数据来源:Kaggle
分析目的:对数据进行分析、处理,进而训练、预测。
一、查看数据
import pandas as pd
data_train = pd.read_csv('E:/pythonob/data/Titantic/mytrain.csv') #读取csv数据文件
pd.set_option('expand_frame_repr', False) #显示每一列数据
print(data_train)


可以看到,共有12列数据,分别表示:
- PassengerId => 乘客ID
- Pclass => 乘客等级(1/2/3等舱位)
- Name => 乘客姓名
- Sex => 性别
- Age => 年龄
- SibSp => 堂兄弟/妹个数
- Parch => 父母与小孩个数
- Ticket => 船票信息
- Fare => 票价
- Cabin => 客舱
- Embarked => 登船港口
接下来通过代码查看数据信息:
print(data_train.info())
输出:

从上面可以看出,我们的数据中‘Age’和‘Cabin’两项数据是有缺失的。
下面从另一个角度查看数据信息:
print(data_train.describe())
输出:
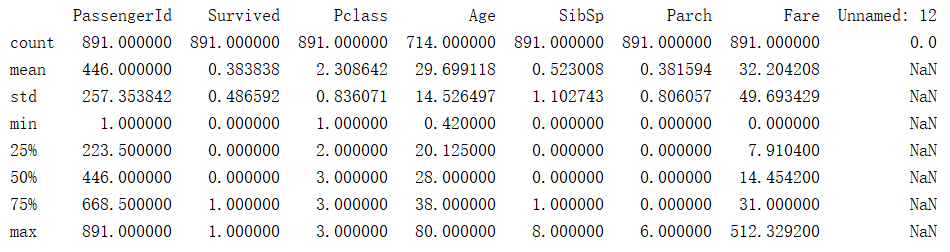
通过describe()我们可以查看各项数据的数量、平均值、标准差、最大最小值等。
二、初步分析
在对数据有了初步的认识之后,就需要了解他们之间的关系了。
通过matplotlib函数来对数据进行可视化处理:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import font_manager
myfont = font_manager.FontProperties(fname='C:/Windows/Fonts/simfang.ttf') #设置图表上的字体(中文显示)
data_train = pd.read_csv('mytrain.csv')
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图,2行3列,当前位置(0,0)
data_train.Survived.value_counts().plot(kind='bar')# 柱状图
plt.title(u"获救情况 (1为获救)",fontproperties=myfont) # 标题
plt.ylabel(u"人数",fontproperties=myfont)
plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数",fontproperties=myfont)
plt.title(u"乘客等级分布",fontproperties=myfont)
plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年龄",fontproperties=myfont) # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title(u"按年龄看获救分布 (1为获救)",fontproperties=myfont)
plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄",fontproperties=myfont)# plots an axis lable
plt.ylabel(u"密度",fontproperties=myfont)
plt.title(u"各等级的乘客年龄分布",fontproperties=myfont)
plt.legend((u'头等舱', u'2等舱',u'3等舱'),prop=myfont,loc='best') # sets our legend for our graph.
plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数",fontproperties=myfont)
plt.ylabel(u"人数",fontproperties=myfont)
plt.show()
结果图:
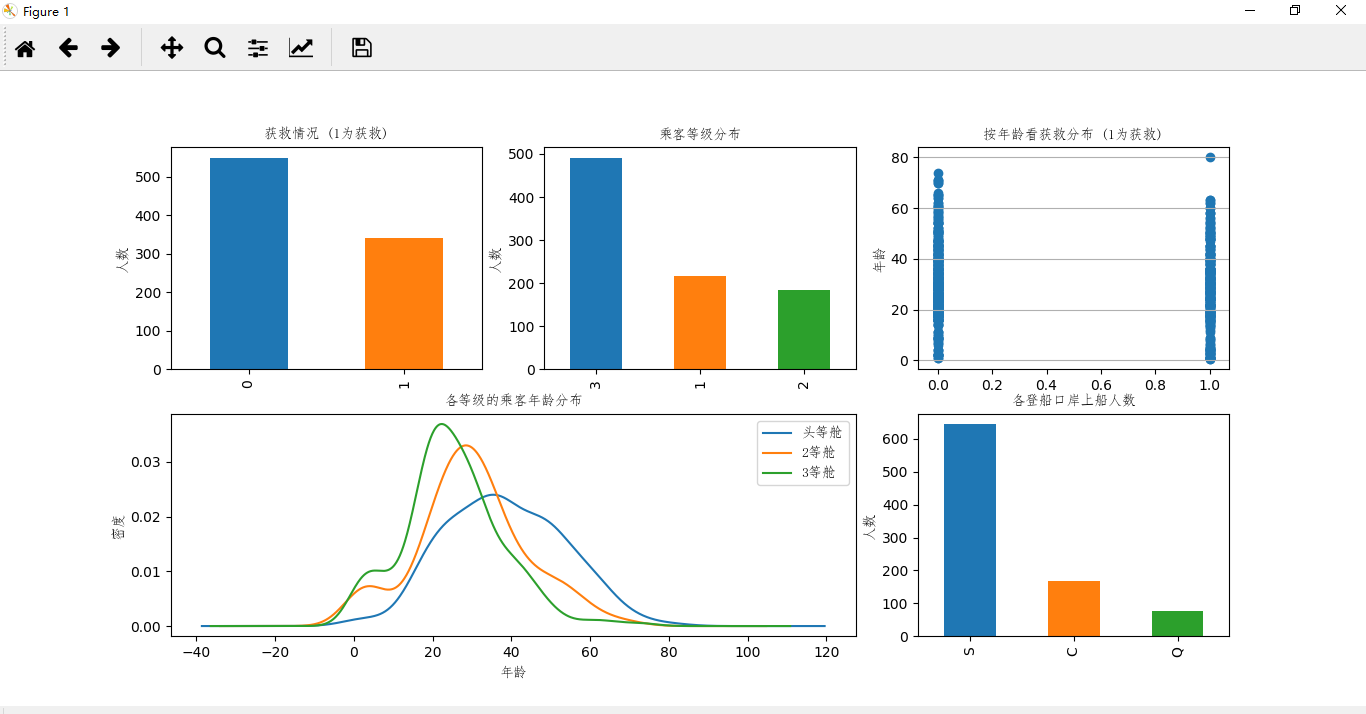
通过数据可视化之后,我们可以明显看出各项数据之间的关系:
获救人数大概是总人数的3/8;
三等舱的人数约为一等舱和二等舱之和;
60岁以上的人获救很少;
头等舱的人年龄整体较高;
S港登船人数最多等等。
通过初步分析之后,我们对数据可以提出一些自己的猜测,如:
头等舱的人生存可能性更大;
年轻人生存几率较高;
男性比女性的生存机会大;
票价高的人生存几率高等等。
然后进一步对数据进行分析,并验证自己的猜测。
首先分析各船舱等级的乘客获救情况
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
#各等级乘客获救情况
myFont = font_manager.FontProperties(fname='C:/Windows/Fonts/simfang.ttf')
data_train = pd.read_csv('E:/pythonob/data/Titantic/mytrain.csv')
#print(data_train.info())
fig=plt.figure()
fig.set(alpha=0.2)
Survived_1 = data_train.Pclass[data_train.Survived==1].value_counts()
Survived_0 = data_train.Pclass[data_train.Survived==0].value_counts()
df = pd.DataFrame({u'Survived':Survived_1,u'dead':Survived_0})
df.plot(kind='bar',stacked=True)
plt.title('不同等级乘客获救情况',fontproperties=myFont)
plt.ylabel('等级',fontproperties=myFont)
plt.xlabel('获救',fontproperties=myFont)
plt.show()
结果图:
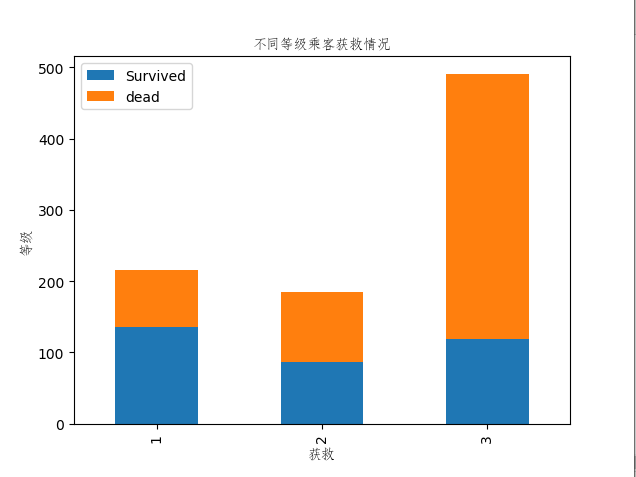
显然,从图中我们可以看出船舱等级越高的乘客获救的比例越高。
接下来看看不同性别的乘客获救比例:
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
myFont = font_manager.FontProperties(fname='C:/Windows/Fonts/simfang.ttf')
data_train = pd.read_csv('E:/pythonob/data/Titantic/mytrain.csv')
#print(data_train.info())
fig=plt.figure()
fig.set(alpha=0.2)
Survived_1 = data_train.Survived[data_train.Sex=='male'].value_counts()
Survived_0 = data_train.Survived[data_train.Sex=='female'].value_counts()
df = pd.DataFrame({u'male':Survived_1,u'female':Survived_0})
df.plot(kind='bar',stacked=True)
plt.title('不同等级乘客获救情况',fontproperties=myFont)
plt.ylabel('人数',fontproperties=myFont)
plt.xlabel('性别',fontproperties=myFont)
plt.xticks([0,1],['死亡','生存'],rotation=0,fontproperties=myFont)
plt.show()
结果图:
