http://ifeve.com/flink-quick-start/
http://vinoyang.com/2016/05/02/flink-concepts/
http://wuchong.me/blog/2016/05/09/flink-internals-understanding-execution-resources/
并行数据流
程序在Flink内部的执行具有并行、分布式的特性。stream被分割成stream partition,operator被分割成operator subtask,这些operator subtasks在不同的线程、不同的物理机或不同的容器中彼此互不依赖得执行。
一个特定operator的subtask的个数被称之为其parallelism(并行度)。一个stream的并行度总是等同于其producing operator的并行度。一个程序中,不同的operator可能具有不同的并行度。
 flink-concepts_parallel-dataflow
flink-concepts_parallel-dataflow
Stream在operator之间传输数据的形式可以是one-to-one(forwarding)的模式也可以是redistributing的模式。
- One-to-one : strem(比如在source和map operator之间)维护着分区以及元素的顺序。那意味着map operator的subtask看到的元素的个数以及顺序跟source operator的subtask生产的元素的个数、顺序相同。
- Redistributing : stream(map()跟keyBy/window之间或者keyBy/window跟sink之间)的分区会发生改变。每一个operator subtask依据所选择的transformation发送数据到不同的目标subtask。例如,keyBy() (基于hash码重分区),broadcast()或者rebalance()(随机redistribution)。在一个redistribution的交换中,只有每一个发送、接收task对的顺序才会被维持(比如map()的subtask和keyBy/window的subtask)。
tasks & operator chains
出于分布式执行的目的,Flink将operator的subtask链接在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。链接的行为可以在编程API中进行指定。
下面这幅图,展示了5个subtask以5个并行的线程来执行。
 flink-concepts_tasks-chains
flink-concepts_tasks-chains
http://wuchong.me/
Flink官网文档翻译:安装部署(集群模式)
本文主要介绍如何将Flink以分布式模式运行在集群上(可能是异构的)。
环境准备
Flink 运行在所有类 UNIX 环境上,例如 Linux、Mac OS X 和 Cygwin(对于Windows),而且要求集群由一个master节点和一个或多个worker节点组成。在安装系统之前,确保每台机器上都已经安装了下面的软件:
- Java 1.7.x或更高版本
- ssh(Flink的脚本会用到sshd来管理远程组件)
如果你的集群还没有完全装好这些软件,你需要安装/升级它们。例如,在 Ubuntu Linux 上, 你可以执行下面的命令安装 ssh 和 Java :
sudo apt-get install ssh
sudo apt-get install openjdk-7-jre
SSH免密码登录
译注:安装过Hadoop、Spark集群的用户应该对这段很熟悉,如果已经了解,可跳过。*
为了能够启动/停止远程主机上的进程,master节点需要能免密登录所有worker节点。最方便的方式就是使用ssh的公钥验证了。要安装公钥验证,首先以最终会运行Flink的用户登录master节点。所有的worker节点上也必须要有同样的用户(例如:使用相同用户名的用户)。本文会以 flink 用户为例。非常不建议使用 root 账户,这会有很多的安全问题。
当你用需要的用户登录了master节点,你就可以生成一对新的公钥/私钥。下面这段命令会在 ~/.ssh 目录下生成一对新的公钥/私钥。
ssh-keygen -b 2048 -P '' -f ~/.ssh/id_rsa
接下来,将公钥添加到用于认证的authorized_keys文件中:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
最后,将authorized_keys文件分发给集群中所有的worker节点,你可以重复地执行下面这段命令:
scp ~/.ssh/authorized_keys <worker>:~/.ssh/
将上面的<worker>替代成相应worker节点的IP/Hostname。完成了上述拷贝的工作,你应该就可以从master上免密登录其他机器了。
ssh <worker>
配置JAVA_HOME
Flink 需要master和worker节点都配置了JAVA_HOME环境变量。有两种方式可以配置。
一种是,你可以在conf/flink-conf.yaml中设置env.java.home配置项为Java的安装路径。
另一种是,sudo vi /etc/profile,在其中添加JAVA_HOME:
export JAVA_HOME=/path/to/java_home/
然后使环境变量生效,并验证 Java 是否安装成功
$ source /etc/profile #生效环境变量
$ java -version #如果打印出版本信息,则说明安装成功
java version "1.7.0_75"
Java(TM) SE Runtime Environment (build 1.7.0_75-b13)
Java HotSpot(TM) 64-Bit Server VM (build 24.75-b04, mixed mode)
安装 Flink
进入下载页面。请选择一个与你的Hadoop版本相匹配的Flink包。如果你不打算使用Hadoop,选择任何版本都可以。
在下载了最新的发布包后,拷贝到master节点上,并解压:
tar xzf flink-*.tgz
cd flink-*
配置 Flink
在解压完之后,你需要编辑conf/flink-conf.yaml配置Flink。
设置jobmanager.rpc.address配置项为你的master节点地址。另外为了明确 JVM 在每个节点上所能分配的最大内存,我们需要配置jobmanager.heap.mb和taskmanager.heap.mb,值的单位是 MB。如果对于某些worker节点,你想要分配更多的内存给Flink系统,你可以在相应节点上设置FLINK_TM_HEAP环境变量来覆盖默认的配置。
最后,你需要提供一个集群中worker节点的列表。因此,就像配置HDFS,编辑*conf/slaves*文件,然后输入每个worker节点的 IP/Hostname。每一个worker结点之后都会运行一个 TaskManager。
每一条记录占一行,就像下面展示的一样:
192.168.0.100
192.168.0.101
.
.
.
