导读目录
第一节:sparksql
1:简介
2:核心
3:与hive整合
4:dataFrame
5:函数
第二节:spark Streaming
1:对比strom
2:DStream的算子
3:代码
4:driver HA
5:读取数据
第三节:spark调优
第一节:sparksql
(1)简介:
Shark:shark是sparksql的前身,hive是shark的前身
快的原因:不仅是内存,还有谓词下移(减少一定量的数据IO)
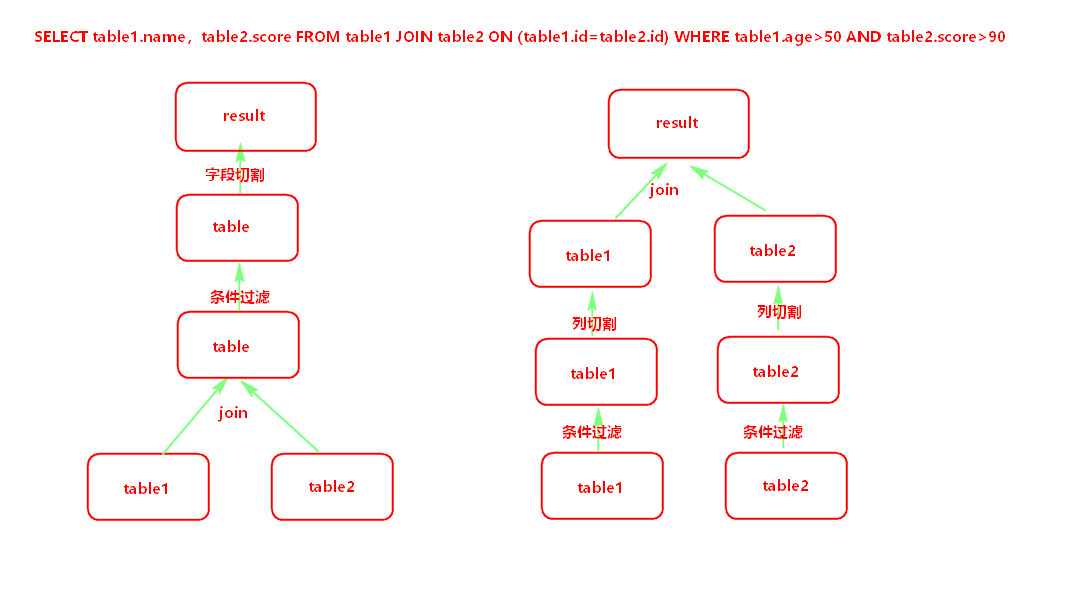
正常 谓词下移
(先关联表在切割) (先将表中的字段过滤,再join)
(2)核心:
sql的解析优化,执行引擎全是spark;
兼容hive的所有sql;
可以直接访问RDD,spark的核心就是RDD;
Dataframe:对RDD进行包装,自己的存储数据集合;
(3)与hive整合:
3.1 整合的方式
第一种:hive on spark(实际就是shark):
存储,sql解析优化hive实现
执行引擎是spark
第二种:spark on hive:
存储是hive
sql解析优化,执行引擎都是spark
应用:
1、安装配置
拷贝hive-site.xml文件到conf目录,
只保留thrift://node3:9083
在启动application的时候能看到连接9083端口的信息
创建HiveContext对象
2、执行引擎
数据存储在hive中
解析优化执行全部是spark来执行
3.2 代码(从hive中读数据,往hive中写数据)
SparkConf conf = new SparkConf(); conf.setAppName("hive"); JavaSparkContext sc = new JavaSparkContext(conf);
//HiveContext是SQLContext的子类。 HiveContext hiveContext = new HiveContext(sc); hiveContext.sql("USE spark"); hiveContext.sql("DROP TABLE IF EXISTS student_infos"); //在hive中创建student_infos表 hiveContext.sql("CREATE TABLE IF NOT EXISTS student_infos (name STRING,age INT) row format delimited fields terminated by ' ' "); hiveContext.sql("load data local inpath '/root/test/student_infos' into table student_infos"); hiveContext.sql("DROP TABLE IF EXISTS student_scores"); hiveContext.sql("CREATE TABLE IF NOT EXISTS student_scores (name STRING, score INT) row format delimited fields terminated by ' '"); hiveContext.sql("LOAD DATA LOCAL INPATH '/root/test/student_scores' INTO TABLE student_scores");
/** * 查询表生成DataFrame */ DataFrame goodStudentsDF = hiveContext.sql("SELECT si.name, si.age, ss.score FROM student_infos si JOIN student_scores ss ON si.name=ss.name WHERE ss.score>=80"); hiveContext.sql("DROP TABLE IF EXISTS good_student_infos"); goodStudentsDF.registerTempTable("goodstudent"); DataFrame result = hiveContext.sql("select * from goodstudent"); result.show(); /** * 将结果保存到hive表 good_student_infos */ goodStudentsDF.write().mode(SaveMode.Overwrite).saveAsTable("good_student_infos"); Row[] goodStudentRows = hiveContext.table("good_student_infos").collect(); for(Row goodStudentRow : goodStudentRows) { System.out.println(goodStudentRow); } sc.stop();
