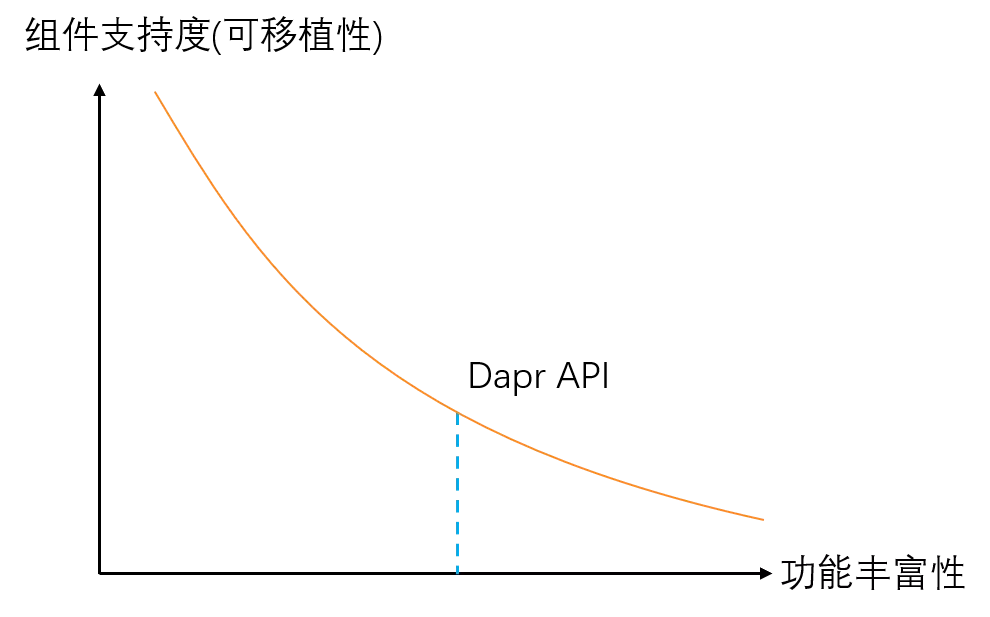
Dapr API定义的核心挑战在于:功能丰富性和组件支持度难于兼顾。
如下图所示,当API定义的功能越丰富时,组件的支持度越差,越来越多的组件出现无法支持某个定义的高级特性,导致可移植性下降:
在 Dapr 现有的设计中,为了在标准API定义之外提供扩展功能,引入请求级别的 metadata 来进行自定义扩展:Dapr 现有的各种API,包括上面我们详细介绍的 State API,基本都经历过这样一个流程:
- 每个Dapr构建块的 API 在初始创建时,通常会从基本功能开始,相对偏左侧
- 随着时间的推移,为了满足更多场景下的用户需求,会向右移动,在API中增加新功能
- 新增的功能可能会导致部分组件无法提供支持,损害可移植性
因此 Dapr API 在定义和后续演进时需要做权衡和取舍:
- 不能过于保守:太靠近左侧,虽然可移植性得以体现,但功能的缺失会影响使用
- 不能过于激进:太靠近右侧,虽然功能非常齐备,但是组件的支持度会变差,影响可移植性
Metadata的引入和实践
在 Dapr 现有的设计中,为了在标准API定义之外提供扩展功能,引入请求级别的 metadata 来进行自定义扩展:

metadata 字段的类型定位为map,可以方便的携带任意的key-value,在不改变API定义的情况下,组件和使用者可以约定在请求级别的metadata中通过传递某些参数来使用更多的底层能力。
下图是在阿里云在内部落地 Dapr 时,对 Dapr State API 的各种 metadata 自定义扩展:

注意:State API 中,expire 的功能在通过名为 ttlInSeconds 的 metadata 来实现,而没有直接在 getStateRequest 中定义固定字段。
metadata 的引入解决了API功能不足的问题,但是也造成了另外一个严重问题:破坏可移植性。
- 可移植性是Dapr的核心价值:因此定义Dapr API时应尽量满足可移植性的诉求,API设计时会偏功能最小集
- 为了提供最大限度的可移植性,设计时往往会倾向于从功能最小集出发,如下图所示:
3.出现功能缺失
功能最小集合意味着Dapr API只定义基本功能,自然会导致缺乏各种高级特性,落地时会遇到无法满足应用需求的情况
4.进行自定义扩展
为了满足需求,使用请求级别的 metadata 进行自定义扩展,提供 Dapr API 没有定义的功能
5.优点:满足功能需求
metadata 的使用扩展了功能,使得底层组件的能力得以释放
6.缺点:严重破坏可移植性
自定义扩展越多,在迁移到其他组件时可能丢失的功能就越多,可移植性就越差
从图上看,当从可移植性为出发点进行API设计时,由于功能缺失迫使引入 metadata 进行自定义扩展,在解决功能问题的同时,造成了可移植性的严重破坏。从而偏离了我们的初衷,也造成整个API设计和落地打磨的流程无法形成闭环,无法建立良性循环。