XLNet模型浅析
前面介绍的BERT在nlp预训练中的表现已经让人很惊艳了,不过在之后出来的XLNet却更是青出于蓝,从论文的结果来看,XLNet在问答、文本分类、自然语言理解等任务上大幅超越BERT,再次刷新了人们的认知,本文将主要介绍XLNet模型较之前的模型的创新之处。
1.AR与AE模型
首先介绍两种语言模型:
1.自回归语言模型(Autoregressive LM,AR)
AR的思路很简单,对于一个文本序列,AR单方向地逐个进行预测,也就是最大化概率
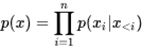
可以看出,这就是传统的单向语言模型(Language Model, LM)。这样的模型缺点很明显,就是只能看到单方向的信息(上文或下文),不过这种单方向的模式更加适用于一些生成类的nlp任务,因为这些任务在生成内容的时候就是从左到右的,这和AR的模式天然匹配。
2.自编码语言模型(Autoencoder LM,AE)
BERT采用了不同于AR的模式——随机mask掉一些单词,训练过程就是根据上下文对这些单词做预测最大化,而这个其实就是(Denoising Autoencoder ,DAE)的典型思路。那些被Mask掉的单词就是加入的噪音,BERT就可以认为是对其“去噪”。这样的做的好处就是能够结合上下文的信息,但是由于在预训练过程中额外地加入了[Mask]标记,这就导致了预训练和后面的微调阶段的数据的不一致。
相比较于AR,采用了AE模型的BERT具有利用到双向上下文信息的优点,但是这样也导致了一些问题的出现,一个是预训练和微调阶段的不一致;另一个是BERT模型有一个假设并不符合实际情况,它认为所有的[Mask]之间是相互独立的,举一个例子,对于“自然语言处理”这句话,假设BERT的输入是“自然语言[Mask] [Mask]”,那么BERT要优化的概率就是P(处|自然语言)×P(理|自然语言),而对于传统LM来说,则应是P(处|自然语言)×P(理|自然语言处),我们可以看出BERT忽略了[Mask]之间的相关性。
2.Permutation Language Modeling