3.3 提交到集群的指令
./spark-submit
--master spark://node1:7077,node2:7077
--executor-cores 1
--executor-memory 2G
--total-executor-cores 1
--class com.bjsxt.sparksql.dataframe.CreateDFFromHive
/root/test/HiveTest.jar
(4)dataFrame:
4.1、拥有独立的api,所以还是代码形式的,所以不是很好用,还是以sql形式的好
df.show()只能显示20行,可以添加参数
dataframe可以转换成RDD
.javaRDD
.rdd
//以上生成的是list形式,可以通过以下获取具体列
.get(0)
.getAs(“name”)
直接执行sql
df.registerTempTable(“表名”) //将dataframe数据注册成临时表,列名时按照ascii码排列的
SqlContext.sql(“查询上面表名中的数据即可”)
4.2、创建dataframe方式
(1)读取json格式的数据
sqlContext.read().format("json").load(path)
sqlContext.read().json(path)
注意点:
1、json数据不能嵌套
(2)读取json格式的RDD
sqlContext.read().json(rdd)
(3)通过反射的方式创建Dataframe,将rdd封装到对象中
1.定义具体的对象类
2.map算子进行源文件切割,包装成对象(这个对象必须序列化)
rdd.map() //将rdd切割之后对应的封装到对象中
3.映射创建
sqlContext.creatDataframe(rdd, Persion.class)
(4)通过struct方式创建Dataframe
1.在切割源文件的时候,使用rowFactory.create()
rdd.map()的返回值是rowFactory.create(),得到Row类型的RDD
2.规定structType,使用DataTypes来创建
List<StructField> asList =Arrays.asList(
DataTypes.createStructField("id", DataTypes.StringType, true),
DataTypes.createStructField("name", DataTypes.StringType, true),
DataTypes.createStructField("age", DataTypes.IntegerType, true)
);
StructType schema = DataTypes.createStructType(asList);
DataFrame df = sqlContext.createDataFrame(rowRDD, schema);
(5)读取parquet文件(是一个列式存储)创建Dataframe
sqlContext.read().format("parquet").load(path)
sqlContext.read().parquet(path);
(6)读取mysql数据创建Dataframe
连接mysql的时候使用jdbc的方式
设置参数(driver,url,user,password,Dbtable)
1.sqlContext.read().options(map).format("jdbc").load()
例子:
Map<String, String> options = new HashMap<String,String>(); options.put("url", "jdbc:mysql://192.168.179.4:3306/spark"); options.put("driver", "com.mysql.jdbc.Driver"); options.put("user", "root"); options.put("password", "123456"); options.put("dbtable", "person"); DataFrame person = sqlContext.read().format("jdbc").options(options).load();