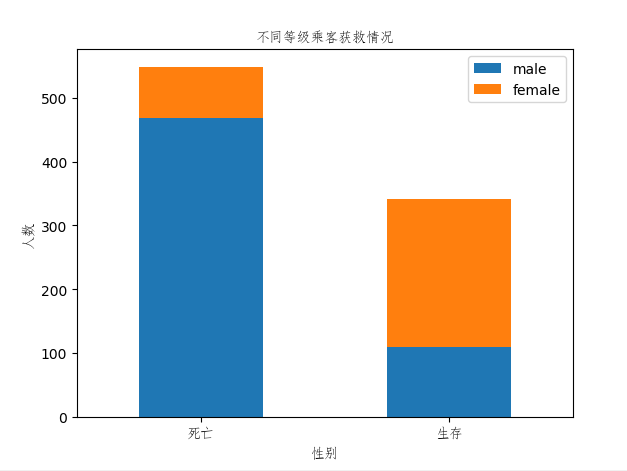
可以看出,女性获救比例远高于男性,与我们猜测的不同。
然后,将不同性别、船舱等级的乘客获救情况放在一起看看:
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
myFont = font_manager.FontProperties(fname='C:/Windows/Fonts/simfang.ttf')
data_train = pd.read_csv('E:/pythonob/data/Titantic/mytrain.csv')
#print(data_train.info())
fig=plt.figure()
fig.set(alpha=0.2)
plt.title(u'根据仓等级和性别的获救情况',fontproperties=myFont)
ax1=fig.add_subplot(141)
maleSurivedC12 = data_train.Survived[data_train.Pclass!=3][data_train.Sex=='male'].value_counts()
maleSurivedC12.plot(kind='bar')
plt.legend(['男性/高级仓'],loc='best',prop=myFont)
plt.xlabel('生死',fontproperties=myFont)
plt.ylabel('数量',fontproperties=myFont)
#plt.ylim(0,300) # 设置y轴参数
plt.xticks([1,0],['生','死'],fontproperties=myFont)
ax2=fig.add_subplot(142, sharey=ax1)
femaleSurivedC12 = data_train.Survived[data_train.Pclass!=3][data_train.Sex=='female'].value_counts()
femaleSurivedC12.plot(kind='bar')
#plt.ylim(0,300)
plt.legend(['女性/高级仓'],loc='best',prop=myFont)
plt.xticks([0,1],['生','死'],fontproperties=myFont)
ax3=fig.add_subplot(143, sharey=ax1)
maleSurivedC3 = data_train.Survived[data_train.Pclass==3][data_train.Sex=='male'].value_counts()
maleSurivedC3.plot(kind='bar')
#plt.ylim(0,300)
plt.legend(['男性/低级仓'],loc='best',prop=myFont)
plt.xticks([1,0],['生','死'],fontproperties=myFont)
ax4=fig.add_subplot(144, sharey=ax1)
#plt.ylim(0,300)
femaleSurivedC3 = data_train.Survived[data_train.Pclass==3][data_train.Sex=='female'].value_counts()
femaleSurivedC3.plot(kind='bar')
print(femaleSurivedC3)
plt.legend(['女性/低级仓'],loc='best',prop=myFont)
plt.xticks([0,1],['生','死'],fontproperties=myFont)
plt.show()
这里我们将一等舱、二等舱划分为高级舱、三等舱为低级舱。
结果图:
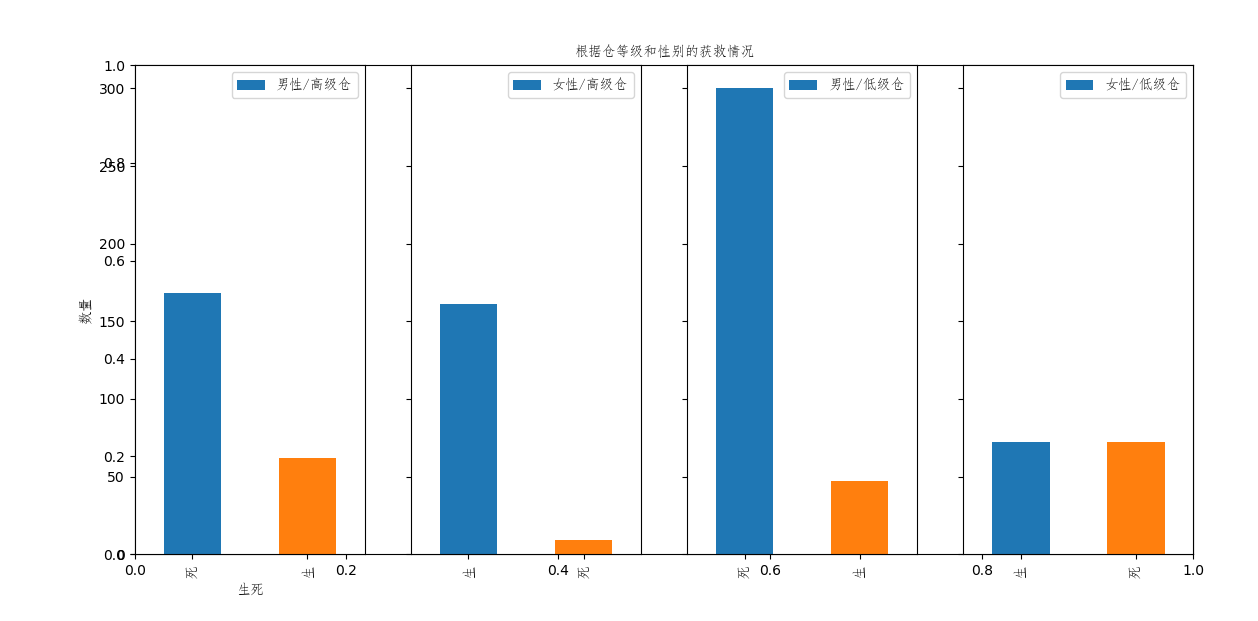
从图中可以看出高级仓、女性存活比例最高,低级舱、男性存活比例最低。进一步验证了上面的分析。
下面根据登船港口分析获救情况:
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