192.168.0.150
译注:conf/master文件是用来做JobManager HA的,在这里不需要配置
每一个worker节点上的 Flink 路径必须一致。你可以使用共享的 NSF 目录,或者拷贝整个 Flink 目录到各个worker节点。
scp -r /path/to/flink <worker>:/path/to/
请查阅配置页面了解更多关于Flink的配置。
特别的,这几个
- TaskManager 总共能使用的内存大小(
taskmanager.heap.mb) - 每一台机器上能使用的 CPU 个数(
taskmanager.numberOfTaskSlots) - 集群中的总 CPU 个数(
parallelism.default) - 临时目录(
taskmanager.tmp.dirs)
是非常重要的配置项。
启动 Flink
下面的脚本会在本地节点启动一个 JobManager,然后通过 SSH 连接所有的worker节点(*slaves*文件中所列的节点),并在每个节点上运行 TaskManager。现在你的 Flink 系统已经启动并运行了。跑在本地节点上的 JobManager 现在会在配置的 RPC 端口上监听并接收任务。
假定你在master节点上,并在Flink目录中:
bin/start-cluster.sh
要停止Flink,也有一个 stop-cluster.sh 脚本。
添加 JobManager/TaskManager 实例到集群中
你可以使用 bin/jobmanager.sh 和 bin/taskmanager 脚本来添加 JobManager 和 TaskManager 实例到你正在运行的集群中。
添加一个 JobManager
bin/jobmanager.sh (start cluster)|stop|stop-all
添加一个 TaskManager
bin/taskmanager.sh start|stop|stop-all
确保你是在需要启动/停止相应实例的节点上运行的这些脚本。
Flink中的一些核心概念
在源码解读前我们有必要先了解一下Flink的一些基本的但却很关键的概念。这有助于帮助我们理解整个架构。在翻译文档的同时,对于有争议的或者不是非常适合用中文表达的地方,我尽量保留原始英文单词。
程序和数据流
Flink程序的基本构建块是streams和transformations(注意,DataSet在内部也是一个stream)。一个stream可以看成一个中间结果,而一个transformations是以一个或多个stream作为输入的某种operation,该operation利用这些stream进行计算从而产生一个或多个result stream。
在运行时,Flink上运行的程序会被映射成streaming dataflows,它包含了streams和transformations operators。每一个dataflow以一个或多个sources开始以一个或多个sinks结束。dataflow类似于任意的有向无环图(DAG),当然特定形式的环可以通过iteration构建。在大部分情况下,程序中的transformations跟dataflow中的operator是一一对应的关系。但有时候,一个transformation可能对应多个operator。
 flink-concepts_parallel-dataflow
flink-concepts_parallel-dataflow
并行数据流
程序在Flink内部的执行具有并行、分布式的特性。stream被分割成stream partition,operator被分割成operator subtask,这些operator subtasks在不同的线程、不同的物理机或不同的容器中彼此互不依赖得执行。
一个特定operator的subtask的个数被称之为其parallelism(并行度)。一个stream的并行度总是等同于其producing operator的并行度。一个程序中,不同的operator可能具有不同的并行度。
flink-concepts_parallel-dataflow
Stream在operator之间传输数据的形式可以是one-to-one(forwarding)的模式也可以是redistributing的模式。
- One-to-one : strem(比如在source和map operator之间)维护着分区以及元素的顺序。那意味着map operator的subtask看到的元素的个数以及顺序跟source operator的subtask生产的元素的个数、顺序相同。
- Redistributing : stream(map()跟keyBy/window之间或者keyBy/window跟sink之间)的分区会发生改变。每一个operator subtask依据所选择的transformation发送数据到不同的目标subtask。例如,keyBy() (基于hash码重分区),broadcast()或者rebalance()(随机redistribution)。在一个redistribution的交换中,只有每一个发送、接收task对的顺序才会被维持(比如map()的subtask和keyBy/window的subtask)。
tasks & operator chains
出于分布式执行的目的,Flink将operator的subtask链接在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。链接的行为可以在编程API中进行指定。
下面这幅图,展示了5个subtask以5个并行的线程来执行。
flink-concepts_tasks-chains
分布式执行
Master,Worker,Client
Flink运行时包含了两种类型的处理器:
- master处理器:也称之为JobManagers用于协调分布式执行。它们用来调度task,协调检查点,协调失败时恢复等。
Flink运行时至少存在一个master处理器。一个高可用的运行模式会存在多个master处理器,它们其中有一个是leader,而其他的都是standby。
- worker处理器:也称之为TaskManagers用于执行一个dataflow的task(或者特殊的subtask)、数据缓冲和data stream的交换。
Flink运行时至少会存在一个worker处理器。
master和worker处理器可以以如下方式中的任意一种启动:直接在物理机上启动,通过容器,或者通过像YARN这样的资源调度框架。worker连接到master,告知自身的可用性进而获得任务分配。
客户端不是运行时和程序执行的一部分。但它用于准备并发送dataflow给master。然后,客户端断开连接或者维持连接以等待接收计算结果。客户端可以以两种方式运行:要么作为Java/Scala程序的一部分被程序触发执行,要么以命令行./bin/flink run的方式执行。
 flink-concepts_processes
flink-concepts_processes
Workers,Slots,Resources
每一个worker(TaskManager)是一个JVM进程,它可能会在独立的线程上执行一个或多个subtask。为了控制一个worker能接收多少个task。worker通过task slot来进行控制(一个worker至少有一个task slot)。
每个task slot表示TaskManager拥有资源的一个固定大小的子集。假如一个TaskManager有三个slot,那么它会将其管理的内存分成三份给各个slot。资源slot化意味着一个subtask将不需要跟来自其他job的subtask竞争被管理的内存,取而代之的是它将拥有一定数量的内存储备。需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离task的受管理的内存。
通过调整task slot的数量,允许用户定义subtask之间如何互相隔离。如果一个TaskManager一个slot,那将意味着每个task group运行在独立的JVM中(该JVM可能是通过一个特定的容器启动的)。而一个TaskManager多个slot意味着更多的subtask可以共享同一个JVM。而在同一个JVM进程中的task将共享TCP连接(基于多路复用)和心跳消息。它们也可能共享数据集和数据结构,因此这减少了每个task的负载。
 flink-concepts_tasks-slots
flink-concepts_tasks-slots
