最近刷了一些题,也面试了一些公司,把关于c++中关于类的一些概念总结了一下。
在这里也反思一下,面试前信心满满自以为什么都懂,毫无准备就大胆得去了,然后就觉得自己脸都被打肿了。回来认认真真刷题,这阵子都不敢再去面试了~~。
1. 类的访问属性:public,protect,private
C++中类的成员变量和函数都带有三种属性中的一种,假如没有特别声明,那么就默认是私有的(除了构造函数)。public表示是公开的,对象可以直接调用的变量或者函数;protect表示是保护性的,只有本类和子类函数能够访问(注意只是访问,本类对象和子类对象都不可以直接调用),而私有变量和函数是只有在本类中能够访问(有个例外就是友元函数,这个后面会详细说)。
class A { public: A(int b):m_public(b),m_protected(1), m_private(2){} int m_public; protected: int m_protected; private: int m_private; }; int main( void ) { A a(10); cout<<a.m_public<<endl; //正确,可以直接调用 cout<<a.m_protected<<endl; //错误,不可以直接调用 cout<<a.m_private<<endl;//错误,不可能直接调用 }
而子类对父类的继承类型也有这三种属性,分别为公开继承,保护继承和私有继承。
class A { public: A(int b):m_public(b),m_protected(1), m_private(2){} int m_public; protected: int m_protected; private: int m_private; }; class B: public A{} //公有继承 class C: protected A{} //保护继承 class D:private A{} //私有继承
于是问题来了,父类成员的公开属性有三种,子类的继承属性也有同样的三种,那么一共就有九种搭配(例如公开继承父类公开成员,私有继承父类公开成员,保护继承父类私有成员等等)。
我们只需要记住这两个里取严格的那一种。例如私有继承父类公开成员,那么在子类里父类的所有属性都变成子类私有的了。
public继承 public protected 不可用
protected继承 protected protected 不可用
private继承 private private 不可用
class A { public: A(int b):m_public(b){} int m_public; }; class B:private A { public: B(int num):A(num){} }; int main() { B b(10); cout<<b.m_public<<endl; //错误,无法直接调用私有成员 }
2. 类的四个默认函数:构造,拷贝构造,赋值,析构(这一点要背下来,面试直接被问了)
- 每当构建一个新的类,编译器都会给每个类生成以上四个默认的无参构造函数,并且这四个函数都是默认public的。
class A { public: double m_a; }; int main( void ) { A a; //调用默认无参构造函数,此时m_a的值是不确定的,不能用 //离开主函数前调用析构函数,释放a的内存 }
但是一旦程序员自己定了带参数的构造函数,那么编译器就不会再生成默认的无参构造函数了,但是还是有默认的拷贝和赋值构造函数。因此假如只定义了有参数的构造函数,那么这个类就没有无参构造函数。
class A { public: A(int i):m_a(i){} int m_a; }; int main( void ) { A a; //错误!没有无参构造函数 A a1(5); // 调用了A中程序员定义的有参构造函数 A a2(6); // 调用了A中程序员定义的有参构造函数 A a3 = a1; //此处调用默认的拷贝构造函数 a2 = a1; //此处调用默认的赋值函数 }
上面的程序中尤其需要注意的是 A a3 = a1这一句,虽然有等号,但是仍然是拷贝构造函数。拷贝构造函数和赋值函数的区别在于等式左边的对象是否已经存在。a2 = a1这一句执行的时候,a2已经存在,因此是赋值函数,而执行A a3 = a1这一句的时候,a3还不存在,因此为拷贝构造函数。
默认的赋值和拷贝构造函数一般只是简单的拷贝类中成员的值,这一点当类中存在指针成员和静态成员变量的时候就非常危险。例如以下一种情况:
class A { public: A(int i, int* p):m_a(i), m_ptr(p){}int m_a; int *m_ptr; }; int main( void ) { int m = 10, *p = &m; A a1(3, p); A a2 = a1; //a2 和 a1的m_ptr都指向了同一地址 *p = 100; cout<<*(a2.m_ptr)<<endl; //输出为100 }
这也就是C++中由于指针带来的浅拷贝的问题,只赋值了地址,而没有新建对象。因此假如类中存在静态变量或者指针成员变量时一定要自己手动定义赋值、拷贝构造、析构函数。
class A { public: A(int i):m_a(i), m_ptr(new int(10)){} A(const A &a) //拷贝构造函数 { m_a = a.m_a; m_ptr = new int(*(a.m_ptr)); } ~A(){ assert(m_ptr!=nullptr); delete m_ptr; } int m_a; int *m_ptr; }; int main( void ) { A a1(3); A a2 = a1; //a2 和 a1的m_ptr指向了不同的地址 *a1.m_ptr = 100; cout<<*(a2.m_ptr)<<endl; //输出为10 }
- 子类会继承父类定义的构造函数吗?