myFont = font_manager.FontProperties(fname='C:/Windows/Fonts/simfang.ttf')
data_train = pd.read_csv('E:/pythonob/data/Titantic/mytrain.csv')
#print(data_train.info())
plt.figure()
embarkSurvived1 = data_train.Embarked[data_train.Survived==1].value_counts()
embarkSurvived0 = data_train.Embarked[data_train.Survived==0].value_counts()
df = pd.DataFrame({'Survived':embarkSurvived1,'Dead':embarkSurvived0})
df.plot(kind='bar')
plt.title(u'根据登船港口的获救情况',fontproperties=myFont)
plt.xlabel('港口',fontproperties=myFont)
plt.ylabel('人数',fontproperties=myFont)
plt.show()
结果图:
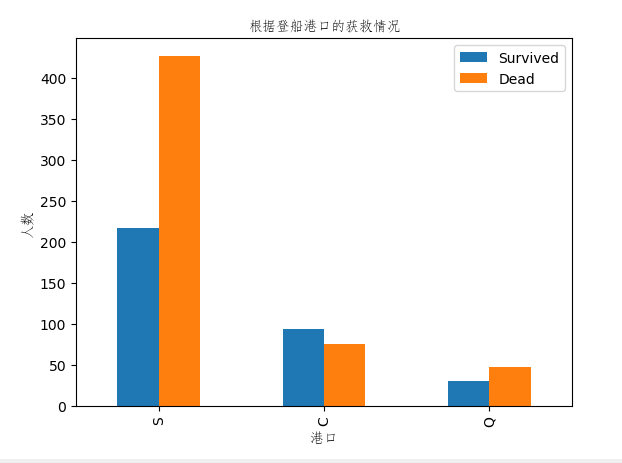
从图中可以看出只有港口C的获救比例是正的,没有规律,参考意义不大。
下面看看堂兄妹/父母孩子(SibSp/Parch)的个数对与获救情况有没有关系:
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
myFont = font_manager.FontProperties(fname='C:/Windows/Fonts/simfang.ttf')
data_train = pd.read_csv('E:/pythonob/data/Titantic/mytrain.csv')
#print(data_train.info())
g = data_train.groupby(['SibSp','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
print(df)结果图:

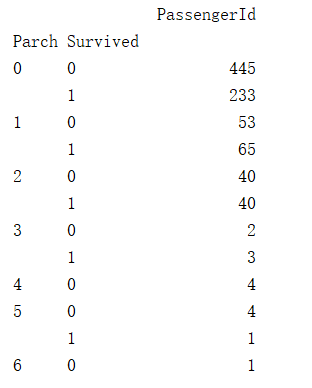
没有特定规律,不具有参考意义。
三、数据预处理
对于有数据缺失的列我们一般采用以下几种方式:
- 如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
- 如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
- 如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
- 有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
这里首先是对Cabin的处理,由于Cabin这一列的缺失值太多,而且具体值的意思不明了,于是将其分为有数据和没数据两种。
试着分析Cabin数据有无与乘客生存情况的关系:
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
myFont = font_manager.FontProperties(fname='C:/Windows/Fonts/simfang.ttf')
data_train = pd.read_csv('E:/pythonob/data/Titantic/mytrain.csv')
#print(data_train.info())
plt.figure()
Survived_Cabin = data_train.Survived[pd.notnull(data_train.Cabin)].value_counts()
Survived_noCabin = data_train.Survived[pd.isnull(data_train.Cabin)].value_counts()