默认,如果subtask是来自相同job,但不是相同的task,Flink允许subtask共享slot。结果是,一个slot可能hold住该job的整个pipeline。允许slot共享有两个好处:
- Flink集群确实需要许多task slots来让Job达到最高的并行度。不需要计算一个程序总共包含多少个task。
- 更容易获得更好的资源利用。如果没有slot共享,非密集型的source/map()的subtask将阻塞跟密集型的window的subtask一样多的占用资源。而如果有slot共享,基本的并发度通过完整地利用共享的slot资源将获得2到6倍的提升,同时仍然保证每一个TaskManager会在任务繁重的subtask之间进行合理的slot共享。
slot共享行为可以通过API来控制,以防止不合理的共享。这个机制称之为resource groups,它定义了subtask可能共享的slot是什么资源。
作为一个约定俗成的规则,task slot推荐的默认值是CPU的核数。基于超线程技术,每个slot占用两个或者更多的实际线程上下文。
 flink-concepts_slot-sharing
flink-concepts_slot-sharing
时间和窗口
聚合事件(比如count,sum)工作起来比起批处理略微有些不同。例如,它不能一次完成对流中所有元素的数量统计,然后返回结果。因为流通常都是无限的(无边界)。取而代之的是,在流上的聚合(count,sum等)被隔离到window域中,比如,“统计最近5分钟的数量”或“对最近100个元素求和”。
窗口可以是时间驱动的(比如,每30秒)也可以是数据驱动的(比如,每100个元素)。通常我们将窗口划分为:tumbing windows(不重叠),sliding windows(有重叠)和session windows(有空隙的活动)。
 flink-concepts_windows
flink-concepts_windows
时间
当在流式编程中涉及到时间的(比如定义一个窗口),可能会牵扯到时间的不同定义:
- Event Time:指一个事件的创建时间。通常在event中用时间戳来描述,比如,可能是由生产事件的传感器或生产服务来附加。Flink访问事件时间戳通过时间戳分配器。
- Ingestion time:指一个事件从source operator进入Flink dataflow的时间。
- Processing time:每一个执行一个基于时间操作的operator的本地时间。
 flink-concepts_event-ingestion-processing-time
flink-concepts_event-ingestion-processing-time
状态和失效容忍
在dataflow中的许多操作一次只关注一个独立的事件(比如一个事件解析器),还有一些操作能记住多个独立事件的信息(比如,window operator),而这些操作被称为stateful(有状态的)。
有状态的操作,其状态被维护的地方,可以将其看作是一个内嵌的key/value存储器。状态和流一起被严格得分区和分布以供有状态的operator读取。因此,访问key/value的状态仅能在keyed streams中(在执行keyBy()函数之后产生keyed stream),并且只能根据当前事件的键来访问其值。对齐stream的键和状态可以确保所有的状态更新都是本地操作,在不需要事务开销的情况下保证一致性。这个对齐机制也允许Flink重新分布状态并显式调整stream的分区。
 flink-concepts_state-partitioning
flink-concepts_state-partitioning
用于失败容忍的检查点
Flink实现失败容忍使用了流重放和检查点的混合机制。一个检查点会在流和状态中定义一个一致点,在该一致点streaming dataflow可以恢复并维持一致性(exactly-once的处理语义)。在最新的检查点之后的事件或状态更新将在input stream中被重放。
检查点的设置间隔意味着在执行时对失败容忍产生的额外开销以及恢复时间(也决定了需要被重放的事件数)。
 flink-concepts_checkpoints
flink-concepts_checkpoints
状态的最终存储
给key/value构建索引的数据结构最终被存储的地方取决于状态最终存储的选择。其中一个选择是在内存中基于hash map,另一个是RocksDB。另外用来定义Hold住这些状态的数据结构,状态的最终存储也实现了基于时间点的快照机制,给key/value做快照,并将快照作为检查点的一部分来存储。
基于流的批处理
Flink执行批处理程序是将其作为流处理程序的一个特例来看待。它将其看作有界的流(有限数量的元素)。DataSet在内部被当作一个流数据,因此上面的这些适用于流处理的这些概念在批处理中同样适用,只有很少的几个例外:
- DataSet的编程API不适用检查点。恢复机制是通过重放完整的流数据来进行。那是合理的,因为输入时有界的。它将开销更多地引入到恢复操作上,但另一方面也使得运行时的常规流程代价更低,因为它规避了检查点机制。
- DataSet的有状态的operation API简单地使用in-memory/out-of-core的数据结构,而不是基于key/value的索引机制
- DataSet的API引进了独特的同步迭代机制(基于superstep),它仅在有界的流中存在。
文档翻译自Flink DataStream API Programming Guide
-----------------------------------------------------------------------
Flink中的DataStream程序是实现在数据流上的transformation(如filtering,updating state, defining windows,aggregating)的普通程序。创建数据流的来源多种多样(如消息队列,socket流,文件等)。程序通过data sink返回结果,如将数据写入文件,或发送到标准输出(如命令行终端)。Flink程序可以在多种上下文中运行,如独立运行或是嵌入在其他程序中执行。程序的执行可以发生在本地JVM,或者在一个拥有许多设备的集群上。
有关介绍Flink API基础概念的文档,请见basic concepts
为了创建你自己的Flink DataStream程序,我们鼓励你从文档anatomy of a Flink Program开始,且欢迎你添加自己的transformations。该文档接下来的部分是额外的operation和进阶特性的参考文档。
一、示例程序
下面的程序是一个完整的流式窗口word count应用,它计算出在web socket的大小为5秒的窗口中的出现各个单词的数量。你可以复制 & 粘贴代码并在本地运行。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
dataStream.print();
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
要运行该示例程序,首先从终端运行netcat来开始输入流
nc -lk 9999
仅需要输入一些单词,这些将是word count程序的输入数据。如果你想看到count大于1的结果,在5秒内重复输入同一个单词。
二、DataStream Transformations
Data transformation会将一或多个DataStream转换成一个新的DataStream。程序可以将多个transformation结合形成复杂的拓扑结构(topology)。
本小节给出了所有可用的transformation的描述。
|
Transformation |
描述 |
|
Map DataStream -> DataStream |
获取一个element并产出一个element。下例是一个将输入*2的map方法: DataStream<Integer> dataStream = //... |
|
FlapMap DataStream -> DataStream |
获取一个element,并产生出0、1或多个element。下例是一个为句子分词的flatmap方法 dataStream.flatMap(new FlatMapFunction<String, String>() { |
|
Filter DataStream -> DataStream |
在每个获取的element上运行一个boolean方法,留下那些方法返回true的element。下例是一个过滤掉0值的filter dataStream.filter(new FilterFunction<Integer>() { |