可以理解成不能。子类会继承父类所有的函数,包括构造函数,但是子类的构造函数会把父类的构造函数覆盖了,所以看起来就是没有继承。假如子类不定义任何构造函数,那么子类只会默认地调用父类的无参构造函数。当父类中只定义了有参构造函数,从而不存在无参构造函数的话,子类就无法创建对象。
class A { public: A(int b):m_public(b){} int m_public; }; class B:public A { }; int main() { B b; //出错,因为父类没有无参构造函数 }
因此在这种情况必须要显示定义子类的构造函数,并且在子类构造函数中显示调用父类的构造函数。
class A { public: A(int b):m_public(b){} int m_public; }; class B:public A { public: B(int num):A(num){} }; int main() { B b1; //出错,由于父类没有无参构造函数,因此B也不存在无参构造 B b2(5); //正确 }
- 构造函数的构造顺序:先构造基类,再构造子类中的成员,再构造子类
class A { public: A(){cout<<"constructing A"<<endl;} }; class B { public: B(){cout<<"constructing B"<<endl;} }; class C:public A { public: B b; A a; int num; C(int n):num(n){cout<<"constructing C"<<endl;} }; int main() { C c(1); }
运行结果为:

第一行的constructingA就是在构建基类,然后构建b对象,再构建a对象,最后构建c本身。
而析构的顺序就正好是完全反过来,先析构子类,再析构子类中的对象,最后析构基类。
- 假如把构造函数和析构函数定义成私有的会怎样?(被问的时候真的一脸懵,-_-//)
假如把构造函数定义为私有,那么类就无法直接实例化(还是可以实例化的,只是要转个弯)。来看下面这个例子:
class A { public: int m_public; static A* getInstance(int num) { return new A(num); } private: A(int b):m_public(b){} }; int main() { A a1(4); //错误 A* pa = A::getInstance(5); //正确 }
有些时候,我们不希望一个类被过多地被实例化,比如有关全局的类、路由类等。这时候,我们就可以用这种方法为类设置构造函数并提供静态方法。
假如把类的析构函数定义为私有,那么就无法在栈中生成对象,而必须要通过new来在堆中生成对象。
另外在这里提及一点,对应的,如何让类只能在栈中生成,而不能new呢?就是将new 和delete重载为私有。
原因是C++是一个静态绑定的语言。在编译过程中,所有的非虚函数调用都必须分析完成。即使是虚函数,也需检查可访问性。因些,当在栈上生成对象时,对象会自动析构,也就说析构函数必须可以访问。而堆上生成对象,由于析构时机由程序员控制,所以不一定需要析构函数。
class A { public: int m_public; static A* getInstance(int num) { return new A(num); } A(int b):m_public(b){} private: ~A(){} }; int main() { A a(5); //错误,因为系统无法自动调用析构函数 A *p_a = new A(5); //正确,此时p_a指向的是堆中的内存 }
- 构造函数的初始化列表(就是构造函数冒号后面的东西,叫初始化列表,需要与{}中的函数内容区分开)
有几种情况必须要使用初始化列表:
常量成员
引用类型
没有默认构造函数的类类型
class A { public: int m_a; A(int num):m_a(num){} }; class B { public: const int m_const; int &m_ref; A a; B(int num, int b):m_ref(b), m_const(1), a(num) //初始化列表 { cout<<"constructing B"<<endl; } }; int main() { int n = 5; B b(1, n); }
还需要注意的一点是,初始化列表里的真正赋值的顺序其实是按照成员变量的声明顺序,而不是初始化列表中显示的顺序。例如这里是先初始化m_const,然后是m_ref,最后是a。
- 隐式转换与explicit关键字的使用
来看下面一个例子:
class A { public: int m_a; A(int num):m_a(num){cout<<"constructing A"<<endl;} }; void test(A a) { cout<<a.m_a+1<<endl; } int main() { A a1= 6; //此时等式右边的6隐式生成了一个以6为参数的A类对象 test(6); //输出7,入参也隐式生成了一个以6为参数的A类对象 cout<<a1.m_a<<endl; //输出6 }