df = pd.DataFrame({'yes':Survived_Cabin,'no':Survived_noCabin}).transpose()
df.plot(kind='bar',stacked=True)
plt.xlabel('Cabin有无',fontproperties=myFont)
plt.ylabel('人数',fontproperties=myFont)
plt.title('根据Cabin有无查看获救情况',fontproperties=myFont)
plt.show()
结果图:
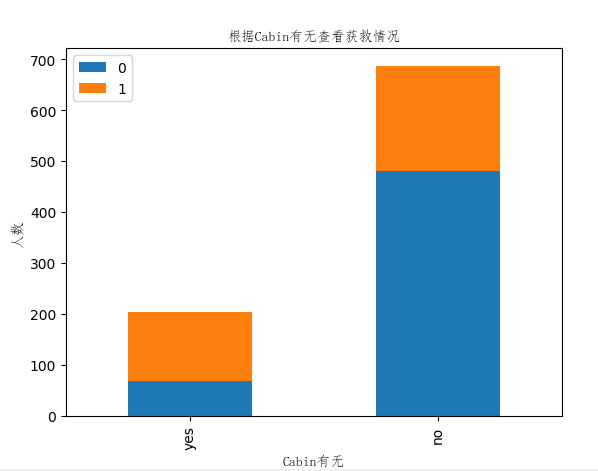
从图中可以看出有数据的人获救比例较高,虽然有结果,但实际对乘客是否获救可能没有影响,先不作特征考虑。(这里主要考虑到有数据的人身份地位较高,可能是在出事故的时候优先救援)
对于年龄,我们这里用scikit-learn中的RandomForest来拟合一下缺失的年龄数据
年龄数据拟合函数:
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补原缺失数据
df.loc[(df.Age.isnull()), 'Age'] = predictedAges
return df, rfr
结果图:

可以看出,年龄数据已经完成拟合并写入。
对于Cabin这一项,我们将有数据的值改为‘Yes’,没有数据的值改为‘No’
def set_Cabin_type(df):
df.loc[(df.Cabin.notnull()), 'Cabin'] = "Yes"
df.loc[(df.Cabin.isnull()), 'Cabin'] = "No"
return df
结果图:
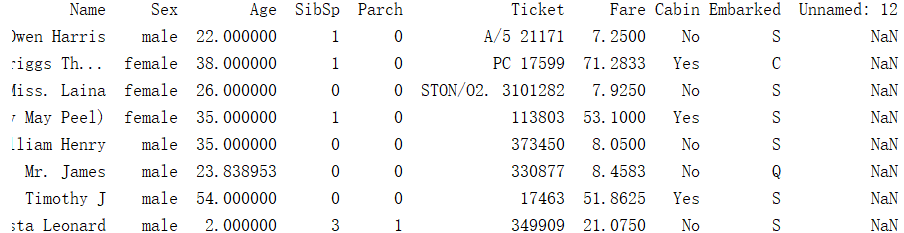
Cabin这一项数据也已经处理完毕。以上函数通过下面代码调用处理:
pd.set_option('display.max_rows',50)
pd.set_option('display.max_columns',500) #设置最大显示列数
pd.set_option('expand_frame_repr', False)
data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
四、建模
逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化。
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1) #将上面归一化后的数据接到原数据后面。
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True) # 删除指定行列,axis默认为0表示删除行,1表示删除列,inplace=True表示改变原数据,False相反
scaler = preprocessing.StandardScaler()#均值方差归一化函数
age_scale_param = scaler.fit(df['Age'].values.reshape(-1,1)) # reshape(-1,1)转换成1列:-1表示行自动计算,1表示1列
df['Age_scaled'] = scaler.fit_transform(df['Age'].values.reshape(-1,1), age_scale_param)
fare_scale_param = scaler.fit(df['Fare'].values.reshape(-1,1))
df['Fare_scaled'] = scaler.fit_transform(df['Fare'].values.reshape(-1,1), fare_scale_param)
结果图:

可以看到,复杂的数据变得简单了,也符合了逻辑回归的要求。
接下来取出我们需要的特征并建模:
# 用正则取出我们要的属性值
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.as_matrix()
# y即Survival结果
y = train_np[:, 0]
# X即特征属性值
X = train_np[:, 1:]