|
KeyBy |
将流逻辑分为不相交的分区,每个分区包含的都是具有相同key的element,该分区方法使用hash分区实现。定义key的方法见于Keys。下例是一个返回KeyedDataStream的transformation。 dataStream.keyBy("someKey") // Key by field "someKey" |
|
Reduce KeyedStream -> DataStream |
一个在keyed data stream上“滚动”进行的reduce方法。将上一个reduce过的值和当前element结合,产生新的值并发送出。下例是一个创建部分和的reduce方法。 keyedStream.reduce(new ReduceFunction<Integer>() { |
|
Fold KeyedStream -> DataStream |
一个在带有初始值的数据流上“滚动”进行的fold方法。将上一个fold的值和当前element结合,产生新的值并发送出。下例是一个fold方法,当应用于序列{1, 2, 3, 4, 5}时,它发出序列{"start-1", "start-1-2", "start-1-2-3" …}。 DataStream<String> result = keyedStream.fold("start", new FoldFunction<Integer, String>() { |
|
Aggregations KeyedStream -> DataStream |
在一个keyed DataStream上“滚动”进行聚合的方法。其中,min和minBy的区别在于min返回最小值,而minBy返回的是带有在此域中最小值的element(max和maxBy一样如此)。 keyedStream.sum(0); |
|
Window KeyedStream - > WindowedStream |
Window可以定义在已经分区的KeyedStream上。窗口将根据一些特征(如最近5秒到达的数据)将数据按其各自的key集合在一起。有关窗口的完整描述见于windows // Last 5 seconds of data dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5))); |
|
WindowAll DataStream -> AllWindowedStream |
Window可以定义在普通的DataStream上。窗口将根据一些特征(如最近5秒到达的数据)将所有Stream事件集合在一起。有关窗口的完整描述见于windows dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))); // Last 5 seconds of data |
|
Window Apply WindowedStream -> DataStream AllWindowedStream -> DataStream |
将一个一般函数应用到window整体上去,下面是一个人工计算window中所有element的总和的应用。 windowedStream.apply (new WindowFunction<Tuple2<String,Integer>, Integer, Tuple, Window>() { // applying an AllWindowFunction on non-keyed window stream |
|
Window Reduce WindowedStream -> DataStream |
对窗口应用一个功能性reduce方法并返回reduce的结果 windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>() { |
|
Window Fold Windowed Stream -> DataStream |
对窗口应用一个功能性fold方法。下例代码在应用到序列(1, 2, 3, 4, 5)时,它将该序列fold成为字符串"start-1-2-3-4-5" windowedStream.fold("start-", new FoldFunction<Integer, String>() { |
|
Aggregations on windows WindowedStream -> DataStream |
对窗口中的内容聚合。其中,min和minBy的区别在于min返回最小值,而minBy返回的是带有在此域中最小值的element(max和maxBy一样如此)。 windowedStream.sum(0); |
|
Union DataStream* -> DataStream |
将2个或多个data stream合并创建出一个新的包含所有stream的element的stream。注意:如果你对一个data stream自己进行union操作,则在返回的结果中,每个element都会出现2个。 dataStream.union(otherStream1, otherStream2, ...); |
|
Window Join DataStream, DataStream -> DataStream |
在给定key和普通window中,将2个DataStream进行Join操作 dataStream.join(otherStream) |
|
Window CoGroup DataStream, DataStream -> DataStream |
在给定key和普通window中,对2个DataStream进行CoGroup操作。 dataStream.coGroup(otherStream) |
|
Connect DataStream, DataStream -> ConnectedStreams |
在保留两个DataStream的类型的情况下,将二者"连接"起来。Connect使我们可以共享两个Stream的状态 DataStream<Integer> someStream = //... ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream); |
|
CoMap, CoFlatMap ConnectedStreams -> DataStream |
该操作类似于map和flatMap针对连接的Data Stream版本。Sd connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() { @Override connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() { @Override @Override |
|
Split DataStream -> SplitStream |
根据某些标准将Stream分割成2个或更多的stream SplitStream<Integer> split = someDataStream.split(new OutputSelector<Integer>() { |
|
Select SplitStream -> DataStream |
从SplitStream中选择1个或多个stream SplitStream<Integer> split; |
|
Iterate DataStream -> IterativeStream -> DataStream |
通过将一个Operator的输出重定向到前面的某个Operator的方法,在数据流图中创建一个“反馈”循环。这在定义持续更新模型的算法时十分有用。下面的例子从一个Stream开始,并持续应用迭代体(Iteration body)。大于0的element被送回到反馈通道,而其他的element则被转发到下游。相关完整描述请见Iterations IterativeStream<Long> iteration = initialStream.iterate(); |
|
Extract Timestamps DataStream -> DataStream |
通过从数据中抽取时间戳来使得通过使用事件时间语义的窗口可以工作。详情见于Event Time。 stream.assignTimestamps (new TimeStampExtractor() {...}); |
接下来的Transformation是对Tuple类型的data stream可用的Transformation:
|
Transformation |
描述 |
|
Project DataStream -> DataStream |
