0、写在前面的话
图片批量下载,要求下载时集成为一个压缩包进行下载。从昨天下午折腾到现在,踩坑踩得莫名其妙,还是来唠唠,给自己留个印象的同时,也希望给需要用到这个方法的人带来一些帮助。
1、先叨叨IO
叨叨IO是因为网络传输无非也就是流的传递,所以下载文件到本地的话实际上也是IO的东西,这个和读取本地文件然后写入到本地另一个文件的操作是基本一样的。
我在自己IO基础的博客中(《[03] 节点流和处理流》)其实也有提到示例,拿复写文件来说,大概是如下过程:
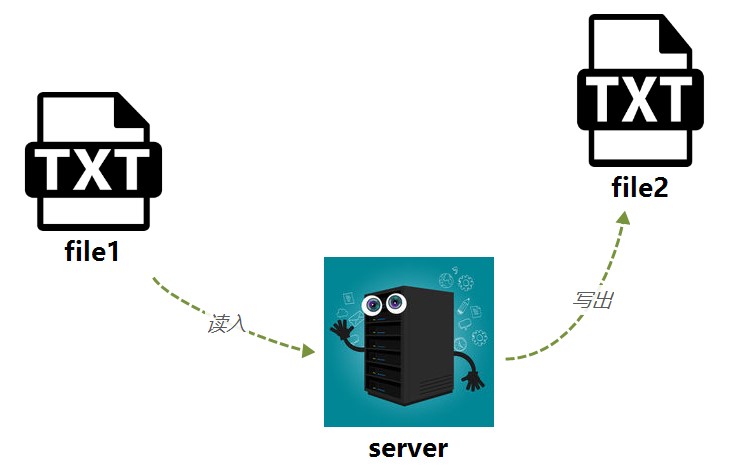
对于读取文件(不仅仅是文本)到服务器内存,常见的是通过InputStream读取File,所以你可能也经常看到如下类似的代码:
outputStream = new FileOutputStream(file);
byte[] temp = new byte[1024];
int size = -1;
while ((size = inputStream.read(temp)) != -1) { // 每次读取1KB,直至读完
outputStream.write(temp, 0, size);
}1
outputStream = new FileOutputStream(file); 2
byte[] temp = new byte[1024];3
int size = -1;4
while ((size = inputStream.read(temp)) != -1) { // 每次读取1KB,直至读完5
outputStream.write(temp, 0, size);6
}我这里想说的是,不论何种形式,只需要知道的是,在写出之前,要获取将写出的数据,这个数据常常是作为byte[ ]类型的。
同时,因为是写出到本地文件,所以这里图示中的OutputStream无非应该是使用FileOutputStream罢了。那么以此来类比网络传输下载的话,OutputStream显然就替换成响应HttpServletResponse中的OutputStream就可以了。本质都是输出流,不同的类型决定你输出的方式等。
2、再叨叨ajax
当你把文件数据的二进制放到了响应的流中,也确实在响应中返回了,可是浏览器就是不争气,不给面子,不启动下载。这个时候,你要看看,你发送请求的方式,是否采取了ajax请求。如下图采用ajax请求资源,确实收到了流信息,但是反馈在浏览器上却什么也没发生:
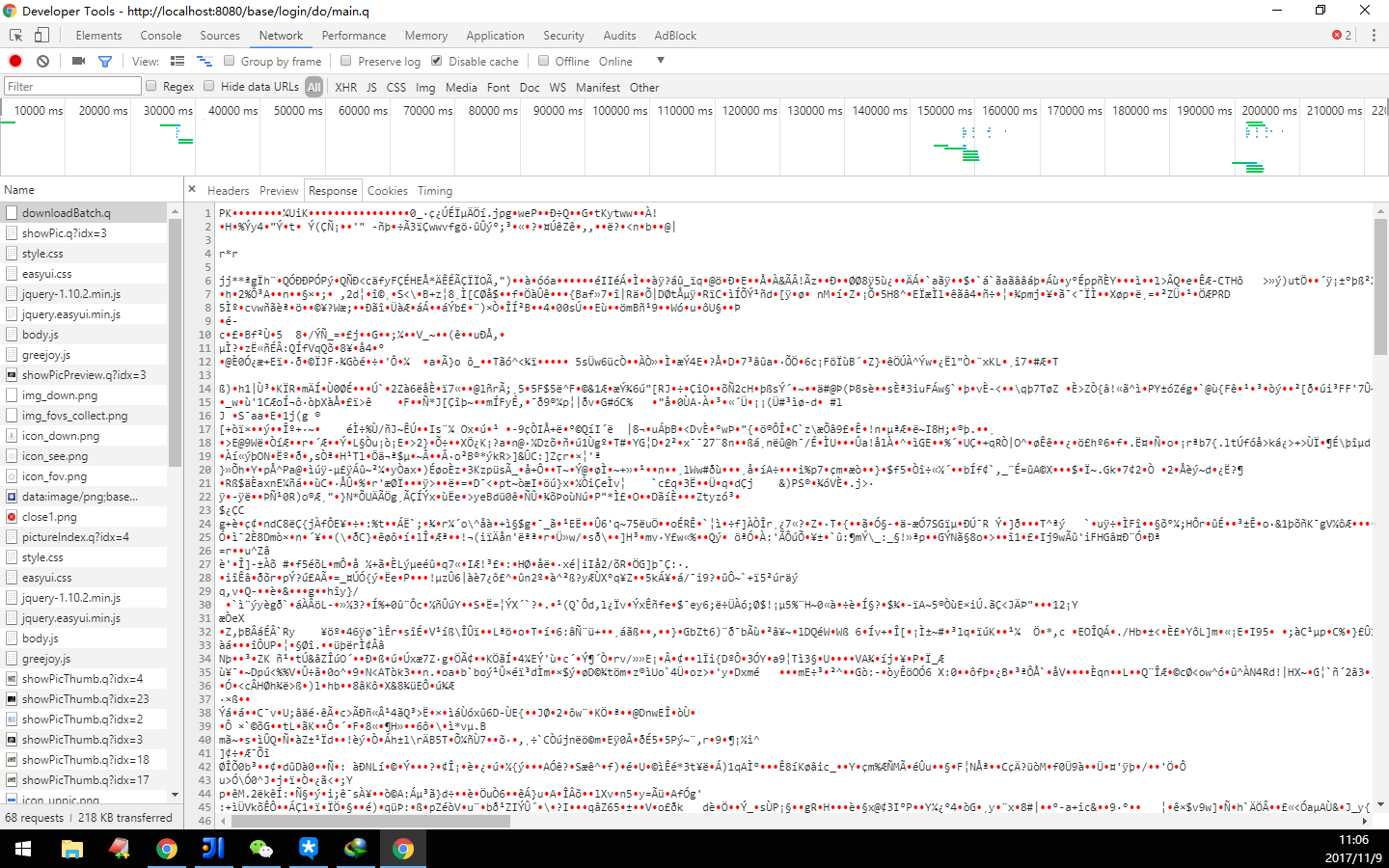
原因在于,ajax的返回值类型是json/text/html/xml类型,或者可以说ajax的发送,接受都只能是string字符串,不能流类型,所以无法实现文件下载,强用会出现response冲突。
但用ajax仍然可以获得文件的内容,该文件将被保留在内存中,无法将文件保存到磁盘。这是因为js无法和磁盘进行交互,否则这会是一个严重的安全问题,js无法调用到浏览器的下载处理机制和程序,会被浏览器阻塞。
所以在前端,简单一点,使用 window.location.href 的方式访问url,实现下载。
3、正儿八经的批量下载实现
下载前,因为批量下载需要打包为压缩包,所以要用到一个三方jar,maven地址如下:
<dependency>
<groupId>ant</groupId>
<artifactId>ant</artifactId>
<version>1.6.5</version>
</dependency>5
1
<dependency>2
<groupId>ant</groupId>3
<artifactId>ant</artifactId>4
<version>1.6.5</version>5
</dependency>先贴代码,然后再进行说明:
/**
* 批量下载
*
* @param idxs 图片的id拼接字符串,用逗号隔开
