软件工程 作业二
1.码云项目地址
https://gitee.com/cxf1404445126/PersonalProject-Java/tree/master
2.PSP表格
| PSP2.1 | 个人开发流程 | 预估耗费时间(分钟) | 实际耗费时间(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| · Estimate | 明确需求和其他相关因素,估计每个阶段的时间成本 | 30 | 40 |
| Development | 开发 | 600 | 680 |
| · Analysis | 需求分析 (包括学习新技术) | 60 | 100 |
| · Design Spec | 生成设计文档 | 60 | 50 |
| · Design Review | 设计复审 | 30 | 15 |
| · Coding Standard | 代码规范 | 30 | 15 |
| · Design | 具体设计 | 100 | 80 |
| · Coding | 具体编码 | 180 | 180 |
| · Code Review | 代码复审 | 30 | 20 |
| · Test | 测试(自我测试,修改代码,提交修改) | 70 | 180 |
| Reporting | 报告 | 80 | 90 |
| · | 测试报告 | 30 | 30 |
| · | 计算工作量 | 20 | 20 |
| · | 并提出过程改进计划 | 30 | 40 |
3.解题思路描述
- 首先当然先选择好语言,嗯…Java无疑了。
- 下一步是理清题目中需要用到编程方面的知识点。
- 很明显要求的重点是通过文本文件对其进行统计,那就是要考虑Java中关于文件的应用了;
- 其次是对读取字符进行统计,包括大小写、单词等要求,那想来要用到到字符串匹配判断方面的知识点;
- 接着统计好的单词要进行分类存放,使用什么呢,Map?List?Set?嗯都先记下来好了,等到要使用的到了再根据具体情况决定。
- 大概总结完知识点,然后是开始进行类的划分,确定一下开始的方向。
- 最后就是根据划分出的组织顺序开始代码的编写,至于资料,一般是等到需要用到的时候直接在网上进行查找,个人感觉这样目的性比较明确,效率会高一些。
4.设计实现过程
一、相关类设计
- WordDeal类,用于存放统计字符数、行数、单词数、词频等方法。
- FileDeal类作为文件处理类,用于读取文件内容以及写入文件。
- Main类,调用上面两个类的方法,实现具体功能。
- Test类,用于进行单元测试。
二、相关函数设计
-
FIleDeal类中的方法
- FileToString方法实现读取一个文件,并且返回文件内容,保存在一个字符串中。
- WriteToFile方法实现把统计结果写入指定文件。
-
WordDeal类中的方法
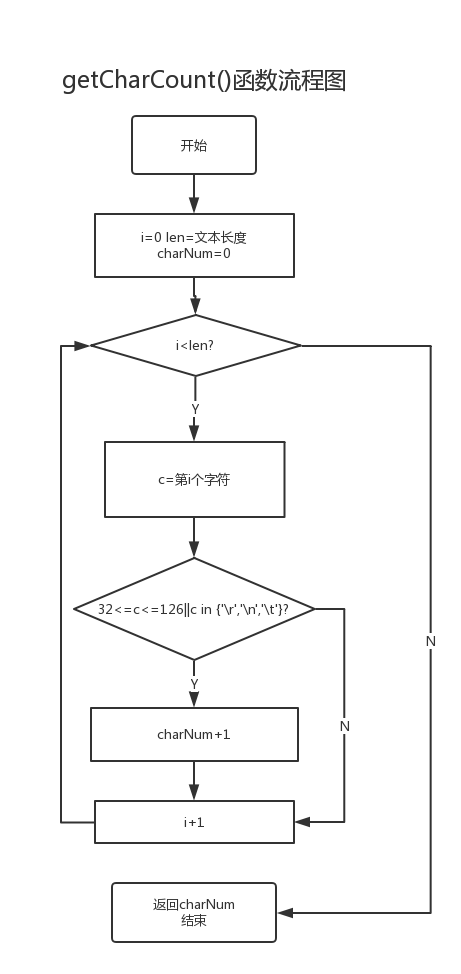
- getCharCount()方法实现统计字符数。
- getLineCount()方法实现计算行数。
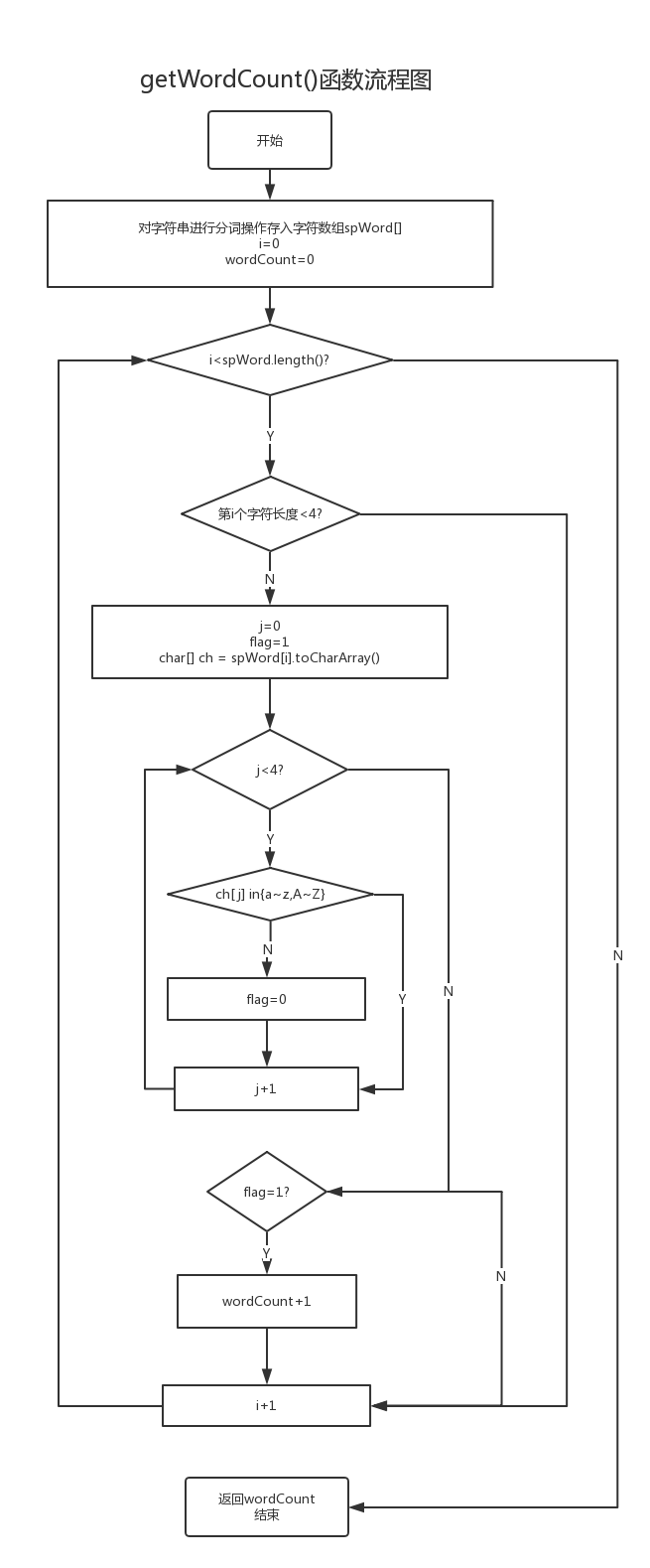
- getWordCount()方法实现计算单词数。
- getWordFreq()方法实现统计每一个单词的词频。
- sortMap()方法实现对Map中的数据进行排序,先按词频数后按字典顺序。
- ListToArray()方法实现取出词频数前十的数据。
-
关键函数流程图


5.代码说明
1. getCharCount()函数
public int getCharCount() // 统计文件字符数(ascll码(32~126),制表符,换行符,)
{
char c;
for (int i = 0; i < text.length(); i++) {
c = text.charAt(i);
if (c >= 32 && c <= 126 || c == '