从tuple中选择出域的子集而产生新的DataStream DataStream<Tuple3<Integer, Double, String>> in = // [...] |
物理级分割(Physical Partitioning)
如果需要,Flink同样提供了在进行一次transformation后针对精确stream分割的低层次的控制(low-level control),它们通过以下几个方法实现。
|
Transformations |
描述 |
|
Custom partitioning DataStream -> DataStream |
使用一个用户自定义的Partitioner来对每个element选择目标任务sd dataStream.partitionCustom(partitioner, "someKey"); |
|
Random partitioning DataStream -> DataStream |
根据均匀分布来随机分割element dataStream.shuffle(); |
|
Rebalancing(轮询分割) DataStream -> DataStream |
轮询分割element,创建相同负荷的分割。对数据变形(data skew)时的性能优化十分有用s dataStream.rebalance(); |
|
Rescaling DataStream -> DataStream |
将element轮询分割到下游Operator子集中去。这在你想流水线并行时十分有用,例如,需要从每个并行的source实例中将数据fan out到一个有着一些mapper来分发负载,但是又不想要函数rebalance()那样引起的完全rebalance的效果时。这就需要仅在本地传输数据,而不是需要从网络传输,这需要依赖其他诸如TaskManager的任务槽数量等等configuration值。 dataStream.rescale(); |
|
Broadcasting DataStream -> DataStream |
将element广播到每一个分割中去 dataStream.broadcast(); |
链接任务以及资源组(Task chaining & resource groups)
将两个transformation链接起来意味着将它们部署在一起(co-locating),共享同一个线程来获得更好的性能。Flink默认地尽可能地链接Operator(如两个连续的map transformation)。如有需要,API还给出了细粒度的链接控制:
使用StreamExecutionEnvironment.disableOperatorChaining()来关闭整个Job的链接操作。下面表格中的方法则是更加细粒度的控制函数,注意,由于这些函数引用的是前一个transformation,所以它们仅仅在一个DataStream的transformation后使用才是正确的,例如someStream.map( … ).startNewChain()是正确的,而someStream.startNewChain()是错误的。
一个资源组就是Flink中的一个任务槽,如有需要,你可以人工孤立某个Operator到一个独立的任务槽中。
|
Transformation |
描述 |
|
startNewChain() |
以当前Operator起点,开始一个新的链接。在下例中,两个mapper将会被链接而filter则不会与第一个mapper链接 someStream.filter(...).map(...).startNewChain().map(...); |
|
disableChaining() |
下例中,将不会链接mapOperator。 someStream.map(...).disableChaining(); |
|
slotSharingGroup() |
设置一个Operation的共享任务槽的分组。Flink将会把同一个任务槽共享组的Operation放到同一个任务槽中,而不在同一个任务槽共享组的Operation放到其他任务槽中。这可以用来孤立任务槽。如果所有的输入Operation都在同一个任务槽共享组中,则该任务槽共享组会继承下来。任务槽共享组的默认名为"default",Operation可以通过调用slotSharingGroup("default")来定义其名称。 someStream.filter(...).slotSharingGroup("name"); |
三、数据源
数据源可以通过StreamExecutionEnvironment.addSource(sourceFunction)来创建数据源。你可以使用Flink提供的source方法,也可以通过实现SourceFunction来编写自定义的非并行数据源,也可以通过实现ParallelSourceFunction接口或继承RichParallelSourceFunction来编写自定义并行数据源。
以下是几个预定义的数据流源,可以通过StreamExecutionEnvironment来访问:
1. 基于文件的:
- readTextFile(path) / TextInputFormat - 以行读取方式读文件并返回字符串
- readFile(path) / 任意输入格式 - 按用输入格式的描述读取文件
- readFileStream - 创建一个stream,在文件有改动时追加element
2. 基于Socket的:
- socketTextStream - 从socket读取,element可以通过分割符来分开
3. 基于Collection的:
- fromCollection(Collection) - 从Java.util.Collection创建一个数据流。collection中所有的element都必须是同一类型的。
- fromCollection(Iterator, Class) - 从一个迭代器中创建一个数据流。class参数明确了迭代器返回的element的类型。
- fromElement(T …) - 从一个给定的对象序列创建一个数据流。所有对象都必须是同一类型的。
- fromParallelCollection(SplittableIterator, Class) - 从一个迭代器中创建一个并行数据流。class参数明确了迭代器返回的element的类型。
- generateSequence(from, to) - 从一个给定区间中生成一个并行数字序列。
4. 自定义:
- addSource - 附上一个新的source方法。例如,通过调用addSource(new FlinkKafkaConsumer08<>(…))来从Apache Kafka读取数据,更多信息见于connector
四、Data Sink
Data Sink消耗DataStream并将它们转发到文件、socket、外部系统或打印它们。Flink自带了许多内置的输出格式,封装为DataStream的operation中:
- writeAsText() / TextOutputFormat - 以行字符串的方式写文件,字符串通过调用每个element的toString()方法获得。
- writeAsCsv(…) / CsvOutputFormat - 以逗号分隔的值来讲Tuple写入文件,行和域的分隔符是可以配置的。每个域的值是通过调用object的toString()方法获得的。
- print() / printToErr() - 将每个element的toString()值打印在标准输出 / 标准错误流中。可以提供一个前缀(msg)作为输出的前缀,使得在不同print的调用可以互相区分。如果并行度大于1,输出也会以task的标识符(identifier)为产生的输出的前缀。
- writeUsingOutputFormat() / FileOutputFormat - 自定义文件输出所用的方法和基类,支持自定义object到byte的转换。
- writeToSocket - 依据SerializationSchema将element写到socket中。
- addSink - 调用自定义sink方法,Flink自带连接到其他系统的connector(如Apache Kafka),这些connector都以sink方法的形式实现。
注意DataStream的write*()函数主要用于debug,它们不参与Flink的检查点,这意味着这些方法通常处于“至少一次(at-least-once)“的执行语义下。flush到目标系统的数据依赖于OutputFormat的实现,这意味着不是所有发送到OutputFormat的element都会立即出现在目标系统中,此外,在失效的情况下,这些数据很可能会丢失。