从下面的运行结果可以看出,A的构造函数被调用了两次。
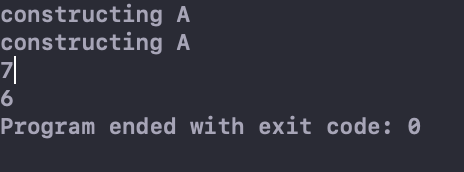
这种隐式转换有时候神不知鬼不觉,为了避免这种情况,于是有了explicit关键字。当构造函数被声明为explicit后,就必须要显式调用构造方法来生成对象了,而无法进行隐式转换。
class A { public: int m_a; explicit A(int num):m_a(num){cout<<"constructing A"<<endl;} }; void test(A a) { cout<<a.m_a+1<<endl; } int main() { A a1= 6; //错误 test(6); //错误 }
3. 虚函数
虚函数是C++实现多态的方法。 虚函数和普通函数没有什么区别,只有当用基类指针调用子类对象的方法时才能够真正发挥它的作用,也只有在这种情况下,才能真正体现出C++面对对象编程的多态性质。
先来了解一下绑定的概念。函数体与函数调用关联起来叫做绑定。
- 早绑定:早绑定发送在程序运行之前,也是编译和链接阶段。
class A
{
public:
int m_a;
A(int num):m_a(num){}
int add(int n)
{
return m_a + n;
}
};
int main()
{
A a(1);
cout<<a.add(5);
}
在上面的代码中,函数add在编译期间就已经确定了实现。这就是早绑定。所有的非虚函数都是早绑定。
- 晚绑定:晚绑定发生在程序运行期间,主要体现在继承的多态方面。
引用一句Bruce Eckel的话:“不要犯傻,如果它不是晚邦定,它就不是多态。”
class A { public: int m_a; A(int num):m_a(num){} void virtual show() { cout<<"base function"<<endl; } }; class B:public A { public: B(int n):A(n){} void show() { cout<<"derived function"<<endl; } }; int main() { A *pa = new B(1); pa->show(); //输出 derived function }
父类和子类都定义了show方法,在继承的过程中,由于父类show方法是虚函数,而父类指针指向的是子类对象,所以会在子类对象中去找show函数的实现。假如子类中没有show,那么就还是会调用父类的show。
这个晚绑定的过程是通过虚指针实现的。只要一个类中声明了有虚函数,那么编译器就会自动生成一个虚函数表。虽然名字叫表,但本质是一个存放虚函数指针的函数指针数组。一个虚表对应一个指针。当该类作为基类,其派生类对基类的(一个或者多个)虚函数进行重写时,派生类的虚函数表中,相应的函数指针的值就会发生变化。
构造函数不能声明为虚函数。虚函数是晚绑定,一定是先有了基类对象,才会有对应的虚指针,再去本类或者子类对象中去找对应的实现。所以一定要先通过构造函数创建了对象,才能去实现虚函数的作用。
而析构函数,则常常被声明为虚函数。(记得当时面试官问我,析构函数能不能是虚的,我当时斩钉截铁得回答,不能!-_-//)
先看下面这个例子。
class A
{
public:
int m_a;
A(int num):m_a(num){cout<<"constructing A"<<endl;}
~A(){cout<<"destructing A"<<endl;}
};
class B:public A
{
public:
B(int n):A(n){cout<<"constructing B"<<endl;}
~B(){cout<<"destructing B"<<endl;}
};
int main()
{
A* pa= new B(1);
delete pa;
}
执行结果为:
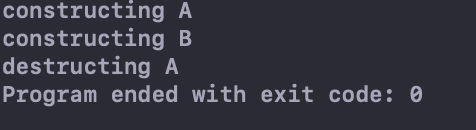
可以看到是先构建了A对象,然后构建了B对象。可是却只析构了A对象,B对象的内存空间就泄漏了。
现在把A的析构函数置为虚函数的话,
class A
{
public:
int m_a;
A(int num):m_a(num){cout<<"constructing A"<<endl;}
virtual ~A(){cout<<"destructing A"<<endl;}
};
class B:public A
{
public:
B(int n):A(n){cout<<"constructing B"<<endl;}
~B(){cout<<"destructing B"<<endl;}
};
int main()
{
A* pa= new B(1);
delete pa;
}
运行结果为:
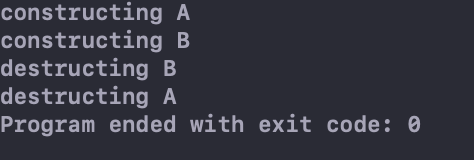
可以看到这时B对象也被析构了。这正是利用了虚函数晚绑定的特点,当调用基类指针析构函数的时候,先调用B的析构函数,再调用A的析构函数。