*/
public String downloadBatch(String idxs) {
String[] ids = idxs.split(",");
try {
HttpServletResponse response = ServletActionContext.getResponse();
OutputStream out = setDownloadOutputStream(response, String.valueOf(new Date().getTime()), "zip");
ZipOutputStream zipOut = new ZipOutputStream(out);
for (int i = 0; i < ids.length; i++) {
Picture picture = Picture.get(Picture.class, Long.parseLong(ids[i]));
byte[] data = picture.getData();
zipOut.putNextEntry(new ZipEntry(i + "_" + picture.getName() + "." + picture.getFormat().getValue()));
writeBytesToOut(zipOut, data, BUFFER_SIZE);
zipOut.closeEntry();
}
zipOut.flush();
zipOut.close();
} catch (IOException e) {
e.printStackTrace();
log.warn("下载失败:" + e.getMessage());
}
return null;
}x
1
/**2
* 批量下载3
*4
* @param idxs 图片的id拼接字符串,用逗号隔开5
*/6
public String downloadBatch(String idxs) {7
String[] ids = idxs.split(",");8
try {9
HttpServletResponse response = ServletActionContext.getResponse();10
OutputStream out = setDownloadOutputStream(response, String.valueOf(new Date().getTime()), "zip");11
ZipOutputStream zipOut = new ZipOutputStream(out);12
13
for (int i = 0; i < ids.length; i++) {14
Picture picture = Picture.get(Picture.class, Long.parseLong(ids[i]));15
byte[] data = picture.getData();16
zipOut.putNextEntry(new ZipEntry(i + "_" + picture.getName() + "." + picture.getFormat().getValue()));17
writeBytesToOut(zipOut, data, BUFFER_SIZE);18
zipOut.closeEntry();19
}20
zipOut.flush();21
zipOut.close();22
23
} catch (IOException e) {24
e.printStackTrace();25
log.warn("下载失败:" + e.getMessage());26
}27
28
return null;29
}/**
* 设置文件下载的response格式
*
* @param response 响应
* @param fileName 文件名称
* @param fileType 文件类型