故为了可靠性以及将stream“恰好一次(exact once)”地传入文件系统,我们应当使用flink-connector-filesystem。此外,通过实现“.addSink(…)”的自定义内容会参加Flink的检查点机制,故会保证“恰好一次”的执行语义。
五、迭代(Iterations)
迭代流程序实现了一个阶段方法并将之嵌入到一个IterativeStream中。作为一个可能永远不会结束的程序,它没有最大迭代数,反之,你需要使用split或filter的transformation来明确流的哪一部分会被反馈到迭代中,哪一部分则继续转发到下游。这里,我们使用filter作为例子,我们定义IterativeStream:
IterativeStream<Integer> iteration = input.iterate();
然后,我们定义在循环中将要进行的逻辑处理,我们通过一系列transformation来实现(这里用了一个简单的map transformation):
DataStream<Integer> iterationBody = iteration.map(/* this is executed many times */);
我们可以调用IterativeStream的closeWith(feedbackStream)函数来关闭一个迭代并定义迭代尾。传递给closeWith方法的DataStream将会反馈回迭代头。分割出用来反馈的stream的部分和向前传播的stream部分通常的方法便是使用filter来进行分割。这些filter可以定义诸如"termination"逻辑,即element将会传播到下游,而不是被反馈回去。
iteration.closeWith(iterationBody.filter(/* one part of the stream */));
DataStream<Integer> output = iterationBody.filter(/* some other part of the stream */);
默认地,反馈的那部分流将会自动设置为迭代头的输入,要想重载该行为,用户需要设置closeWith函数中的一个boolean参数。例如,下面是一个持续将整数序列中的数字减1知道它们变为0的程序:
DataStream<Long> someIntegers = env.generateSequence(0, 1000);
IterativeStream<Long> iteration = someIntegers.iterate();
DataStream<Long> minusOne = iteration.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
return value - 1 ;
}
});
DataStream<Long> stillGreaterThanZero = minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return (value > 0);
}
});
iteration.closeWith(stillGreaterThanZero);
DataStream<Long> lessThanZero = minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return (value <= 0);
}
});
六、执行参数
StreamExecutionEnvironment包含ExecutionConfig,它可以使用户设置job的确切运行时配置值。
请参考execution configuration来查看参数的解释。特别的,以下这些参数仅适用于DataStream API:
enableTimestamps() / disableTimestamps():在每一个source发出的事件上附加上一个时间戳。函数areTimestampsEnabled()可以返回该状态的当前值。
setAutoWatermarkInterval(long milliseconds):设置自动水印发布(watermark emission)区间。你可以通过调用函数getAutoWatermarkInterval()来获取当前值。
6.1 容错
文档Fault Tolerance Documentation描述了打开并配置Flink的检查点机制的选项和参数
6.2 控制执行时间
默认的,element在网络传输时不是一个个单独传输的(这会导致不必要的网络流量),而是缓存后传输。缓存(是在设备间传输的实际单位)的大小可以在Flink的配置文件中设置。尽管该方法有益于优化吞吐量,他会在stream到达不够快时导致执行时间方面的问题。为了控制吞吐量和执行时间,你可以在执行环境(或独立的Operator)中调用env.setBufferTimeout(timeoutMillis)来设置等待装满buffer的最大等待时间,在这个时间过后,不管buffer是否已满,它都会自动发出。该默认超时时间是100ms。下例是设置API的用法:
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.setBufferTimeout(timeoutMillis);
env.genereateSequence(1,10).map(new MyMapper()).setBufferTimeout(timeoutMillis);
要最大化吞吐量,设置setBufferTimeout(-1)来去除超时时间,则buffer仅在它满后才会被flush。要最小化执行时间,设置timeout为一个接近0的数字(如5ms或10ms)。应当避免设置Timeout为0,因为它会造成严重的性能下降。
七、Debugging
在分布式集群上运行流程序之前,确保算法正确执行很重要。因此,实现数据分析程序通常需要递增的检查结果、debug、优化的过程。
Flink提供了可以显著简化数据分析程序的开发过程的特性,即可以在IDE中本地进行debug、注入测试数据、以及结果数据的收集等。本节对如何简化Flink程序开发提出几点建议。
7.1 本地执行环境
LocalStreamEnvironment在创建它的同一个JVM进程下创建Flink系统。如果你从IDE中启动一个LocalEnvironment,你可以在代码中设置断点来简单地debug你的程序。下例为LocalEnvironment是如何创建并使用的:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
DataStream<String> lines = env.addSource(/* some source */);
// build your program
env.execute();
7.2 Collection数据源
Flink提供基于Java collection的特殊数据源来方便测试。一旦程序测试之后,source和sink可以简单地替代为对外部系统的读取/写出的source和sink。Collection数据源使用方法如下:
// Create a DataStream from a list of elements
DataStream<Integer> myInts = env.fromElements(1, 2, 3, 4, 5);
// Create a DataStream from any Java collection
List<Tuple2<String, Integer>> data = ...
DataStream<Tuple2<String, Integer>> myTuples = env.fromCollection(data);
// Create a DataStream from an Iterator
Iterator<Long> longIt = ...
DataStream<Long> myLongs = env.fromCollection(longIt, Long.class);
注意:当前Collection数据源需要实现Serializable接口的数据类型和迭代器。此外,Collection数据源无法并行执行(并行度=1)
7.3 迭代器Data Sink
Flink同样提供了一个收集测试和debug的DataStream结果的sink,它的使用方式如下:
import org.apache.flink.contrib.streaming.DataStreamUtils
DataStream<Tuple2<String, Integer>> myResult = ...