对于虚函数始终要注意只有用指针调用的时候才会有作用,假如只是普通的对象调用,虚函数是不起作用的。
class A { public: int m_a; A(int num):m_a(num){} virtual void show() { cout<<"A::show()"<<endl; } virtual ~A(){} }; class B:public A { public: B(int n):A(n){} void show() { cout<<"B::show()"<<endl; } ~B(){} }; int main() { A a(1); a.show(); //输出A::show() B b(1); b.show(); //输出B::show() }
4. 成员函数的重载、隐藏与覆盖
- 成员函数的重载
(1)相同的范围(在同一个类中)
(2)函数名字相同
(3)参数不同 ,也可以仅仅是顺序不同
(4)virtual 关键字可有可无
class A { public: int m_a; A(int num):m_a(num){} void show(int n){} //(1) virtual void show(int n){} //(2) 错误!!不是重载,重复定义了(1),因为virtual关键字不能重载函数 void show(double d){} //(3)show函数的重载 void show(int a, double b){} //(4)show函数的重载 void show(double b, int a){} //(5)show函数的重载 void show(int a, double b) const {} //(6)show函数的重载,const关键可以作为重载的依据 void show(const int a, double b){} //(7)错误!! 不是重载, 顶层const不可以作为重载的依据,重复定义了(6) void show(int *a){} //(8)show函数的重载 void show(const int *a){} //(9)show函数的重载,只有底层const才可以作为重载的依据 void show(int * const a){} //(10) 错误!!不是重载,重复定义了(8),因为这里也使用了顶层const };
至于const能不能成为重载的依据取决于是顶层const还是底层const。顶层const是指对象本身是常量,而底层const是指指向或引用的对象才是常量。
- 成员函数的隐藏,这里“隐藏”是指派生类的函数屏蔽了与其同名的基类函数
只要子类函数的名字与基类的相同,那么不管参数相同与否,都会直接屏蔽基类的同名函数。
class A { public: void show(int a) {cout<<"A::show()"<<endl;}//(1) }; class B:public A { public: void show(){cout<<"B::show()"<<endl;} //(2)将(1)屏蔽了 };
- 假如在子类中仍旧需要用到基类的同名函数,就要用using关键字显式声明。
class A { public: void show(int) {cout<<"A::show()"<<endl;} }; class B:public A { public: using A::show; void show(){ show(0); //一定要在前面显式声明using A中的show函数,否则此句会编译错误 cout<<"B::show()"<<endl; } }; int main() { B b; b.show(); }
输出结果为:

- 成员函数的覆盖
(1)不同的范围(分别位于派生类与基类)
(2)函数名字相同
(3)参数相同
(4) 基类函数必须有virtual 关键字
这其实就是多态的实现过程。注意参数必须要完全一致。之前讲过,在此不再赘述。
5. inline关键字
定义在类中的成员函数默认都是内联的。内联函数和普通函数的区别在于:当编译器处理调用内联函数的语句时,不会将该语句编译成函数调用的指令,而是直接将整个函数体的代码插人调用语句处,就像整个函数体在调用处被重写了一遍一样。这有助于提高程序的运行效率。但是要注意inline函数仅仅是一个对编译器的建议,所以最后能否真正内联,看编译器的意思,它如果认为函数不复杂,能在调用点展开,就会真正内联,并不是说声明了内联就会内联,声明内联只是一个建议而已。
这也是为什么虚函数可以是内连函数。因为仅仅是建议,当虚函数需要表现出多态性质的时候,编译器会选择不内连。
6. 友元函数、友元类
类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。
class A { public: A(int n):m_a(n){} friend class B; //声明B为A的友元类 private: int m_a; }; class B { public: B(A a){cout<<a.m_a<<endl;} //由于B是A的友元类,所以可以直接调用a的私有m_a成员 }; int main() { A a(1); B b = B(a); //输出1 }