# fit到RandomForestRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)
print(clf)
输出:

最后对测试数据进行同样的处理,并通过模型预测结果:
#测试数据预处理
data_test = pd.read_csv('E:/pythonob/data/Titantic/mytest.csv')
data_test.loc[(data_test.Fare.isnull()), 'Fare' ] = 0
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
# 根据特征属性X预测年龄并补上
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAges
data_test = set_Cabin_type(data_test)
dummies_Cabin_t = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
dummies_Embarked_t = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex_t = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass_t = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([data_test, dummies_Cabin_t, dummies_Embarked_t, dummies_Sex_t, dummies_Pclass_t], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df_test['Age_scaled'] = scaler.fit_transform(df_test['Age'].values.reshape(-1,1), age_scale_param)
df_test['Fare_scaled'] = scaler.fit_transform(df_test['Fare'].values.reshape(-1,1), fare_scale_param)
print(df_test)
test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("E:/pythonob/data/Titantic/logistic_regression_predictions.csv", index=False)
结果:


将得到的结果上传到kaggle:
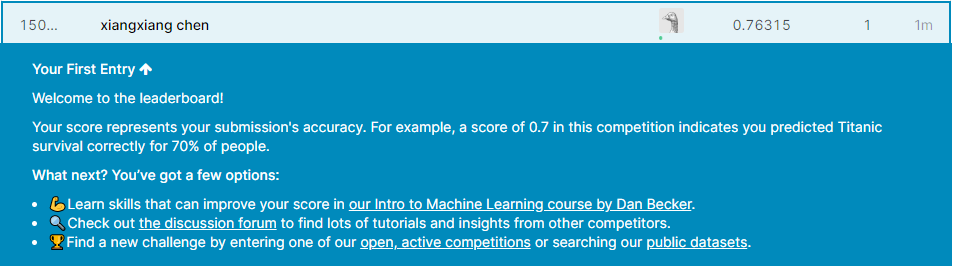
初次学习,效果不是很好。
下面是对数据进行处理、建模、预测的完整代码:
# coding = utf-8
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
import numpy as np
import sklearn.preprocessing as preprocessing
from sklearn import linear_model
data_train = pd.read_csv('E:/pythonob/data/Titantic/mytrain.csv')
### 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补原缺失数据
df.loc[(df.Age.isnull()), 'Age'] = predictedAges
return df, rfr
def set_Cabin_type(df):
df.loc[(df.Cabin.notnull()), 'Cabin'] = "Yes"
df.loc[(df.Cabin.isnull()), 'Cabin'] = "No"
return df
pd.set_option('display.max_rows',50)
pd.set_option('display.max_columns',500)
