1 语义分割
语义分割是对图像中每个像素作分类,不区分物体,只关心像素。如下:

(1)完全的卷积网络架构
处理语义分割问题可以使用下面的模型:
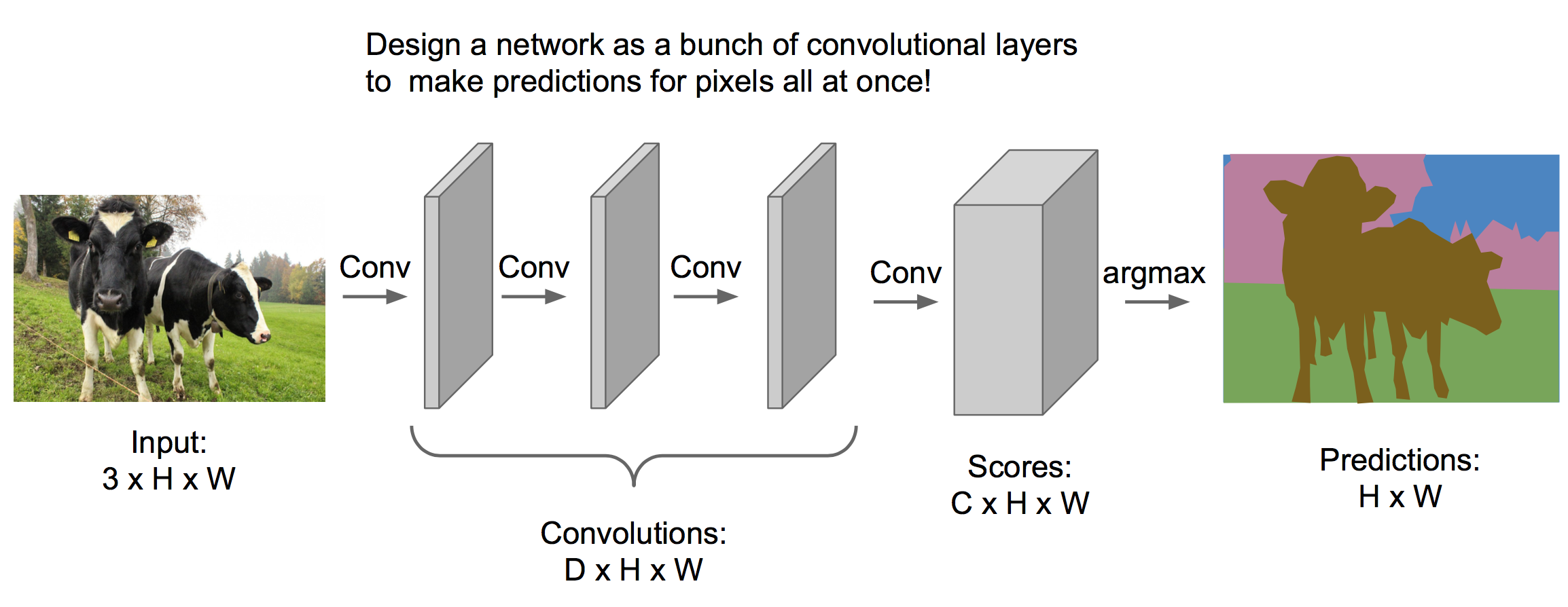
其中我们经过多个卷积层处理,最终输出体的维度是C*H*W,C表示类别个数,表示每个像素在不同类别上的得分。最终取最大得分为预测类别。
训练这样一个模型,我们需要对每个像素都分好类的训练集(通常比较昂贵)。然后前向传播出一张图的得分体(C*H*W),与训练集的标签体求交叉熵,得到损失函数,然后反向传播学习参数。
然而,这样一个模型的中间层完全保留了图像的大小,非常占内存,因此有下面改进的框架。
(2)先欠采样再过采样的框架
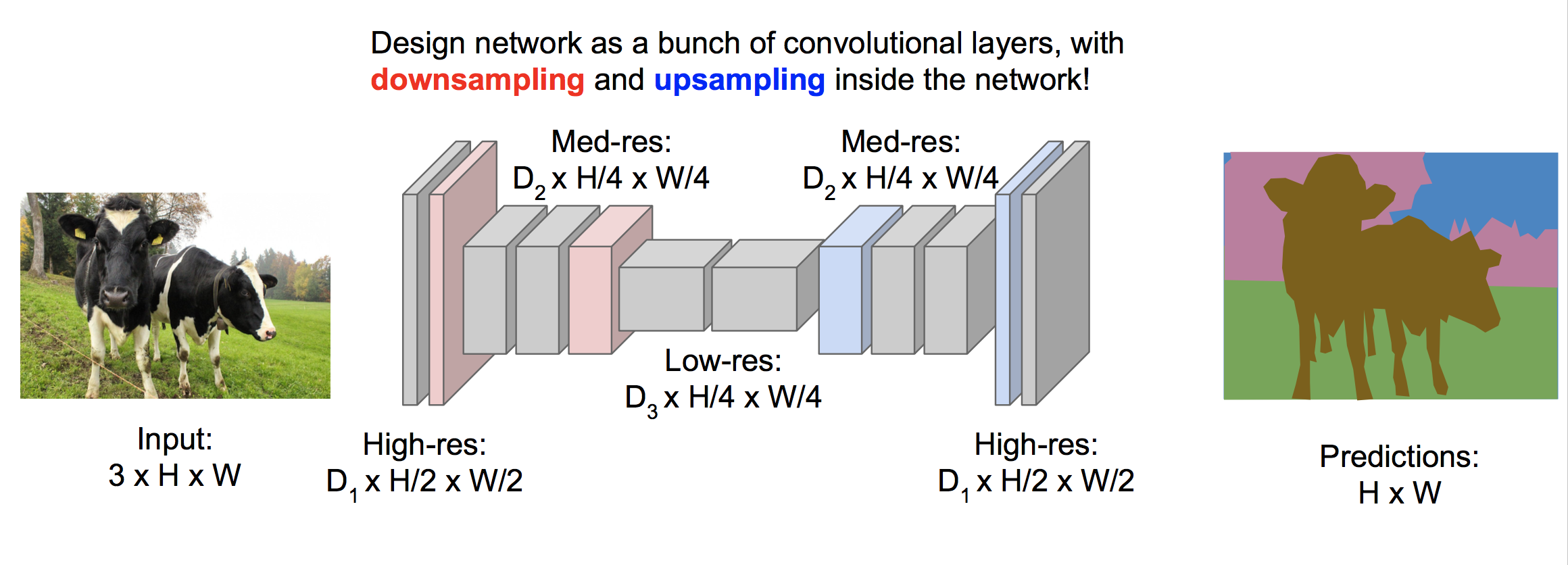