Iterator<Tuple2<String, Integer>> myOutput = DataStreamUtils.collect(myResult)
Flink 原理与实现:数据流上的类型和操作
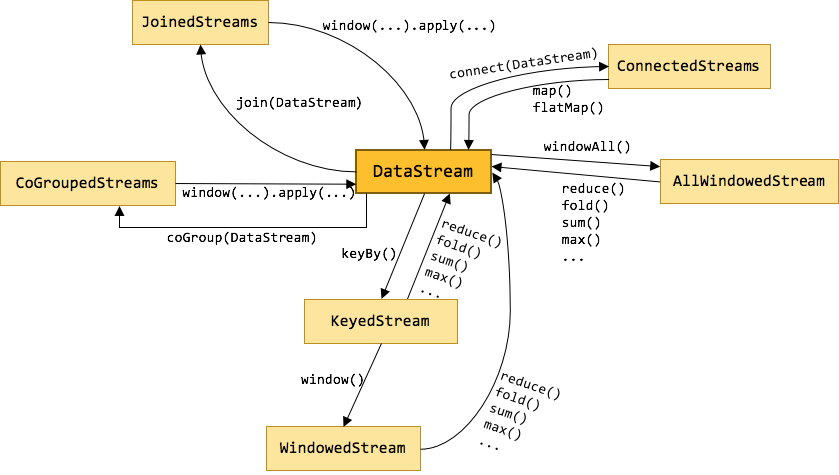
Flink 为流处理和批处理分别提供了 DataStream API 和 DataSet API。正是这种高层的抽象和 flunent API 极大地便利了用户编写大数据应用。不过很多初学者在看到官方 Streaming 文档中那一大坨的转换时,常常会蒙了圈,文档中那些只言片语也很难讲清它们之间的关系。所以本文将介绍几种关键的数据流类型,它们之间是如何通过转换关联起来的。下图展示了 Flink 中目前支持的主要几种流的类型,以及它们之间的转换关系。
DataStream
DataStream 是 Flink 流处理 API 中最核心的数据结构。它代表了一个运行在多个分区上的并行流。一个 DataStream 可以从 StreamExecutionEnvironment 通过env.addSource(SourceFunction) 获得。
DataStream 上的转换操作都是逐条的,比如 map(),flatMap(),filter()。DataStream 也可以执行 rebalance(再平衡,用来减轻数据倾斜)和 broadcaseted(广播)等分区转换。
|
val stream: DataStream[MyType] = env.addSource(new FlinkKafkaConsumer08[String](...))
val str1: DataStream[(String, MyType)] = stream.flatMap { ... }
val str2: DataStream[(String, MyType)] = stream.rebalance()
val str3: DataStream[AnotherType] = stream.map { ... }
|
上述 DataStream 上的转换在运行时会转换成如下的执行图:
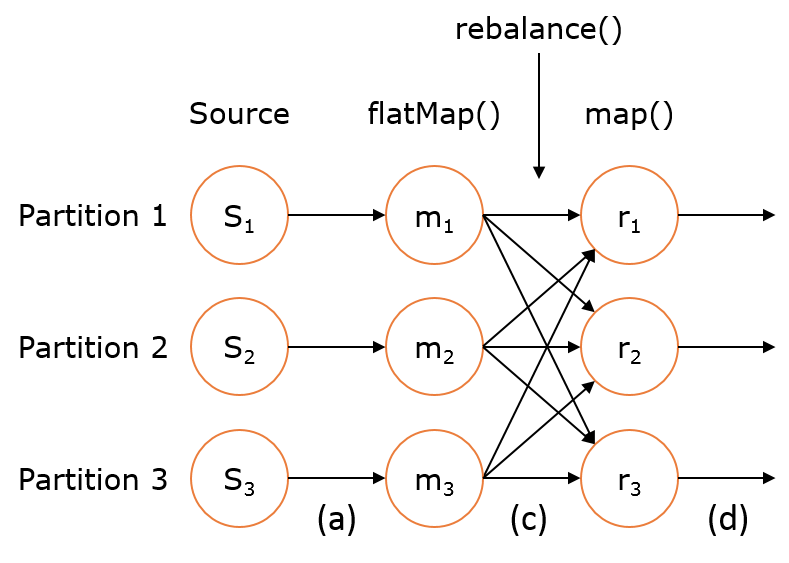
如上图的执行图所示,DataStream 各个算子会并行运行,算子之间是数据流分区。如 Source 的第一个并行实例(S1)和 flatMap() 的第一个并行实例(m1)之间就是一个数据流分区。而在 flatMap() 和 map() 之间由于加了 rebalance(),它们之间的数据流分区就有3个子分区(m1的数据流向3个map()实例)。这与 Apache Kafka 是很类似的,把流想象成 Kafka Topic,而一个流分区就表示一个 Topic Partition,流的目标并行算子实例就是 Kafka Consumers。
KeyedStream
KeyedStream用来表示根据指定的key进行分组的数据流。一个KeyedStream可以通过调用DataStream.keyBy()来获得。而在KeyedStream上进行任何transformation都将转变回DataStream。在实现中,KeyedStream是把key的信息写入到了transformation中。每条记录只能访问所属key的状态,其上的聚合函数可以方便地操作和保存对应key的状态。
WindowedStream & AllWindowedStream
WindowedStream代表了根据key分组,并且基于WindowAssigner切分窗口的数据流。所以WindowedStream都是从KeyedStream衍生而来的。而在WindowedStream上进行任何transformation也都将转变回DataStream。
|
val stream: DataStream[MyType] = ...