2.sqlContext.read().format("jdbc").load()
例子:
DataFrameReader reader = sqlContext.read().format("jdbc");
reader.option("url", "jdbc:mysql://192.168.179.4:3306/spark");
reader.option("driver", "com.mysql.jdbc.Driver");
reader.option("user", "root");
reader.option("password", "123456");
reader.option("dbtable", "score");
DataFrame score = reader.load();
4.3、本地执行hive
1、拷贝当前配置文件到src目录:hive-site.xml,core-site.xml,hdfs-site.xml
2、添加jar,以data开头的三个jar文件
3、window环境必须是以root用户名命名的
4、执行的时候内存有可能不够,添加VM参数配置:
-server -Xms512M -Xmx1024M -XX:PermSize=256M -XX:MaxNewSize=512M -XX:MaxPermSize=512M
4.4、写数据
(1)写入数据源
parquet
df.write().mode(SaveMode).format("parquet").save(“路径”)
例子:
df.write().mode(SaveMode.Overwrite).format("parquet").save("./sparksql/parquet");
df.write().mode(SaveMode.Overwrite).parquet("./sparksql/parquet");
hive
df.write().mode(SaveMode).saveAsTable()
mysql
df.write().mode(SaveMode).format("JDBC").save()
(2)写数据操作
df.write().mode(SaveMode).save()
SaveMode
append:追加
overwrite:覆盖
ignore:如果存在就忽略
ErrorIfExists:存在即报错
(5)函数
5.1 udf
sqlContext.udf().register(方法名称,new UDF1..22,返回值类型),即最多22个参数
例子:
val conf = new SparkConf() conf.setMaster("local").setAppName("udf") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc); val rdd = sc.makeRDD(Array("zhansan","lisi","wangwu")) val rowRDD = rdd.map { x => { RowFactory.create(x) } } val schema = DataTypes.createStructType(Array(StructField("name",StringType,true))) val df = sqlContext.createDataFrame(rowRDD, schema) df.registerTempTable("user") //sqlContext.udf.register("StrLen",(s : String)=>{s.length()}) //sqlContext.sql("select name ,StrLen(name) as length from user").show sqlContext.udf.register("StrLen",(s : String,i:Int)=>{s.length()+i}) //定义的函数 sqlContext.sql("select name ,StrLen(name,10) as length from user").show //引用 sc.stop()