经过欠采样后可以大量节省内存,提高效率,最后再经过过采样来恢复原始图片的大小。我们知道欠采样可以使用卷积层和池化,下面介绍过采样的几种方式。
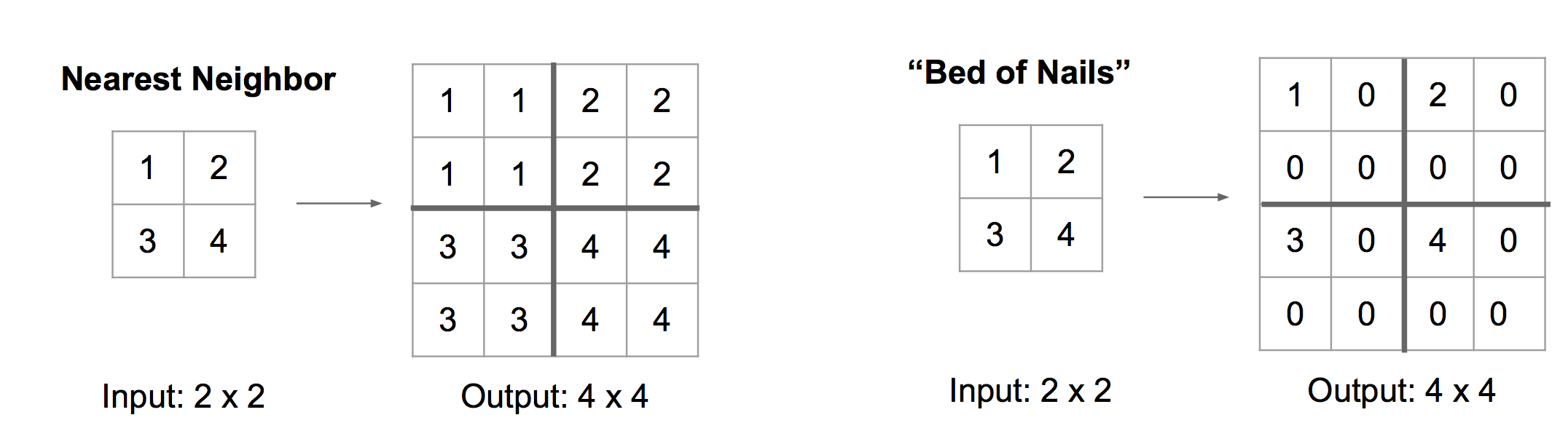
去池化 Unpooling
去池化有Nearest Neighbor,Bed of Nails等方法:
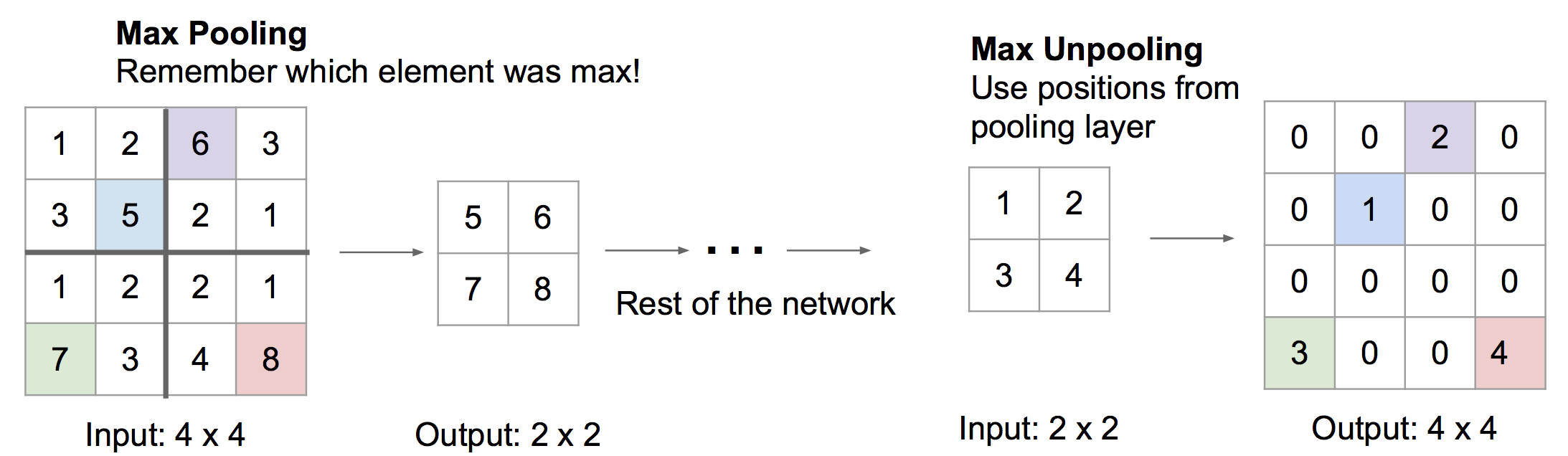
还有一种被称为Max Unpooling 的方法,该方法记录下之前使用max pooling前各个最大值在数组中的索引,去池化的时候把值放到索引处,其他位置补0:
转置卷积 Transpose Convolution
不同于去池化,转置卷积法是一种可学习的过采样方法。具体步骤是,将输入的每个值作为权重,对滤波器进行加权,然后各个加权的滤波器按照步长拼成输出,重叠部分相加。如下:
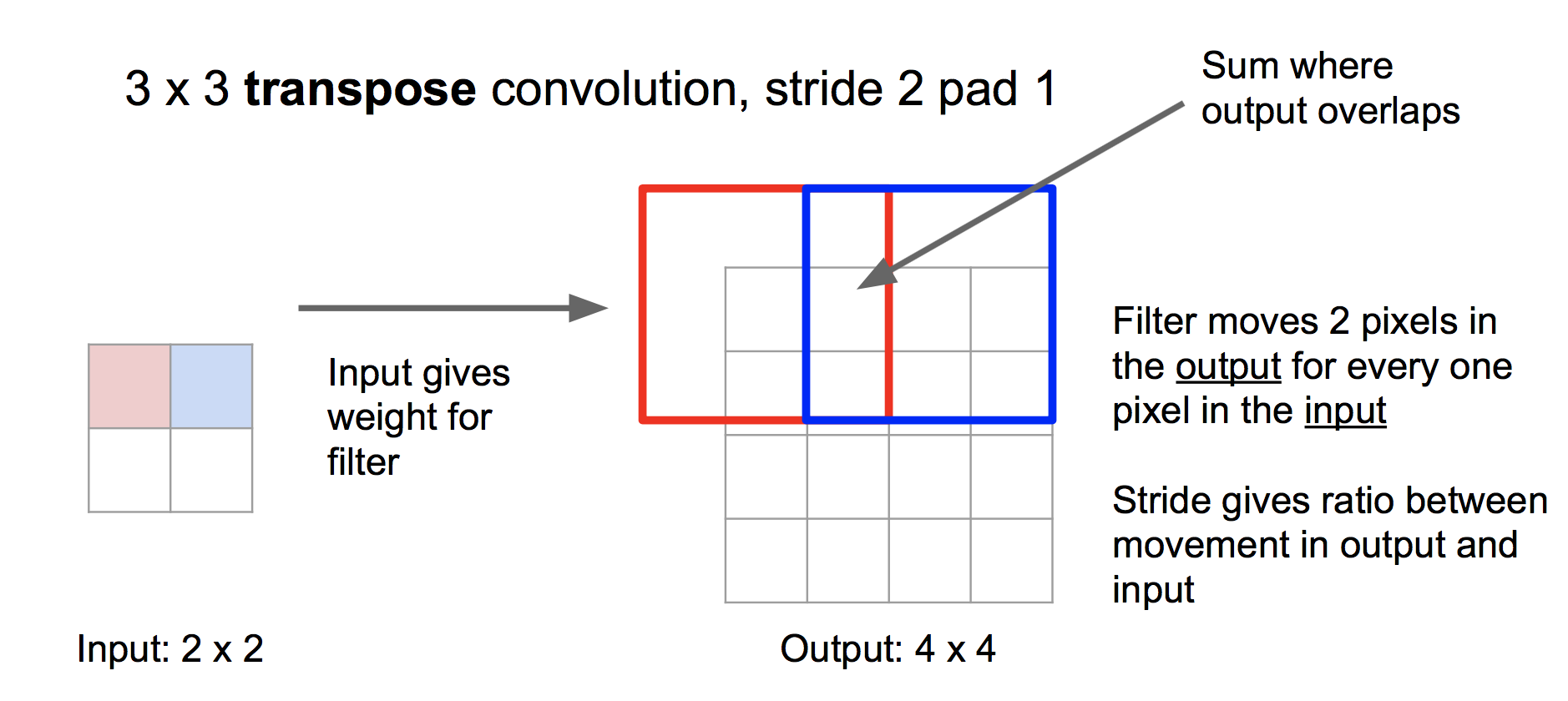