' || c == '
'|| c == ' ') {
charNum++;
}
}
return charNum;
}
这个函数是用于统计字符的数量,主要实现方法就是将逐个字符进行遍历,判断它是否在有效字符内,若为有效字符则进行记录。
2. getWordCount()函数
public int getWordCount() // 统计单词总数(单词:以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。)
{
String t = text;
t = t.replace('
', ' ');
t = t.replace('
', ' ');
t = t.replace(' ', ' ');
String[] spWord = t.split(" +"); // 对字符串进行分词操作
for (int i = 0; i < spWord.length; i++) {
if (spWord[i].length() < 4) { // 判断长度是否大于等于4
continue;
} else {
int flag = 1; // 判断字符串的前四位是否是英文字母
char[] ch = spWord[i].toCharArray();
for (int j = 0; j < 4; j++) {
if (!(ch[j] >= 'A' && ch[j] <= 'Z' || ch[j] >= 'a' && ch[j] <= 'z')) {
flag = 0;
}
}
if (flag == 1) {
wordCount++;
}
}
}
return wordCount;
}
这个函数是用于判断单词的个数,因为文件中存在换行符制表符等分割符,所以方便分割字符,先统一将它们都替换成了空格,然后以空格为标志进行分割,接着按照单词的要求进行单词的判断即可。
3. getLineCount()函数
public int getLineCount() { // 统计有效行数
String[] line = text.split("
"); // 将每一行分开放入一个字符串数组
for (int i = 0; i < line.length; i++) { // 找出无效行,统计有效行
if (line[i].trim().length() == 0)
continue;
ValidLine = ValidLine + 1;
}
return ValidLine;
}
该函数用于统计有效行数,只需要将文件的每一行进行分割,存入字符数组,然后判断有无空行,即对应的字符去掉空格后长度是否为0,然后记录下有效行数并返回。
4. getWordFreq()函数
public Map getWordFreq() // 统计单词词频(单词:以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。)
{
wordFreq = new HashMap<String, Integer>();
String t = text;
t = t.replace('
', ' ');
t = t.replace('
', ' ');
t = t.replace(' ', ' ');
String[] spWord = t.split(" +"); // 对字符串进行分词操作
for (int i = 0; i < spWord.length; i++) {
if (spWord[i].length() < 4) { // 判断长度是否大于等于4
continue;
} else {
// System.out.println(spWord[i]+" "+spWord[i].length());
int flag = 1; // 判断字符串的前四位是否是英文字母
char[] ch = spWord[i].toCharArray();
for (int j = 0; j < 4; j++) {