既然两种模型都有各有所长,那么能不能用一个模型将两者的优点结合起来呢?而这就是XLNet的出发点,它在实现双向Transformer编码的同时,还能够避免BERT所产生的那些问题。它基于AR模型,采用了一种全新的方法叫做Permutation Language Modeling,先简单说一下流程,因为采用的是AR的模式,因此它是从左向右的输入,也就是说只能看到预测单词的上文,而我们希望在看到的上文中能够出现下文单词,这样就能在只考虑上文的情况下实现双向编码,为了到达这样的效果,XLNet将句子中的单词随机打乱顺序,这样的话对于单词xi,它原先的上下文单词就都有可能出现在当前的上文中了,如下图所示,对于单词x3,改变原先1、2、3、4的排列组合,它的上文中就可能出现x4,这是虽然模型只考虑上文,但是却包含了原先上下文的信息。不过在实际微调中我们不能直接去改变原始输入,输入的顺序还应该是1234,所以顺序的改变应该发生在模型内部,这就用要Attention mask机制,通过乘以一个mask矩阵的方式来改变序列中单词的顺序。
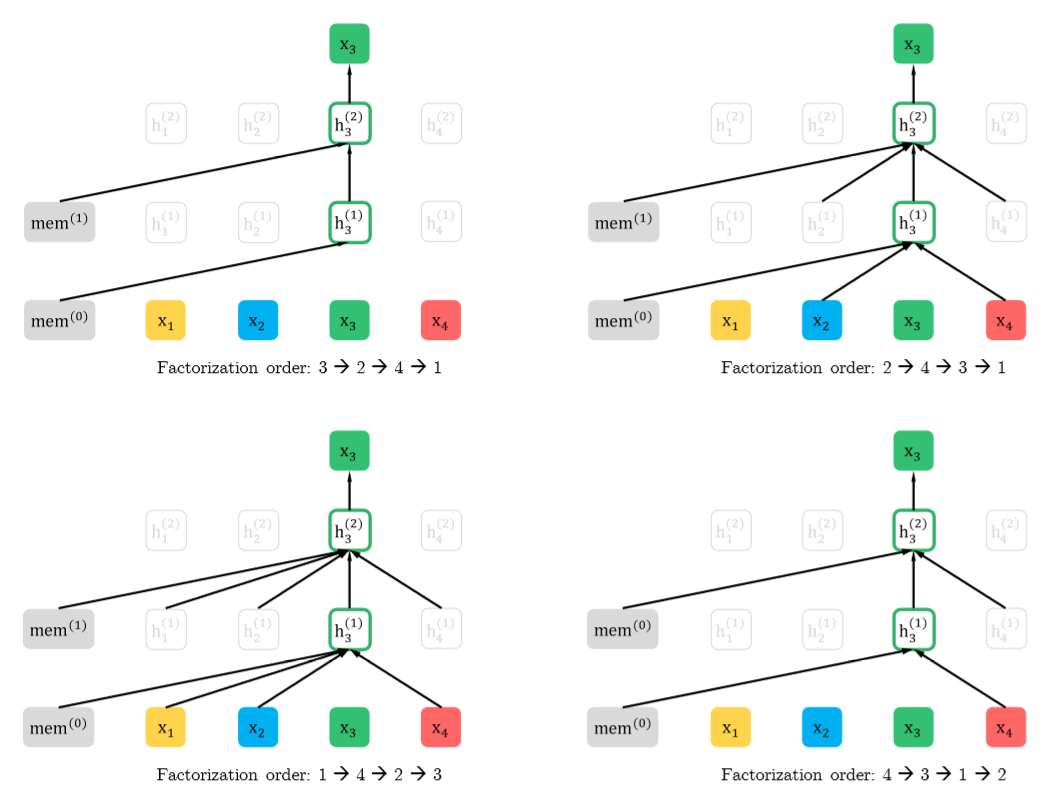 Permutation Language Modeling
Permutation Language Modeling
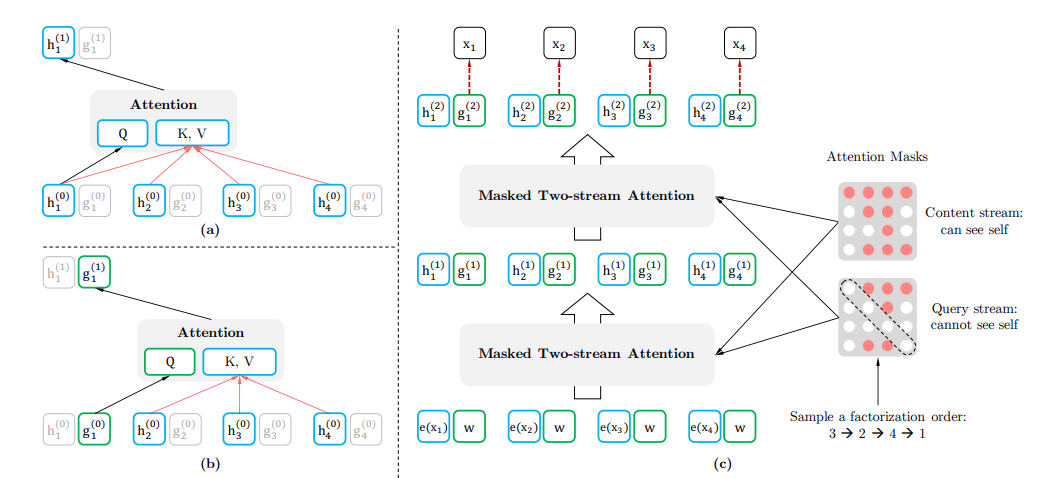
3.Two-Stream Self-Attention
在改变了顺序以后,模型又产生了新的问题,那就是不知道要预测句子中的哪一个单词,这种问题在传统的AR模型中是不存在的,因为AR预测的永远是序列的下一个位置的单词,但是对于单词顺序被打乱的XLNet,我们无法根据上文知道要预测的是哪一个位置的单词。具体来说,对于句子[x1,x2,x3,x4],打乱顺序后对第三个位置进行预测,得到的上文信息是x2,x4,可是我们却并不知道要预测的是哪一个单词,若打乱后顺序为2413,那就是x1,若是2431,就变为x3,所以只根据上文x2,x4无法准确预测出某一个单词,为了解决这个问题,XLNet引入了Two-Stream Self-Attention机制。
为了解决上面出现的预测目标无法确定的问题,预测时需要在输入上文信息(如x2,x4)的基础上,额外再输入预测目标的位置信息(如位置z3=1),这样就可以确定预测的目标了,可以将其记为 或
;不过仅仅有
还不够,在attention中还需要计算句子中各个位置之间的相关性,对于比t更靠后的位置j上的单词,现在计算j和t的相关性,如果计算的是
和
,那么就有信息上的浪费,因为对于j上的单词,它是可以知道的,为了能够提供全部的上下文信息,这时的
中应该加入
,将其记为
或