我们可以通过学习滤波器,来学习网络应该如何做过采样。
理解转置卷积的一个一维的例子是:
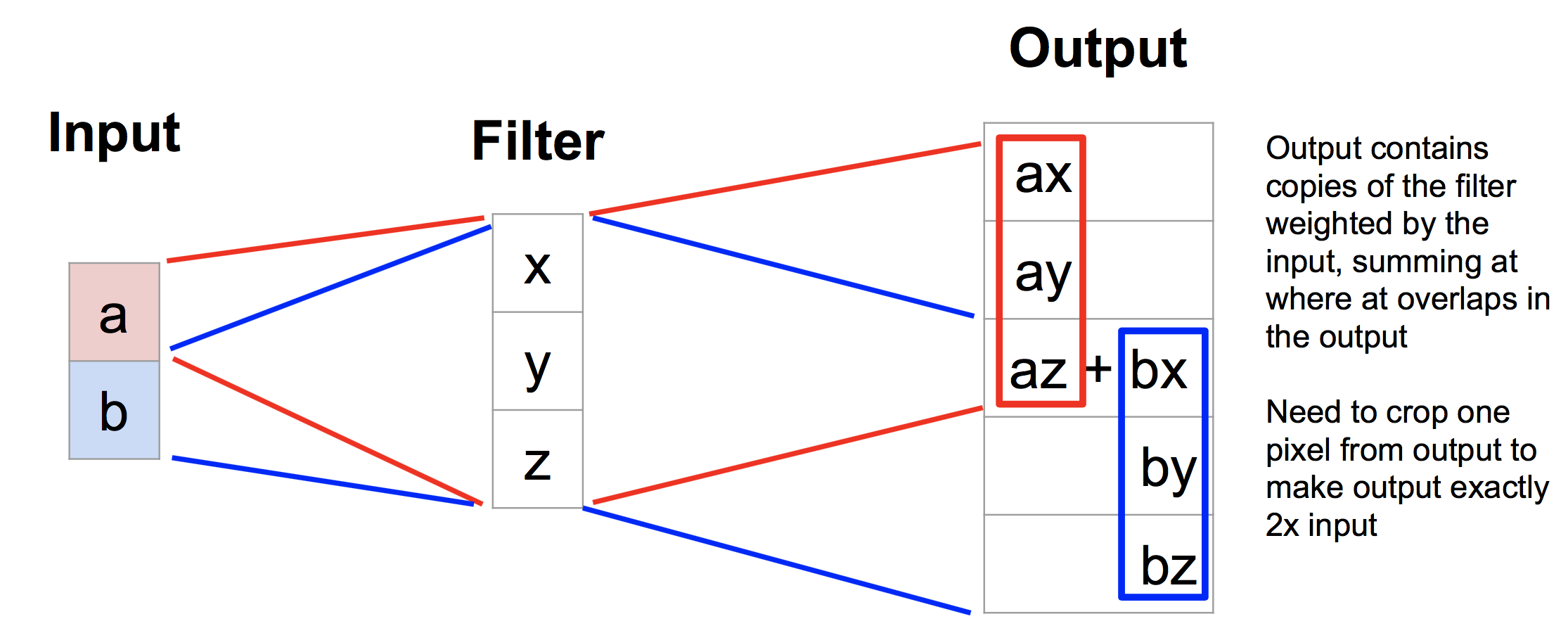
在一些论文里,转置卷积还有一些其他名字,看到的时候要知道:

另外,转置卷积之所以被称为转置卷积,是因为它的矩阵形式。传统的卷积写成矩阵形式如下(注意这里是一维的例子):

其中x是滤波器,a是输入。而转置卷积写成矩阵形式如下:

2 分类+定位
分类+定位的任务要求我们在给图片打标签之后,还要框出物体在什么地方(注意与物体检测的区别,在分类定位中,输出的框的个数是事先已知的,而物体检测中则是不确定的)。如下:

此类任务常用的处理框架如下:
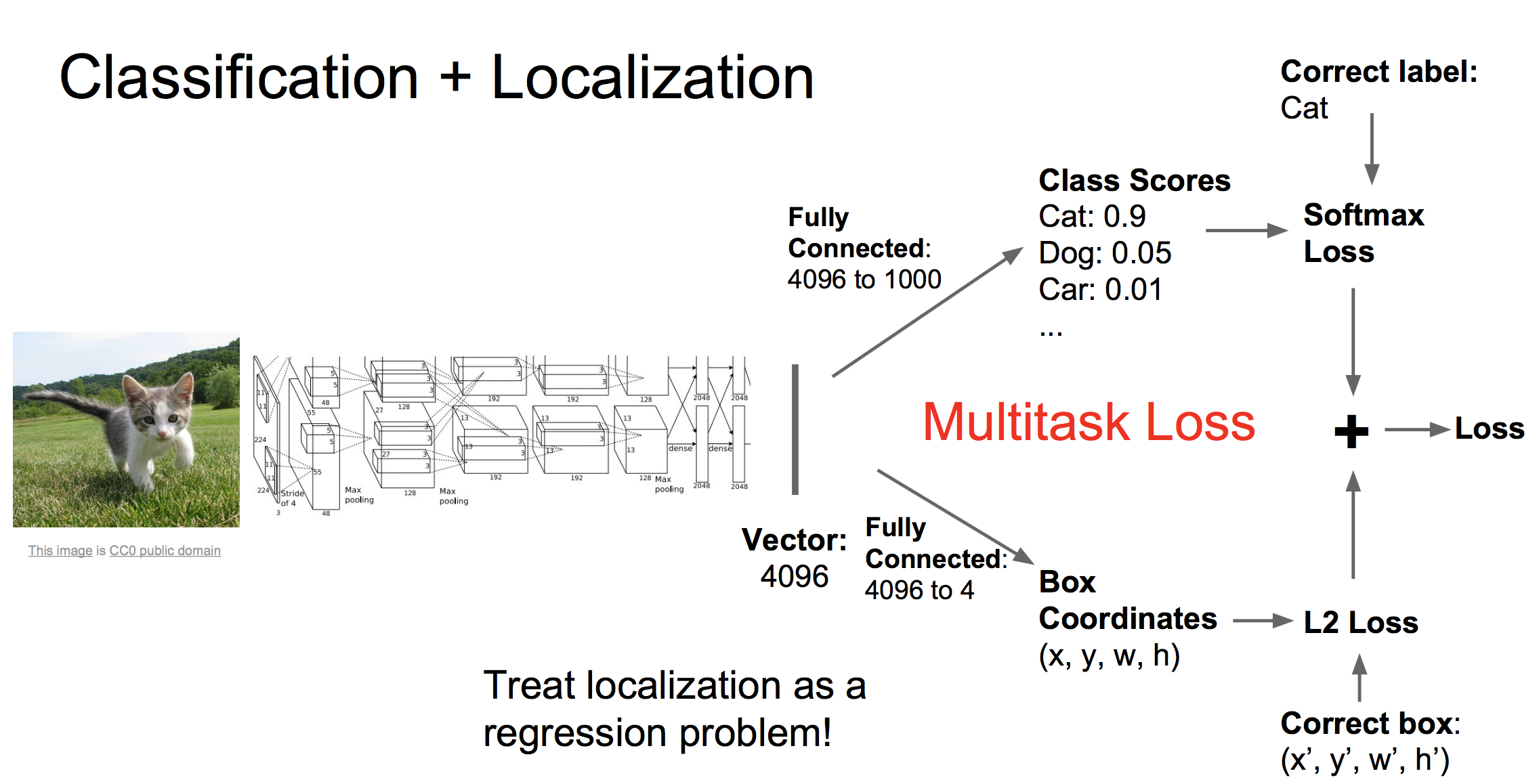