pd.set_option('expand_frame_repr', False)
data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True) # 删除指定行列,axis默认为0表示删除行,1表示删除列,inplace=True表示改变原数据,False相反
scaler = preprocessing.StandardScaler()#均值方差归一化函数
age_scale_param = scaler.fit(df['Age'].values.reshape(-1,1)) # reshape(-1,1)转换成1列:-1表示行自动计算,1表示1列
df['Age_scaled'] = scaler.fit_transform(df['Age'].values.reshape(-1,1), age_scale_param)
fare_scale_param = scaler.fit(df['Fare'].values.reshape(-1,1))
df['Fare_scaled'] = scaler.fit_transform(df['Fare'].values.reshape(-1,1), fare_scale_param)
# 用正则取出我们要的属性值
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.as_matrix()
# y即Survival结果
y = train_np[:, 0]
# X即特征属性值
X = train_np[:, 1:]
# fit到RandomForestRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)
print(clf)
#测试数据预处理
data_test = pd.read_csv('E:/pythonob/data/Titantic/mytest.csv')
data_test.loc[(data_test.Fare.isnull()), 'Fare' ] = 0
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
# 根据特征属性X预测年龄并补上
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAges
data_test = set_Cabin_type(data_test)
dummies_Cabin_t = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
dummies_Embarked_t = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex_t = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass_t = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([data_test, dummies_Cabin_t, dummies_Embarked_t, dummies_Sex_t, dummies_Pclass_t], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df_test['Age_scaled'] = scaler.fit_transform(df_test['Age'].values.reshape(-1,1), age_scale_param)
df_test['Fare_scaled'] = scaler.fit_transform(df_test['Fare'].values.reshape(-1,1), fare_scale_param)
print(df_test)
test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("E:/pythonob/data/Titantic/logistic_regression_predictions.csv", index=False)