18-Hive的基本操作-分组和多表连接


========================================================================================================================================================
19-Hive的基本操作-排序

===========================================================================================================================================================
20-Hive的基本操作-内置函数

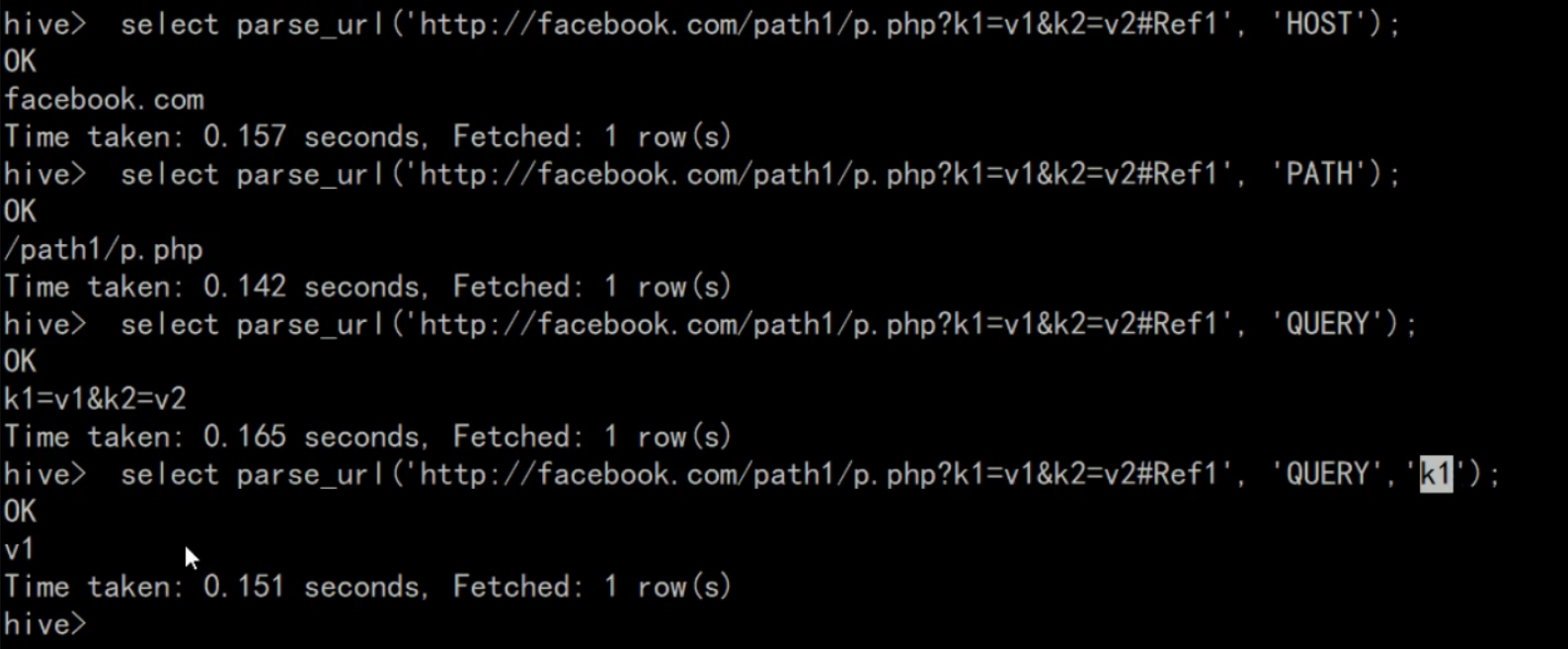
=============================================================================================================================================
21-Hive的基本操作-自定义函数
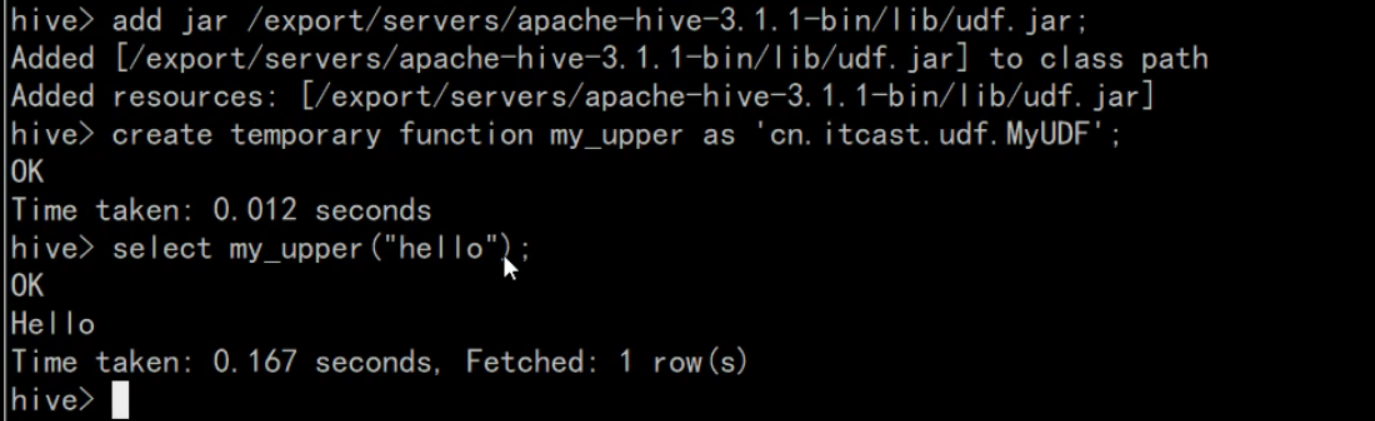
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xuejj</groupId>
<artifactId>hive_udf</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<!-- hive执行器 -->
<artifactId>hive-exec</artifactId>
<version>3.1.1</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
-------------------------------------------------------------------------------------------------------------------------------
MyUDF.java
package cn.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
/**
* 自定义一个函数: upper -->my_upper
*
*/
public class MyUDF extends UDF{
public Text evaluate(final Text str) {
//将输入字符串的第一个字母转为大写
if (str!=null&&!str.toString().equals("")) {
String str2=str.toString().substring(0,1).toUpperCase()+str.toString().substring(1);
return new Text(str2);
}
return new Text("");
}
}