首先我们还是用CNN得到描述图片的特征向量,然后我们接入两个全连接网络,一个网络负责生成最后的类别评分,另一个负责生成红框四个点的坐标值。因此对应两个损失,softmax损失和回归损失。我们将这两个损失加权相加得到总的损失(加权值是超参数),然后进行反向传播学习。
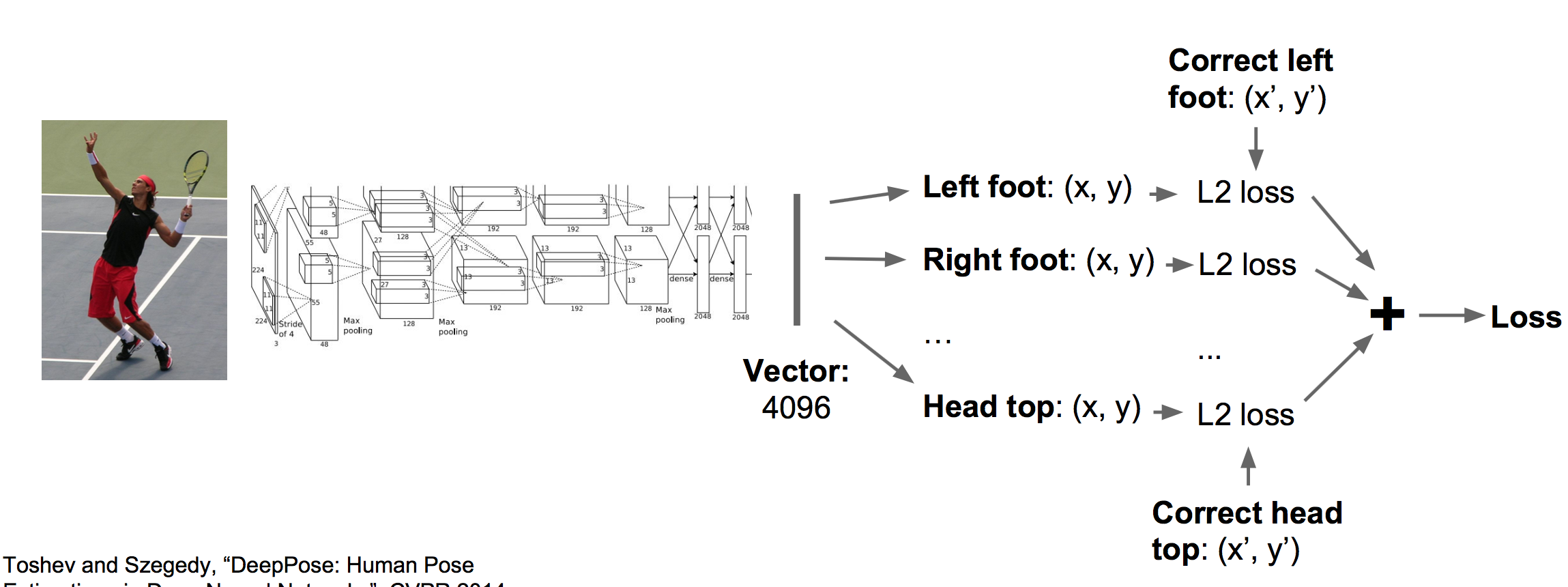
这里应用回归的思路同样可以应用于姿态估计,我们用十四个点来确定一个人的姿态情况:
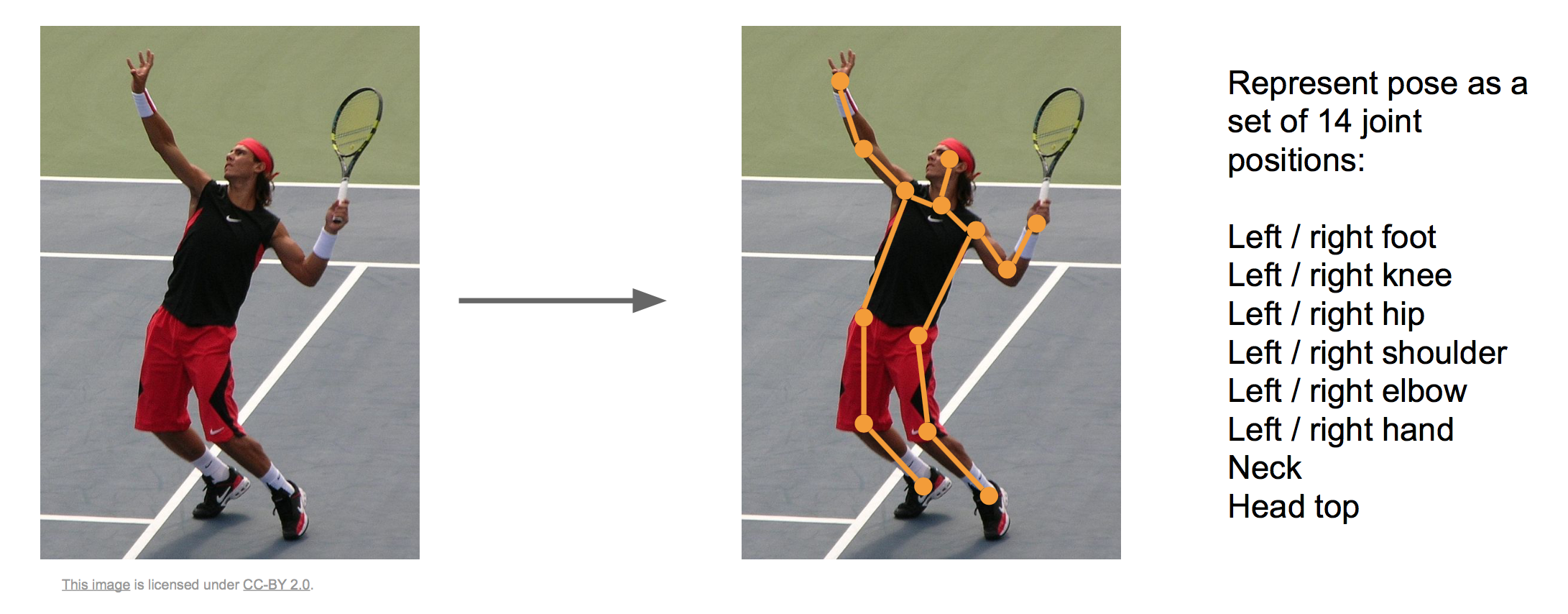
应用同样的框架(CNN+回归全连接网络)可以训练这个任务:
3 物体检测
与分类+定位任务不同的是,物体检测中需要检测的物体数量是不确定的,因此无法直接使用上面的回归框架。下面简单介绍几个框架。
(1)滑动窗口
滑动窗口的思想是随机选取若干个不同大小不同位置的窗口,对它们应用CNN进行分类。缺点是窗口数量很大,计算代价很高。
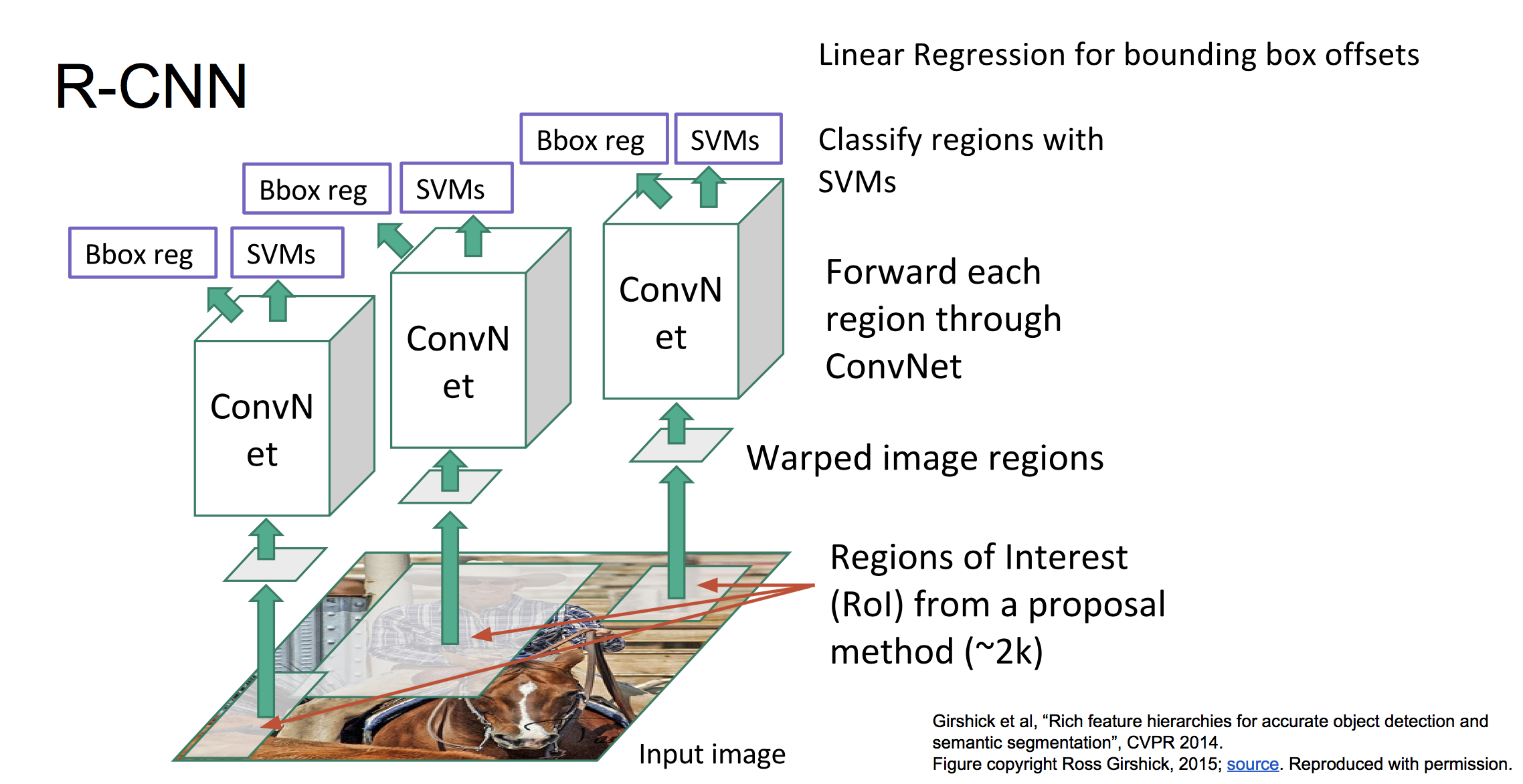