if (!(ch[j] >= 'A' && ch[j] <= 'Z' || ch[j] >= 'a' && ch[j] <= 'z')) {
flag = 0;
}
}
if (flag == 1) { // 将字符串转化为小写
spWord[i] = spWord[i].trim().toLowerCase();
if (wordFreq.get(spWord[i]) == null) { // 判断之前Map中是否出现过该字符串
wordFreq.put(spWord[i], 1);
} else
wordFreq.put(spWord[i], wordFreq.get(spWord[i]) + 1);
}
}
}
return wordFreq;
}
该函数用于单词词频的统计,之前的部分先按照单词的判断方法进行判断一个词是否是单词,然后使用一个Map进行存储,具体方法为先判断Map中之前是否存过该数据,若没有存过,则将其存入并置value值为1,若存过,则将该值的value值加1。
5. sortMap()函数
public List sortMap(Map wordCount) { // 对单词词频的Map进行排序
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(wordCount.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) { //对Map中内容进行排序,先按词频后按字典顺序
if (o1.getValue() == o2.getValue()) {
return o1.getKey().compareTo(o2.getKey());
}
return o2.getValue() - o1.getValue();
}
});
return list;
}
这个函数用于对Map词频进行排序,这里使用了Map类型的List来存放词频信息,然后通过重写Comparator以及排序函数来实现相应要求的排序,最后返回排完序的List。
6.单元测试
这次的单元测试使用了Junit4,因为数量以及相似关系,仅展示WordDeal类中的一个函数的相关测试。
-
这里采用的是白盒测试法进行测试,白盒法考虑的是测试用例对程序内部逻辑的覆盖程度,要求是要尽可能的使其覆盖程度更大一些。
-
对于白盒法的覆盖标准有如下几个:
语句覆盖:是一个比较弱的测试标准,它的含义是:选择足够的测试用例,使得程序中每个语句至少都能被执行一次。它是最弱的逻辑覆盖,效果有限,必须与其它方法交互使用。
判定覆盖(也称为分支覆盖):执行足够的测试用例,使得程序中的每一个分支至少都通过一次。判定覆盖只比语句覆盖稍强一些,但实际效果表明,只是判定覆盖,还不能保证一定能查出在判断的条件中存在的错误。因此,还需要更强的逻辑覆盖准则去检验判断内部条件。
条件覆盖:执行足够的测试用例,使程序中每个判断的每个条件的每个可能取值至少执行一次;条件覆盖深入到判定中的每个条件,但可能不能满足判定覆盖的要求。
判定/条件覆盖:执行足够的测试用例,使得判定中每个条件取到各种可能的值,并使每个判定取到各种可能的结果。判定/条件覆盖有缺陷。从表面上来看,它测试了所有条件的取值。但是事实并非如此。往往某些条件掩盖了另一些条件。会遗漏某些条件取值错误的情况。为彻底地检查所有条件的取值,需要将判定语句中给出的复合条件表达式进行分解,形成由多个基本判定嵌套的流程图。这样就可以有效地检查所有的条件是否正确了。
条件组合覆盖:执行足够的例子,使得每个判定中条件的各种可能组合都至少出现一次。这是一种相当强的覆盖准则,可以有效地检查各种可能的条件取值的组合是否正确。它不但可覆盖所有条件的可能取值的组合,还可覆盖所有判断的可取分支,但可能有的路径会遗漏掉。测试还不完全。
1. getCharCount()函数
根据上面的函数流程图,设计了以下四个文件,使其尽可能的覆盖所有的分支。
** 测试数据:**
- text1.txt:空文件 字符数为0