,计算的是
和
之间的相关性。
为了解决问题,模型设计了两个self-attention的stream,如下所示
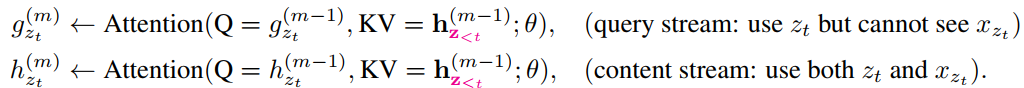
现在结合下图来介绍Two-Stream Self-Attention的流程,输入单词顺序为1234的序列,先进行初始化, ,e(x)为word embedding的值,而
,其中w是一个可训练的参数;现在考虑单词x1,通过乘以attention masks矩阵的方式(如下图右侧所示)将其“重新排列”为3241,则x1位于最后,则x1能看到它的上文(对于Content Stream是x3、x2、x4、x1;对于Query Stream是x3、x2、x4),然后就通过上面的attention公式进行计算,通过Two-Stream Self-Attention分别得到
和
,然后重复多层后,通过
计算得到预测概率,如下公式所示:
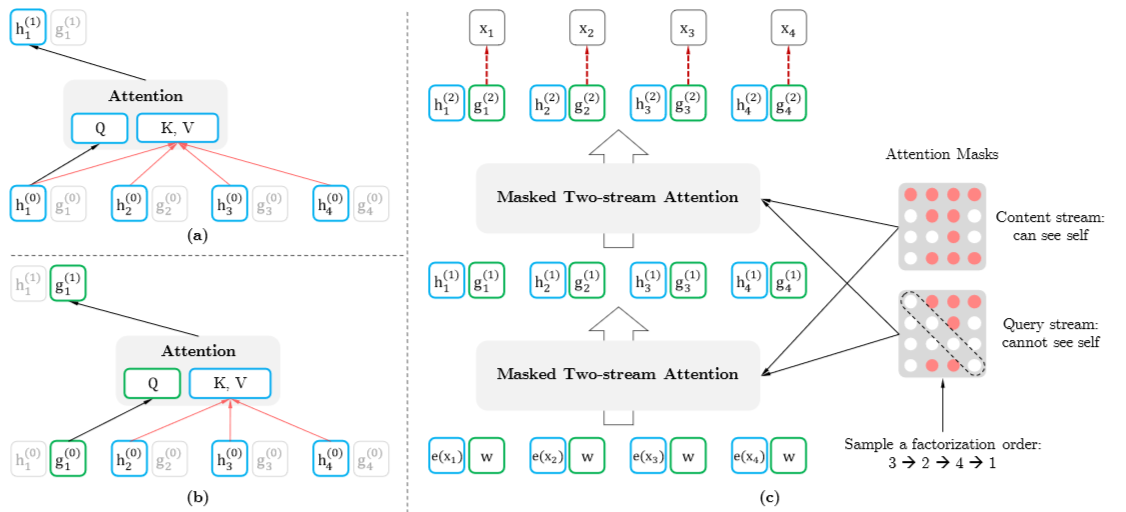 Two-Stream Self-Attention
Two-Stream Self-Attention
这里说一下个人对于Query和Content Stream的理解,Query Stream的目的就是为了预测,它用到的信息都是上下文信息,没有涉及到任何关于预测单词内容的信息,它通过Transformer不断地提取预测单词上下文的特征,最终根据特征信息得到一个预测结果;而对于Content Stream,它是一个标准的Transformer特征提取器,由于Query Stream的 缺少单词xi的内容信息,所以Content Stream存在的目的就是为Query Stream提供完备的信息
,这就有助于Content Stream更好地提取出有关于预测单词上下文的特征。
另外,其实对于排列在比较靠前位置的单词,它的上下文单词数量较少,预测难度较大, 因此XLNet只做部分预测,比如说只预测后1/K个单词,这样可以加快模型收敛速度。
4.引入Transformer-XL
从名字就可以看出来,XLNet利用了Transformer-XL,以此来获得更长距离的单词依赖关系,Transformer-XL的详细内容可以参见之前的总结,这里说一下它在XLNet的用法,将一个长序列分成两个片段, ,将它们分别被重新排列,首先对于片段
,利用Content Stream可以得到