(2)RCNN
训练阶段:
a 使用IMAGENet的数据预训练一个CNN
b 构造训练集:首先应用Selective Search算法从每张带标定框的图像中选取2000~3000个候选框。对每个候选框来说,找到与它重叠面积最大的标定框,如果重叠比例大于阈值(0.5),则将该候选框标签设为该标定框的标签,若重叠比例小于阈值(0.5),则标签设为“背景”。同时对于重叠比例大于一定阈值(0.6)的候选框,还要计算出其与标定框的偏移距离。
c 每个候选区域经过预处理,送到CNN中提取出图像特征,然后把图像特征送到SVM分类器中,计算出标签分类的损失。同时图像特征还要送到回归器中,计算偏移距离的L2损失。
d 反向传播训练SVM,回归器,CNN
整体框架图如下:
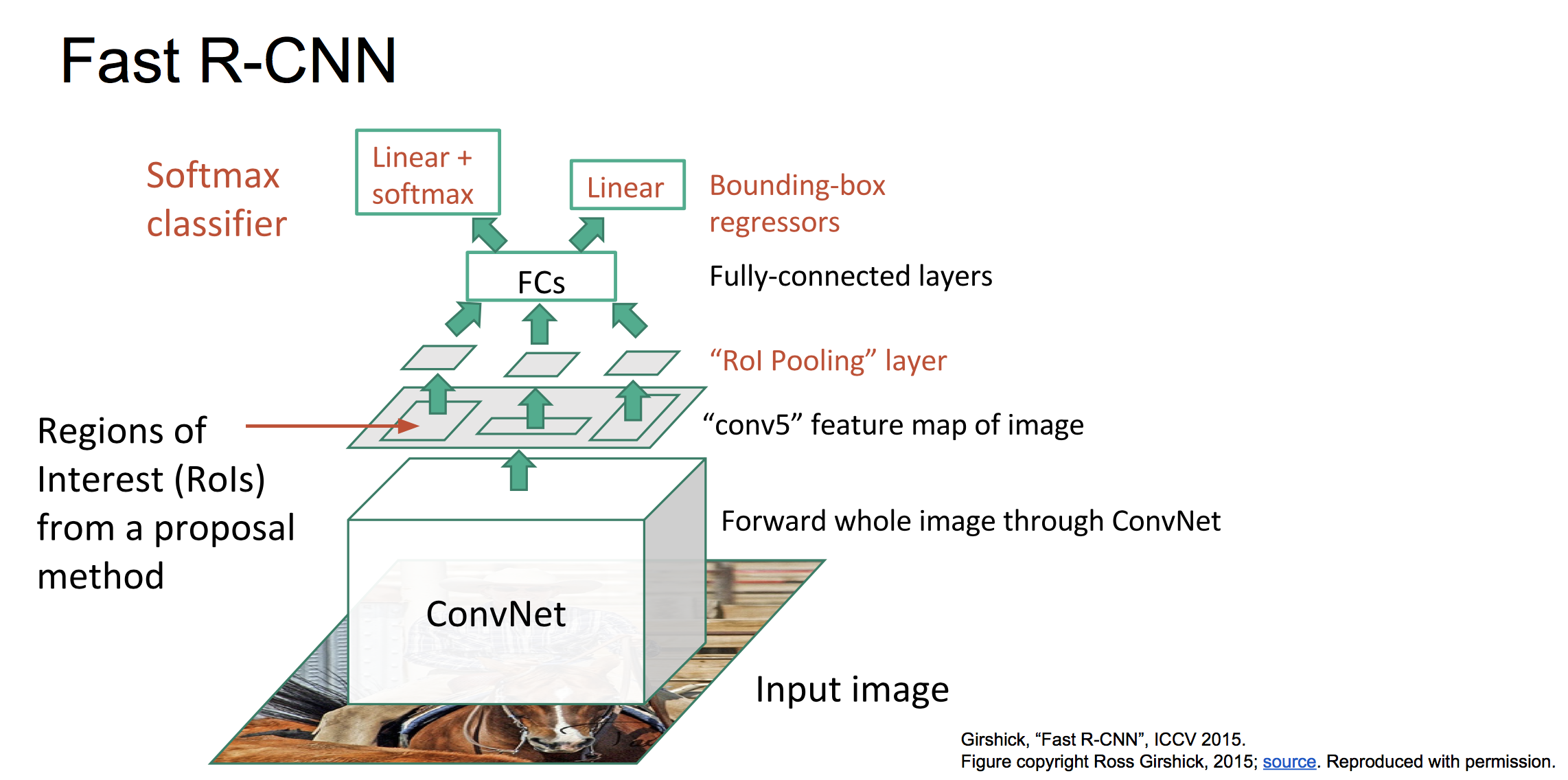
(3)Fast RCNN