* @return 设置后响应的输出流OutputStream
* @throws IOException
*/
private static OutputStream setDownloadOutputStream(HttpServletResponse response, String fileName, String fileType) throws IOException {
fileName = new String(fileName.getBytes(), "ISO-8859-1");
response.setHeader("Content-Disposition", "attachment;filename=" + fileName + "." + fileType);
response.setContentType("multipart/form-data");
return response.getOutputStream();
}15
1
/**2
* 设置文件下载的response格式3
*4
* @param response 响应5
* @param fileName 文件名称6
* @param fileType 文件类型7
* @return 设置后响应的输出流OutputStream8
* @throws IOException9
*/10
private static OutputStream setDownloadOutputStream(HttpServletResponse response, String fileName, String fileType) throws IOException {11
fileName = new String(fileName.getBytes(), "ISO-8859-1");12
response.setHeader("Content-Disposition", "attachment;filename=" + fileName + "." + fileType);13
response.setContentType("multipart/form-data");14
return response.getOutputStream();15
}/**
* 将byte[]类型的数据,写入到输出流中
*
* @param out 输出流
* @param data 希望写入的数据
* @param cacheSize 写入数据是循环读取写入的,此为每次读取的大小,单位字节,建议为4096,即4k
* @throws IOException
*/
private static void writeBytesToOut(OutputStream out, byte[] data, int cacheSize) throws IOException {
int surplus = data.length % cacheSize;
int count = surplus == 0 ? data.length / cacheSize : data.length / cacheSize + 1;
for (int i = 0; i < count; i++) {
if (i == count - 1 && surplus != 0) {
out.write(data, i * cacheSize, surplus);
continue;
}
out.write(data, i * cacheSize, cacheSize);
}
}1
/**2
* 将byte[]类型的数据,写入到输出流中3
*4
* @param out 输出流5
* @param data 希望写入的数据6
* @param cacheSize 写入数据是循环读取写入的,此为每次读取的大小,单位字节,建议为4096,即4k7
* @throws IOException8
*/9