,那么对于片段
,
可计算为:
其中[* , *]表示将两个序列沿维度相连
这样 就包含了更长距离的上下文信息,进而Query Stream也就可以从更长的上下文中提取特征,在长文档中的效果也就会更好。
5.Modeling Multiple Segments
最后还有一点内容是关于序列之间建模,上面的内容都是关于序列中的单词之间的关系,而nlp中还有一些下游任务是在句子层级上的,在BERT中是通过Next Sentence Prediction的方法来进行适应的,而XLNet论文经过研究后认为Next Sentence Prediction对其没有什么帮助,因此XLNet提出了Relative Segment Encoding,这个可以说借鉴了Transformer-XL中相对位置的思想,只判断两个单词是否在同一个segment中,而不是判断它们各自属于哪个segment。
总结
XLNet模型可以说是现在预训练模型中的一个集成之作,它通过Permutation Language Modeling巧妙地将LM与BERT模型中各自的优点结合了起来,再加上引入的Transformer-XL和Relative segment encoding等技术,使得XLNet在模型表现上更上一层楼,特别是对于BERT表现欠佳的生成式任务,XLNet的表现会更加突出。
参考资料
[1] XLNet: Generalized Autoregressive Pretraining for Language Understanding
文章被以下专栏收录
推荐阅读

【NLP】XLNet粗读

BERT大火却不懂Transformer?读这一篇就够了
nlp中的Attention注意力机制+Transformer详解

3 条评论
解释的逻辑不通啊
相比较于AR,采用了AE模型的BERT具有利用到双向上下文信息的优点,但是这样也导致了一些问题的出现,一个是预训练和微调阶段的不一致;另一个是BERT模型有一个假设并不符合实际情况,它认为所有的[Mask]之间是相互独立的,举一个例子,对于“自然语言处理”这句话,假设BERT的输入是“自然语言[Mask] [Mask]”,那么BERT要优化的概率就是P(处|自然语言)×P(理|自然语言),而对于传统LM来说,则应是P(处|自然语言)×P(理|自然语言处),我们可以看出BERT忽略了[Mask]之间的相关性。
预训练和微调阶段的不一致?