RCNN训练和预测速度很慢,主要是由于不同候选框之间的重叠部分特征重复用CNN提取导致的。因此可以采取先对整个图像进行CNN特征提取,然后在选定候选区域,并从总的featuremap中找到每个候选区域对应的特征。框架如下:
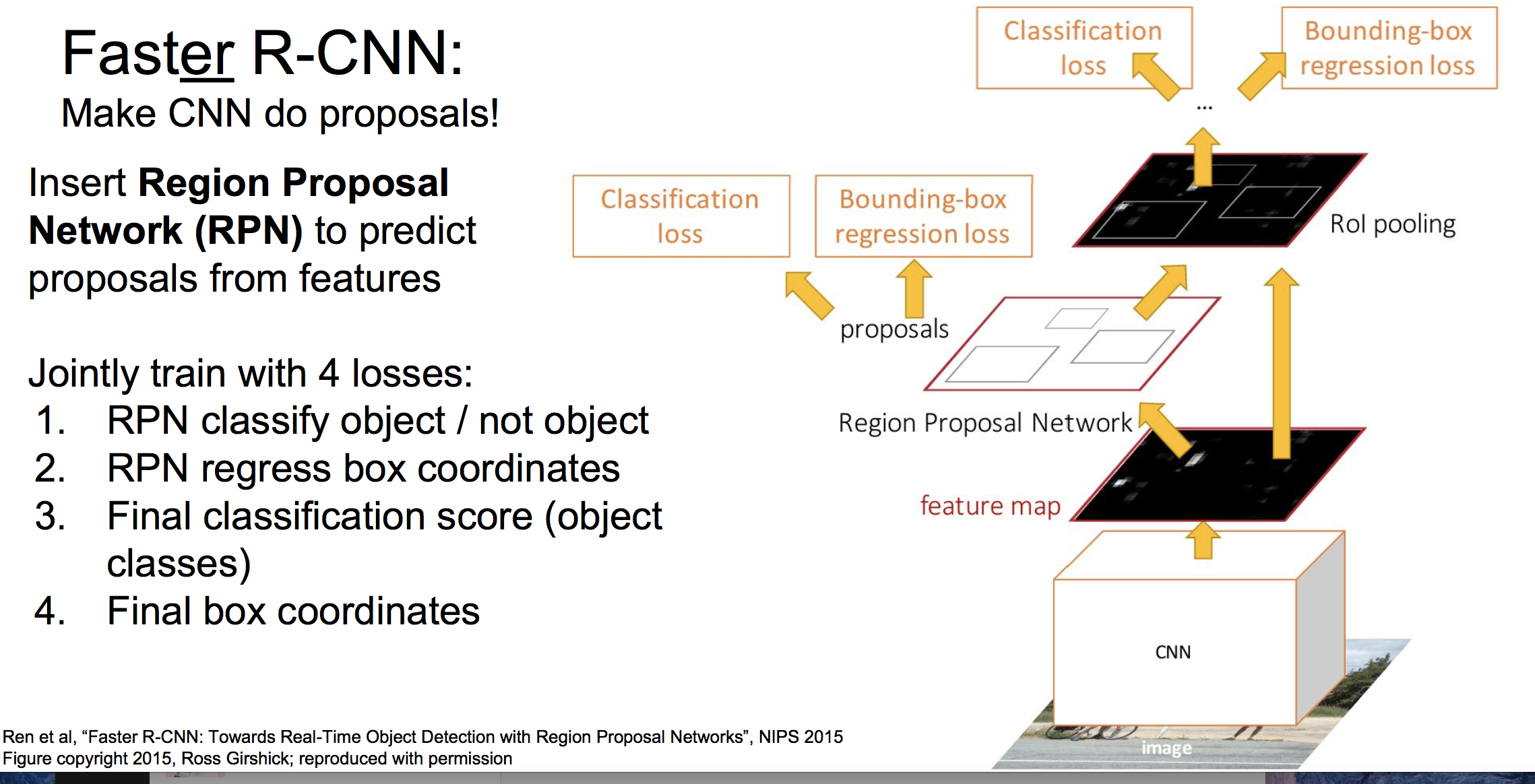
(4)Faster RCNN
Fast RCNN的性能瓶颈是SS算法选定候选区域,在Faster RCNN中,使用网络Region Proposal Network (RPN) 来预测候选区域,整体框架如下:
Faster RCNN是当前很先进的目标检测框架,要了解细节看这篇论文:
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in Neural Information Processing Systems. 2015.