5.2 Udaf(聚合):实现UDAF函数如果要自定义类要继承UserDefinedAggregateFunction类
sqlContext.udf().register(函数名称,new UserDefinedAggratedFunction())
例子:
class MyUDAF extends UserDefinedAggregateFunction { // 定义缓存区参数的类型 def bufferSchema: StructType = { DataTypes.createStructType(Array(DataTypes.createStructField("aaa", IntegerType, true))) } // 最终函数返回值的类型 def dataType: DataType = { DataTypes.IntegerType } def deterministic: Boolean = { true } // 最后返回一个最终的聚合值,要和dataType的类型一一对应 def evaluate(buffer: Row): Any = { buffer.getAs[Int](0) } // 为每个分组的数据执行初始化值,重点 def initialize(buffer: MutableAggregationBuffer): Unit = { buffer(0) = 0 } //输入数据的类型 def inputSchema: StructType = { DataTypes.createStructType(Array(DataTypes.createStructField("input", StringType, true))) } // 最后merger的时候,在各个节点上的聚合值,要进行merge,也就是合并,重点(合并所有节点) def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = { buffer1(0) = buffer1.getAs[Int](0)+buffer2.getAs[Int](0) } // 每个组,有新的值进来的时候,进行分组对应的聚合值的计算,重点(每个组上的相同key的做操作) def update(buffer: MutableAggregationBuffer, input: Row): Unit = { buffer(0) = buffer.getAs[Int](0)+1 } } object UDAF { def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setMaster("local").setAppName("udaf") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) val rdd = sc.makeRDD(Array("zhangsan","lisi","wangwu","zhangsan","lisi")) val rowRDD = rdd.map { x => {RowFactory.create(x)} } val schema = DataTypes.createStructType(Array(DataTypes.createStructField("name", StringType, true))) val df = sqlContext.createDataFrame(rowRDD, schema) df.show() df.registerTempTable("user") /** * 注册一个udaf函数 */ sqlContext.udf.register("StringCount", new MyUDAF()) sqlContext.sql("select name ,StringCount(name) from user group by name").show() sc.stop() }}
5.3 开窗函数: over(专门解决某些特定场景的问题)
例子:分组取topn
用到的开窗函数:row_number():其中的一个开窗函数,还有很多其他的开窗函数
用法:row_number() over(partition by xxx order by xxx desc as rank)
代码:
SparkConf conf = new SparkConf(); conf.setAppName("windowfun"); JavaSparkContext sc = new JavaSparkContext(conf); HiveContext hiveContext = new HiveContext(sc); hiveContext.sql("use spark"); hiveContext.sql("drop table if exists sales"); hiveContext.sql("create table if not exists sales (riqi string,leibie string,jine Int) row format delimited fields terminated by ' '"); hiveContext.sql("load data local inpath '/root/test/sales' into table sales"); /** * 开窗函数格式: * 【 rou_number() over (partitin by XXX order by XXX) 】 */ DataFrame result = hiveContext.sql("select riqi,leibie,jine from (select riqi,leibie,jine," + "row_number() over (partition by leibie order by jine desc) rank from sales) t where t.rank<=3"); result.show(); sc.stop();
第二节:spark Streaming
1、对比strom

不建议使用动态资源,因为你释放资源之后,如果再用的话被占用,那么就影响了流式的速度。
2、DStream的算子
(1)Transformation算子
1、updateStateByKey:只要启动之后就开始统计所有key的状态。
需要开启checkpoint:
sparkContext.setCheckpoint(“定义存状态的路径”) 或者StreamingContext.checkpoint(“定义存状态的路径”)
这个状态在内存是存在的,那么多久的时间写入磁盘呢?
如果batchInterval设置的时间小于10秒,那么10秒写入磁盘一份。如果batchInterval设置的时间大于10秒,那么就会 batchInterval时间间隔写入磁盘一份
举例:new StreamingContext(conf, Durations.seconds(5)) //每5秒钟记录一次
上面是记录的所有的记录,那么如何记录一段时间内的记录,用窗口函数:
2、窗口函数举例:reduceByKeyAndWindow(一个function,Durations.seconds(15),Durations.seconds(5))
//每隔5秒(滑动间隔)记录前15秒(窗口长度)的状态
//未优化的普通机制不需要设置checkpoint
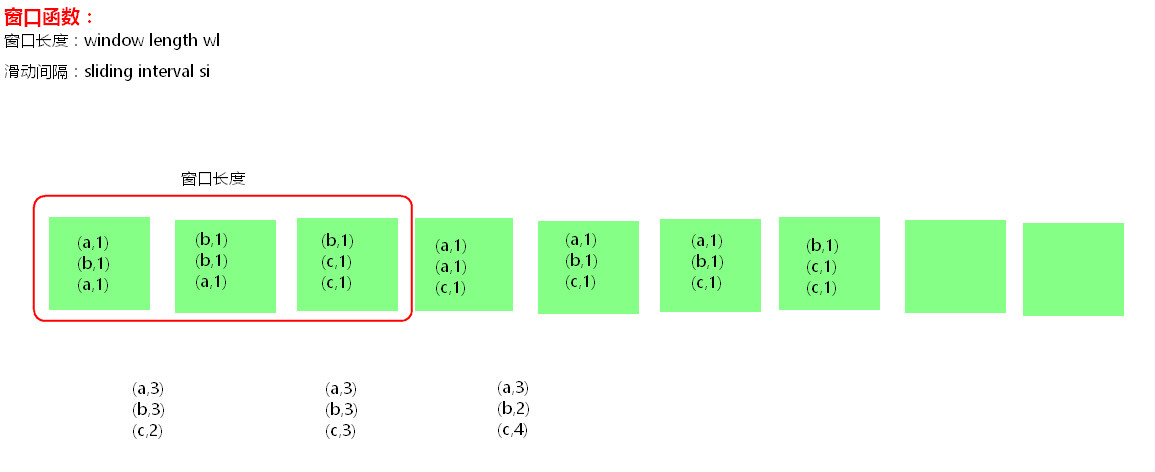
按照这个图上的分析:
我们设置的是每隔5秒计算一次,那么一个绿框就是5秒的数据
优化的机制:(假如每隔1秒计算过去一年的,那么可能会产生任务堆积)
我们可以在计算的逻辑上,用当前的加上新的状态,减去不要的状态,这个时候需要设置checkpoint
.windows(Durations.seconds(15),Durations.seconds(5)) //自己定义窗口函数
3、transform:
是在driver端执行的,可以动态广播变量。
可以对Dstream中的RDD做RDD与RDD之间的任意操作,不需要action算子触发。
(2)outPutOperator算子
foreachRDD:
这个是streaming的outPutOperator算子,所以执行就触发。(所以可以动态的发布广播变量)
如果在这里面用了Transformation算子,那么不用action算子触发的话,这个里面的Transformation算子不会执行。
3、代码
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("WordCountOnline"); /** * 在创建streaminContext的时候 设置batchInterval */ JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5)); JavaReceiverInputDStream<String> lines = jsc.socketTextStream("node5", 9999); JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L;