- text2.txt:纯中文文件 字符数为0
- text3.txt:纯英文文件字符数为80
- text4.txt:包含了英文、中文、回车换行符、制表符的文件字符数为73
测试代码:
@Test
public void testGetCharCount() throws IOException {
FileDeal fd = new FileDeal();
String text1 = fd.FileToString("text/text1.txt");
String text2 = fd.FileToString("text/text2.txt");
String text3 = fd.FileToString("text/text3.txt");
String text4 = fd.FileToString("text/text4.txt");
WordDeal wd1 = new WordDeal(text1);
WordDeal wd2 = new WordDeal(text2);
WordDeal wd3 = new WordDeal(text3);
WordDeal wd4 = new WordDeal(text4);
int cn1 = wd1.getCharCount();
int cn2 = wd2.getCharCount();
int cn3 = wd3.getCharCount();
int cn4 = wd4.getCharCount();
assertEquals(0, cn1);
assertEquals(0, cn2);
assertEquals(80, cn3);
assertEquals(73, cn4);
}
各个函数的测试结果:
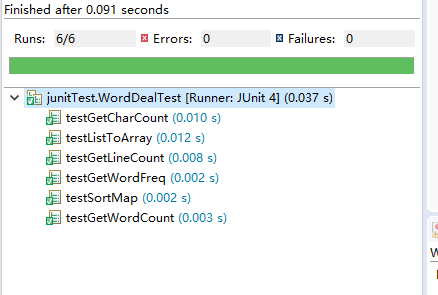
2. 分支覆盖率截图:

7.效能分析
效能分析中选用了一篇大小为2MB左右的英文小说,在测试代码中重点测试了字符串处理类中的五个函数的运行时间。性能测试的代码如下:
public class Perf_analy {
FileDeal fd;
String text1;
WordDeal wd1;
Map<String, Integer> wf1;
List lis1;
@Before
public void setUp() throws Exception { // 初始化数据
fd = new FileDeal();
text1 = fd.FileToString("LittlePrince.txt");
wd1 = new WordDeal(text1);
wf1 = wd1.getWordFreq();
lis1 = wd1.sortMap(wf1);
}
@Test
public void testGetCharCount() throws IOException { // 测试统计字符数量函数
long startTime = System.currentTimeMillis();
wd1.getCharCount();
long endTime = System.currentTimeMillis();
System.out.println("getCharCount函数的运行时间为" + (endTime - startTime) + "毫秒");
}
@Test
public void testGetWordCount() throws IOException { // 测试统计单词数量函数
long startTime = System.currentTimeMillis();
wd1.getWordCount();
long endTime = System.currentTimeMillis();
System.out.println("getWordCount函数的运行时间为:" + (endTime - startTime) + "毫秒");
}