要注意尽管友元类很强大,但是友元类和类本身并没有任何继承关系和成员关系。友元类或友元函数都不是本类的成员类和成员函数。
就如名字定义的那样,只是朋友,不具有任何亲属关系,因此无法使用this指针进行调用。
友元函数常用在重载运算符。因为通常重载运算符的时候都要用到私有变量,所以用友元函数来重载是非常合适的。
7. 运算符的重载
- 首先要明确,有6个运算符是不可以被重载的。
. (成员访问运算符)
.*, ->* (成员指针访问运算符)
:: (域运算符)
sizeof (长度运算符)
?: (条件运算符)
# (预处理符号)
- =, [] ,() ,-> 四个符号只能通过成员函数来重载,不能通过友元函数来定义
=,->, [], () 为什么不能重载为友元函数,是因为当编译器发现当类中没有定义这4个运算符的重载成员函数时,就会自己加入默认的运算符重载成员函数。而如果这四个运算符写成友元函数时会报错,产生矛盾。
- 不允许用户定义新的运算符作为重载运算符,不能修改原来运算符的优先级和结合性,不能改变操作对象等等限制
- 重载原则如下:
如果是一元操作,就用成员函数去实现
如果是二元操作,就尽量用友元函数去实现
如果是二元操作,但是对两个操作对象的处理不同,那么就尽可能用成员函数去实现
- 运算符的重载
class A { public: A(int n):m_a(n){} int m_a; friend A operator+(A const& a1, A const & a2); }; A operator+(A const& a1, A const & a2) { A res(0); res.m_a = 1 + a1.m_a + a2.m_a; return res; } int main() { A a1(1), a2(2); A a3 = a1 + a2; cout<<a3.m_a; //输出4 }
8. 再谈const关键字
- 常量指针指向常对象, 常对象只能调用其常成员函数
class A { public: A(int n):m_a(n){} int m_a; void show(){cout<<"A::show()"<<endl;} }; int main() { A a1(1); const A a2(2); a1.show(); //正确 a2.show(); //错误 }
假如增加const函数后,就可以正常运行。
class A { public: A(int n):m_a(n){} int m_a; void show(){cout<<"A::show()"<<endl;} void show() const{cout<<"A::show() const"<<endl;} }; int main() { A a1(1); const A a2(2); a1.show(); //正确 输出A::show() a2.show(); //正确 输出A::show() const,自动调用const函数 }
- A const* 和const A*等价,允许用A* 赋值A const*,但是不允许用A const* 赋值A*
class A { public: A(int n):m_a(n){} int m_a; void changeValue(int *p){cout<<"changeValue"<<endl;} void changeValue2(int const *p){cout<<"changeValue2"<<endl;} }; int main() { int n = 10; int const *p_n_const = &n; int *p_n = &n; A a(1); a.changeValue(p_n_const); //错误,无法把int const*类型,转成int *类型,但是反之可以 a.changeValue2(p_n); //正确,输出changeValue2 }
这是因为形参const A*表示指向的对象不能改变,所以如果传入A*实参,只要不改变对象的值就不会有问题。但是如果形参为A*,则有可能改变A*指向的对象,这是const A*办不到的,所以编译器不允许传入const A*作为实参传入。
暂时总结到这里。正好最近工作中也写了不少类的继承,也实现了一些类的封装,所以这里也包含了我踩过的一些坑。
参考:
https://github.com/huihut/interview
https://blog.csdn.net/zbc415766331/article/details/83826953
https://www.cnblogs.com/darrenji/p/3907448.html
https://blog.csdn.net/IOT_SHUN/article/details/79674323
https://blog.csdn.net/liuboqiang2588/article/details/82260841
https://blog.csdn.net/weixin_42205987/article/details/81569744
https://blog.csdn.net/cb673335723/article/details/81231974