@Override public Iterable<String> call(String s) { return Arrays.asList(s.split(" ")); } }); JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String s) { return new Tuple2<String, Integer>(s, 1); } }); JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(Integer i1, Integer i2) { return i1 + i2; } });
//outputoperator类的算子 counts.print(); jsc.start(); //等待spark程序被终止 jsc.awaitTermination();
jsc.stop(false);
4、driver HA
(1) 提交任务层面,在提交任务的时候加上选项 --supervise,当Driver挂掉的时候会自动重启Driver
(2) 代码层面,使用JavaStreamingContext.getOrCreate(checkpoint路径,JavaStreamingContextFactory)
Driver中元数据包括:
- 创建应用程序的配置信息。
- DStream的操作逻辑。
- job中没有完成的批次数据,也就是job的执行进度。
5、读取数据
(1) 监控文件的数据
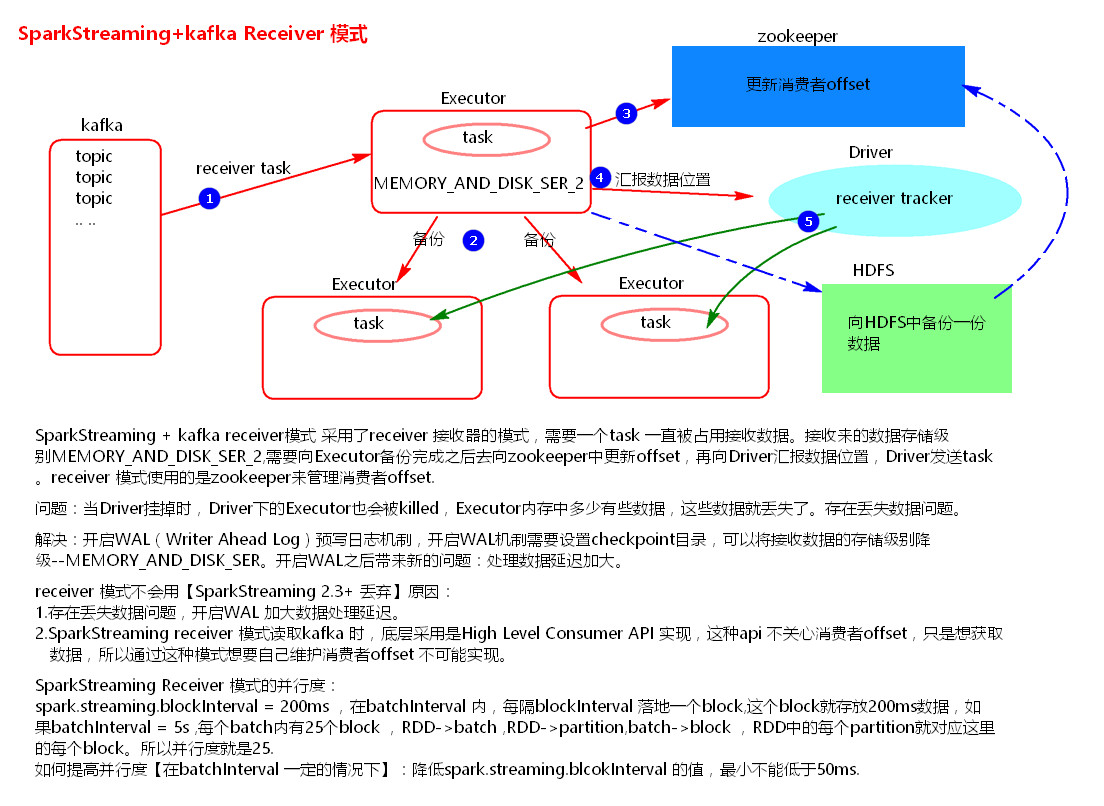
(2) Kafka(几乎都是结合kafka使用)
整合1:receiver模式,已被淘汰
整合2:direct模式
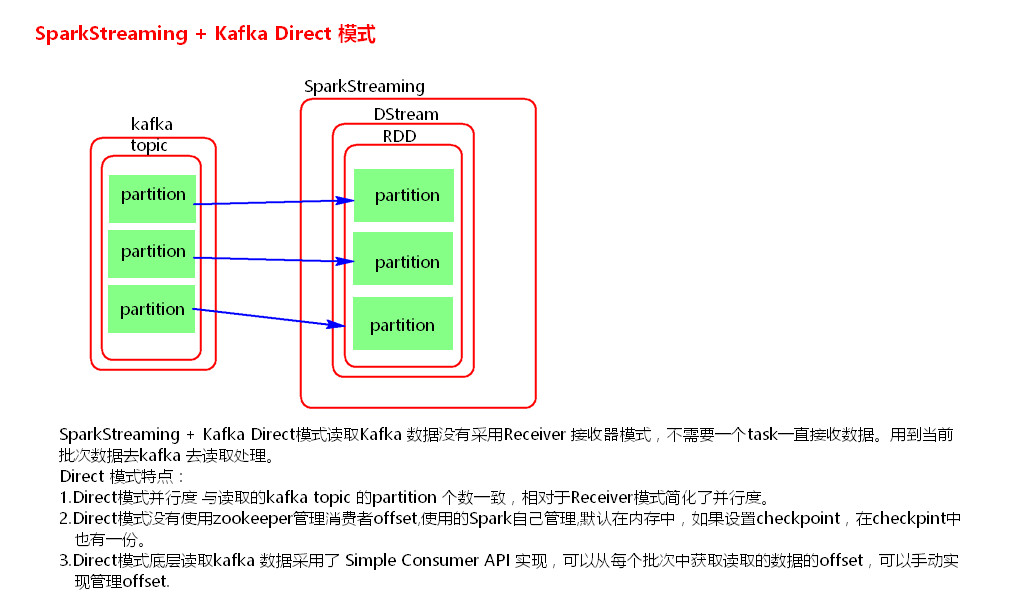
(3) sparkStreaming+kafka版本变化:
Direct模式,1.6用的是simple API,2.0用的是new API,所以代码有变化。
可以用kafka管理offset,但是是异步提交方式。
第三节:spark 调优
1、资源调优
集群:
SPARK_WORKER_MEMORY
SPARK_WORKER_CORES
提交任务:
./spark-submit......
--driver-cores
--driver-memory
--executor-cores
--excutor-memory
--totail-executor-cores
最好在提交任务时指定
2、并行度调优
即提升partition个数
生成RDD或者一些算子指定partition个数。
Reparation/coalesce
Spark.default.parallelism
Spark.sql.shuffle.partitions
自定义分区器
3、代码调优
(1)不要频繁创建RDD,复用同一个RDD
(2)对RDD的持久化
(3)尽量避免使用shuffle类算子
(4)尽量使用高性能的算子
使用reduceByKey替代groupByKey
使用mapPartition替代map
使用foreachPartition替代foreach
filter后使用coalesce减少分区数
使用使用repartitionAndSortWithinPartitions替代repartition与sort类操作
使用repartition和coalesce算子操作分区。
(5)使用map-side预聚合的shuffle操作
即尽量使用有combiner的shuffle类算子。
combiner概念:
在map端,每一个map task计算完毕后进行的局部聚合。
combiner好处:
1) 降低shuffle write写磁盘的数据量。
2) 降低shuffle read拉取数据量的大小。
3) 降低reduce端聚合的次数。
有combiner的shuffle类算子:
1) reduceByKey:这个算子在map端是有combiner的,在一些场景中可以使用reduceByKey代替groupByKey。
2) aggregateByKey
3) combineByKey
(6) 使用广播变量
4、数据本地化调优
级别:
1) PROCESS_LOCAL
2) NODE_LOCAL
3) NO_PREF
4) RACK_LOCAL
5) ANY