private static void writeBytesToOut(OutputStream out, byte[] data, int cacheSize) throws IOException {10
int surplus = data.length % cacheSize;11
int count = surplus == 0 ? data.length / cacheSize : data.length / cacheSize + 1;12
for (int i = 0; i < count; i++) {13
if (i == count - 1 && surplus != 0) {14
out.write(data, i * cacheSize, surplus);15
continue;16
}17
out.write(data, i * cacheSize, cacheSize);18
}19
}第一段代码为下载的主方法,用到了两个子方法,分别贴在之后的第二段代码和第三段代码。
文件的下载其实很简单,刚才在叨叨IO中也提到了,所以对于网络传输下载的IO来说,整体也就三个步骤:
- 设置文件ContentType类型和文件头
- 读取文件数据为byte[]
- 将数据写入到响应response的输出流中
设置请求头信息,在方法 setDownloadOutputStream() 中已经写明了,是文件所以要告知文件处理应该为 attachement,并附上文件名(转码ISO-8859-1避免中文乱码)。而文件内容的类型,统一设置为 multipart/form-data 即可,交给浏览器自行判断下载的文件类型。
读取文件数据,因为本例中我的图片数据直接存储在数据库字段中,所以取出时直接获取的就是byte[]。如果你的方式是文件存放在本地,数据库只是存储了文件的物理地址,那么你得多做做操作,用FileInputStream把文件的内容先读出来,结果和目的都是一样的,就是获取文件的byte[]。
获得了数据,那么直接通过OutputStream的write方法写入即可。(这里的写入方法我用了循环写入,当初是想着避免内存紧张,可是现在回过头来想不对啊,读文件的时候才吃内存的,这里我已经读完了再写,循环与否已经不重要了。所以实际上应该是边读边写,才是良性的,可是我的byte[]存在数据库字段里,取出来时就全部读入到内存中了,所以这里实际上是不需要循环写入的,我这是画蛇添足了。另外,如果是从File读的话,则边读边写,见目录1叨叨IO中的小段代码)
写入到输出流了,flush()刷新一下,即可。
上面这些是对于文件下载通用的,如果是批量压缩包形式,在第一段代码中黄色部分,来进行重点说明:
- ZipOutputStream zipOut = new ZipOutputStream(out);
- //把响应的输出流包装一下而已,便于使用相关压缩方法,就像多了个包装袋
- zipOut.putNextEntry(new ZipEntry(i + "_" + picture.getName() + "." + picture.getFormat().getValue()));
- zipOut.closeEntry();
- //压缩包中的多个文件,实际上每个就是这里的ZipEntry对象,每开始写入某个文件的内容时,必须先putNextEntry(new ZipEntry(String fileName)),然后才可以写入,写完这个文件,必须使用closeEntry()说明,已经写完了第一个文件。就好像putNextEntry是在说 “我要开始写压缩包的下一个文件啦”,而closeEntry则是在说“压缩包里的这个文件我已经写完啦”。循环反复,最终把所有文件写入这个“披着压缩输出流外壳的响应输出流”
- zipOut.flush();
- 写入完成后,刷一下即可。就像去超市买东西,购物车装好了,总得结一次帐才能把东西拿走吧。当然,最后别忘了close关闭。