………………
………………
………………
}
最后运行得到的每个函数的运行时间如下图所示:

可以看出相比于其他函数,统计单词个数的函数的运行时间要多得多。于是查看相应函数进行效能的改进:
public int getWordCount() // 统计单词总数(单词:以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。)
{
String t = text;
t = t.replace('
', ' ');
t = t.replace('
', ' ');
t = t.replace(' ', ' ');
String[] spWord = t.split(" +"); // 对字符串进行分词操作
for (int i = 0; i < spWord.length; i++) {
if (spWord[i].length() < 4) { // 判断长度是否大于等于4
continue;
} else {
int flag = 1; // 判断字符串的前四位是否是英文字母
char[] ch = spWord[i].toCharArray();
for (int j = 0; j < 4; j++) {
if (!(ch[j] >= 'A' && ch[j] <= 'Z' || ch[j] >= 'a' && ch[j] <= 'z')) {
flag = 0;
}
}
if (flag == 1) {
wordCount++;
}
}
}
return wordCount;
}
对于上面代码,在改进时考虑到在分词操作时可以使用\s来进行空白字符的匹配,这样就可以省去使用replace()函数所需要的时间,再一个就是在循环判断前四个字符是否为英文时使用了效率更高charAt代替了toCharArray(),改进后的代码如下:
public int getWordCount() // 统计单词总数(单词:以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。)
{
String t = text;
String[] spWord = t.split("\s"); // 对字符串进行分词操作
for (int i = 0; i < spWord.length; i++) {
if (spWord[i].length() < 4) { // 判断长度是否大于等于4
continue;
} else {
int flag = 1; // 判断字符串的前四位是否是英文字母
char c;
for (int j = 0; j < 4; j++) {
c = spWord[i].charAt(j);
if (!(c >= 'A' && c <= 'Z' || c >= 'a' && c <= 'z')) {
flag = 0;
}
}
if (flag == 1) {
wordCount++;
}
}
}
return wordCount;
}
再次运行效能分析文件,结果如下,可以看出运行时间上已经有了明显的减少。

8.心得体会
这次的实验其实暴露出了我的很多不足的地方,之前的作业我一般都是以代码为核心,个人习惯一拿到题目就马上开始写代码,但这次要求是要按照流程来进行一步步的操作。最开始的对PSP表格的估计就耗费了蛮多时间,因为之前没有过按照规范来做的项目,所以对每一个模块应该用多少时间在观念上还是比较模糊,最后导致实际和预估时间相差还蛮大的。
在整个作业中错误处理和单元测试部分是我觉得最难的部分了,在上面花费的时间也是所有部分中最多的,但是最后的完成的效果还是不太满意,对于异常,我一向是很少会考虑,在写代码的时候大部分也是按照理想的输入状态来,所以在对异常处理的部分还是有很多不足。至于单元测试,可能对于测试样例的设计还是不太熟悉,所以会有冗余现象。
不过这次作业给我的收获还是很大的,学到了比较规范的项目流程,发现了自己很多细节地方的欠缺,还了解到很多新知识。