(5)SSD
SSD的思想是将图像划分为很多个格子,以每个格子的中心可以衍生出若干个base boxes。使用神经网络一次性的对这些格子进行分类,对这些baseboxes进行回归。
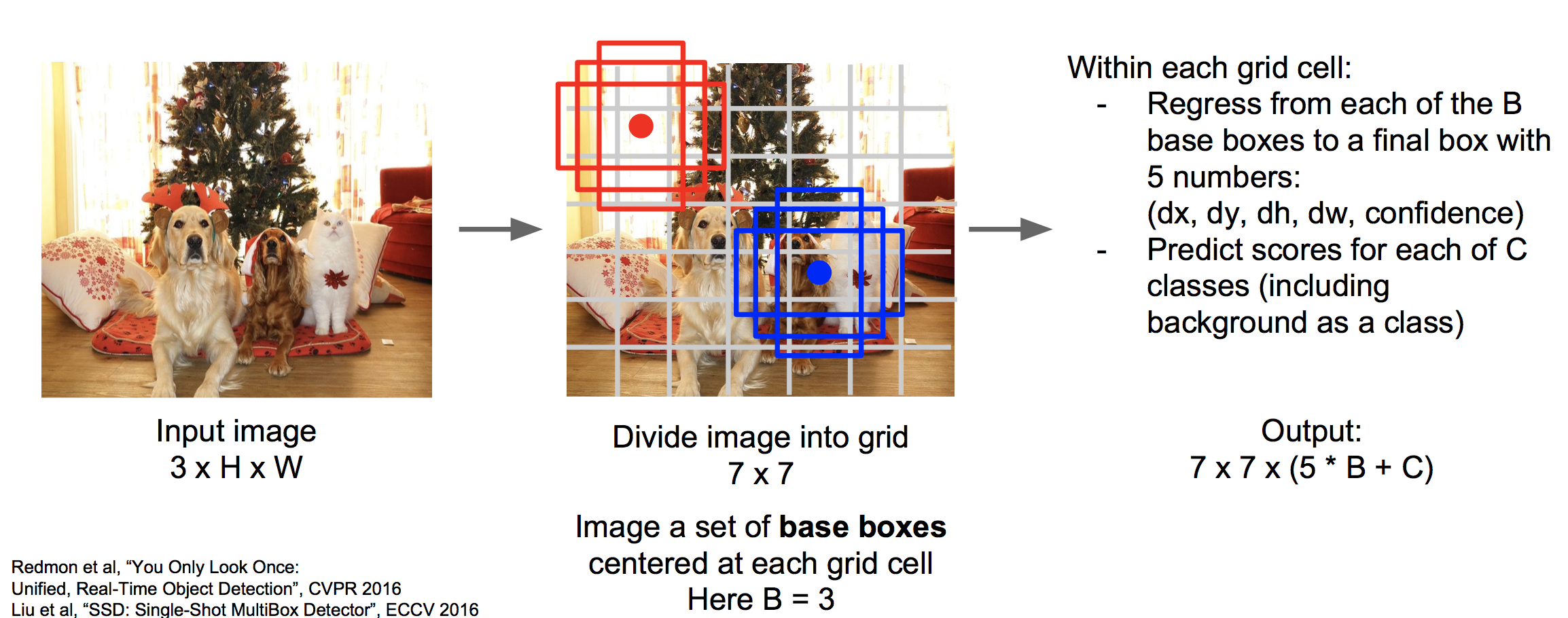
上图中,一个图像划分为7*7个grid,每个grid有3个base boxes。我们需要用回归为每个base boxes预测五个值,为每个格子进行分类打分。直接使用一个的CNN神经网络输出7*7*(5*B+C)的大小即可。
更多细节参看论文:Liu et al, “SSD: Single-Shot MultiBox Detector”, ECCV 2016
(6)各种物体检测框架的对比
有很多变量可控:

这篇论文对比了各种框架:
Huang et al, “Speed/accuracy trade-offs for modern convolutional object detectors”, CVPR 2017
FasterCNN比SSD具有更高的精度,但是没有SSD快。
(7)Dense Captioning
Dense Captioning 是对图片中的每个事物做检测,并用语言进行描述:
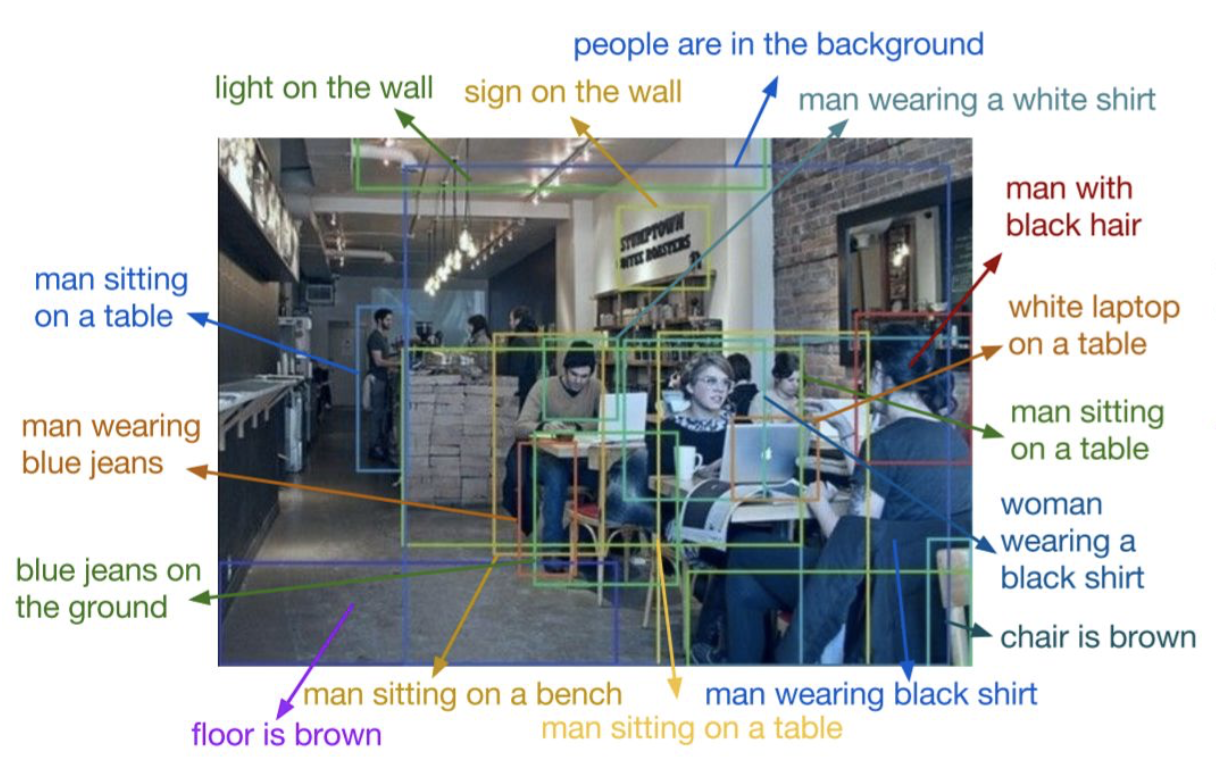
