HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是不能保证该顺序恒久不变。
HashMap的数据结构:
在java中,最基本的结构有两种:一是数组,而是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
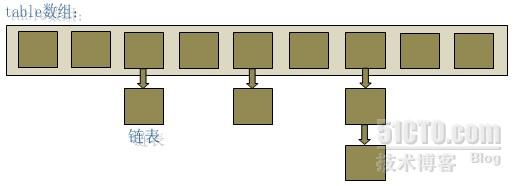
HashMap底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap时,就会初始化一个数组。
1 transient Entry[] table; 2 static class Entry<k,V> implements Map.Entry<K,V>{ 3 final K key; 4 V value; 5 Entry<K,V> next; 6 final int hash; 7 ...... 8 }
可以看出,Entry就是数组中的元素,每个Map.Entry其实就是一个key-value对,它持有一个指向下一个元素的引用,这就构成了链表。
HashMap的存取实现:
1)存储:
1 public V put(K key,V value){ 2 //HashMap允许存放null值和null键 3 //当key为null时,调用putForNullKey方法,将value放置在数组的一个位置。 4 if(key==null) 5 return putForNullKey(value); 6 //根据key的hashCode重新计算hash值 7 int hash=hash(key.hashCode()); 8 //搜索指定hash值在对应table中的索引 9 int i=indexFor(hash,table.length); 10 //如果i索引处的Entry不为null,通过循环不断遍历e元素的下一个元素。 11 for(Entry<K,V> e=table[i];e!=null;e=e.next){ 12 Object k; 13 if(e.hash==hash&&((k=e.key)==key||key.equals(k))){ 14 V oldValue = e.value; 15 e.value = value; 16 e.recordAccess(this); 17 return oldValue; 18 } 19 } 20 // 如果i索引处的Entry为null,表明此处还没有Entry。 21 modCount++; 22 // 将key、value添加到i索引处。 23 addEntry(hash, key, value, i); 24 return null; 25 }
从上面的源码中可以看出:当我们往HashMap中put元素的时候,先根据key的hashCode重新计算hash值,根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放了其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
2)读取:
public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; }
有了上面存储时的hash算法作为基础,理解起来这段代码就很容易了。从上面的源代码中可以看出:从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
以上内容摘抄自http://beyond99.blog.51cto.com/1469451/429789
HashMap使用了特殊的值,称作散列码,来取代对键的缓慢搜索。散列码是“相对唯一”的、用以代表对象的int值,它是通过将该对象的某些信息进行转换而生成的。hashCode()是根类Object中的方法,因此所有的Java对象都能产生散列码。HashMap就是使用对象的hashCode()进行快速查询的,此方法能显著提高性能。