Dense Captioning其实就是Object Detection + Captioning ,其框架可以使用faster RCNN结合LSTM来做。具体参考文献:
Johnson, Karpathy, and Fei-Fei, “DenseCap: Fully Convolutional Localization Networks for Dense Captioning”, CVPR 2016
4 物体分割
物体分割要做的是在物体检测上更进一步,从像素层面把各个物体分割出来。
Mask RCNN是当前很前沿的一种方法,其将faster RCNN和语义分割结合成一个框架,具有非常好的效果!框架为:
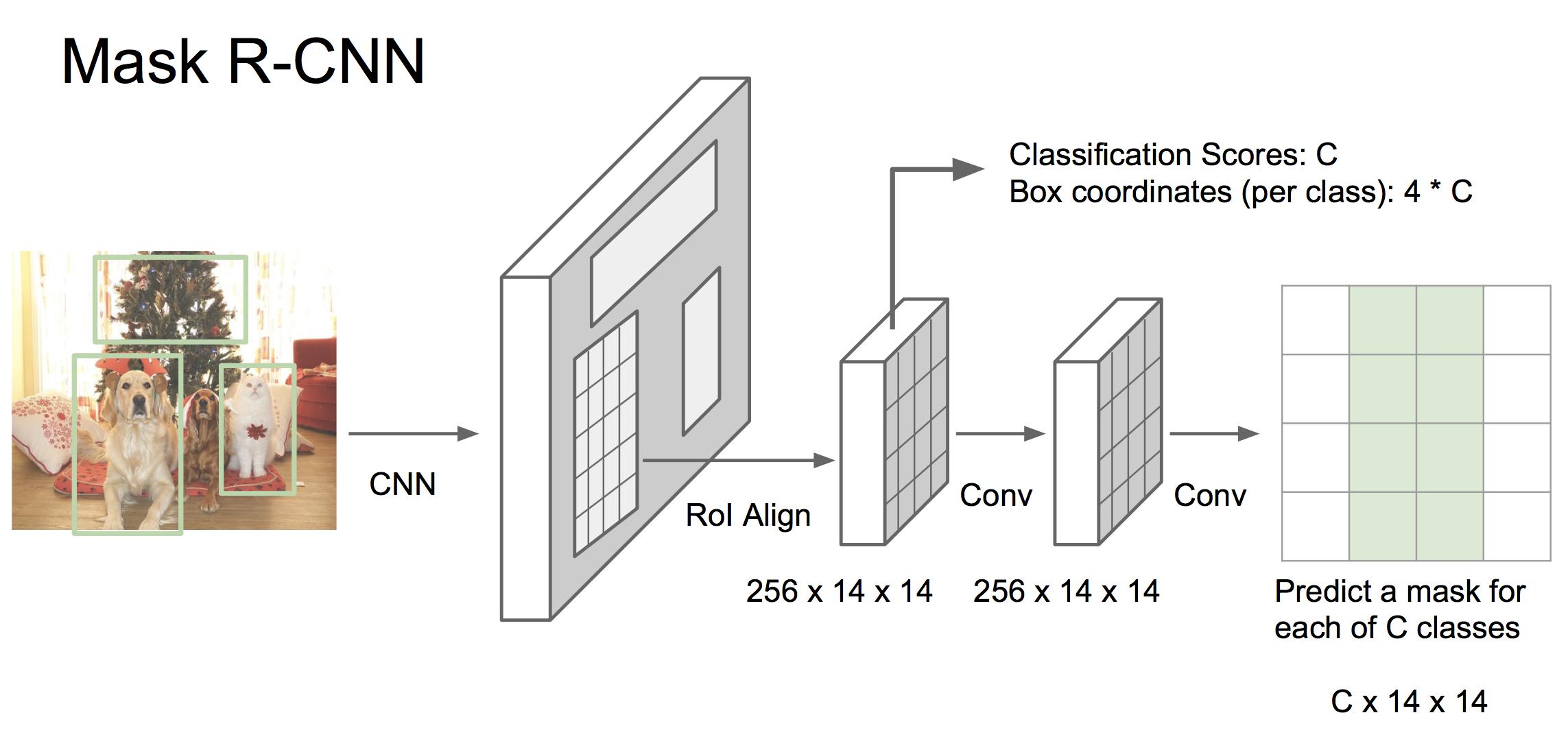
如上图,首先将图像使用CNN处理为特征,然后经过一个RPN网络生成候选区域,投射到之前的feature map。到这里与faster RCNN一样。之后有两个分支,一个分支与faster RCNN相同,预测候选框的分类和边界值,另一个分支则与语义分割相似,为每个像素做分类。
mask RCNN具有超级好的效果,有机会一定要拜读一下。

He et al, “Mask R-CNN”, arXiv 2017
5 总结
这些成功的计算机视觉框架和模型给我们的启示是,将具有基本功能的模块整合成一个可训练的端到端系统,可以完成更加复杂的功能。通过向网络中引入多个损失函数的分支,可以让其完成多目标的联合优化。