val windowed: WindowedDataStream[MyType] = stream
.keyBy("userId")
.window(TumblingEventTimeWindows.of(Time.seconds(5))) // Last 5 seconds of data
val result: DataStream[ResultType] = windowed.reduce(myReducer)
|
上述 WindowedStream 的样例代码在运行时会转换成如下的执行图:
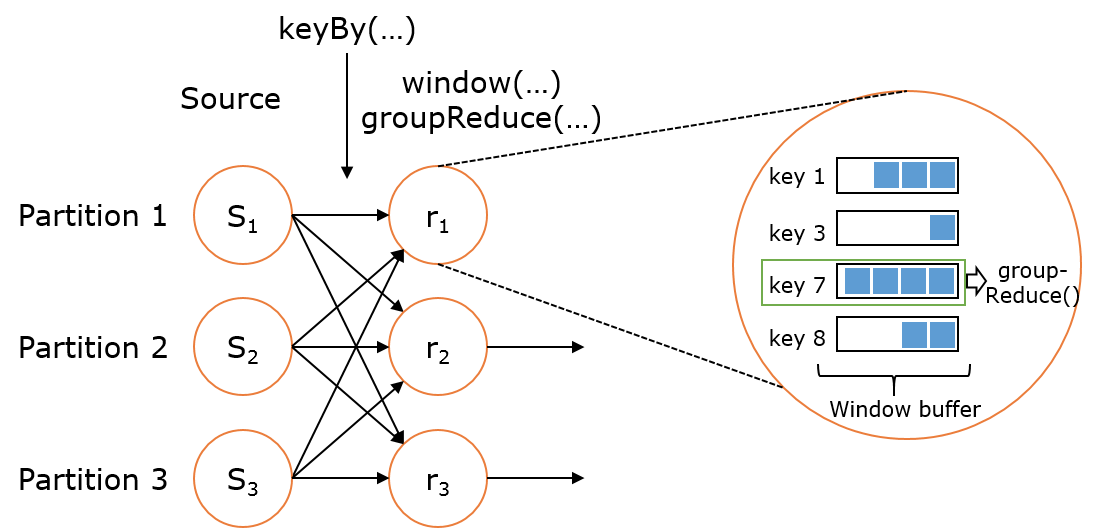
Flink 的窗口实现中会将到达的数据缓存在对应的窗口buffer中(一个数据可能会对应多个窗口)。当到达窗口发送的条件时(由Trigger控制),Flink 会对整个窗口中的数据进行处理。Flink 在聚合类窗口有一定的优化,即不会保存窗口中的所有值,而是每到一个元素执行一次聚合函数,最终只保存一份数据即可。
在key分组的流上进行窗口切分是比较常用的场景,也能够很好地并行化(不同的key上的窗口聚合可以分配到不同的task去处理)。不过有时候我们也需要在普通流上进行窗口的操作,这就是 AllWindowedStream。AllWindowedStream是直接在DataStream上进行windowAll(...)操作。AllWindowedStream 的实现是基于 WindowedStream 的(Flink 1.1.x 开始)。Flink 不推荐使用AllWindowedStream,因为在普通流上进行窗口操作,就势必需要将所有分区的流都汇集到单个的Task中,而这个单个的Task很显然就会成为整个Job的瓶颈。
JoinedStreams & CoGroupedStreams
双流 Join 也是一个非常常见的应用场景。深入源码你可以发现,JoinedStreams 和 CoGroupedStreams 的代码实现有80%是一模一样的,JoinedStreams 在底层又调用了 CoGroupedStreams 来实现 Join 功能。除了名字不一样,一开始很难将它们区分开来,而且为什么要提供两个功能类似的接口呢??
实际上这两者还是很点区别的。首先 co-group 侧重的是group,是对同一个key上的两组集合进行操作,而 join 侧重的是pair,是对同一个key上的每对元素进行操作。co-group 比 join 更通用一些,因为 join 只是 co-group 的一个特例,所以 join 是可以基于 co-group 来实现的(当然有优化的空间)。而在 co-group 之外又提供了 join 接口是因为用户更熟悉 join(源于数据库吧),而且能够跟 DataSet API 保持一致,降低用户的学习成本。
JoinedStreams 和 CoGroupedStreams 是基于 Window 上实现的,所以 CoGroupedStreams 最终又调用了 WindowedStream 来实现。
|
val firstInput: DataStream[MyType] = ...
val secondInput: DataStream[AnotherType] = ...
val result: DataStream[(MyType, AnotherType)] = firstInput.join(secondInput)
.where("userId").equalTo("id")
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new JoinFunction () {...})
|
上述 JoinedStreams 的样例代码在运行时会转换成如下的执行图:
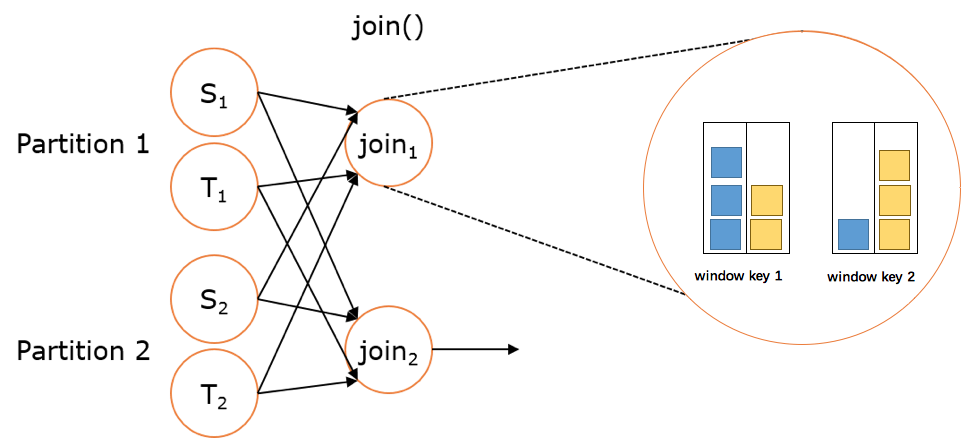
双流上的数据在同一个key的会被分别分配到同一个window窗口的左右两个篮子里,当window结束的时候,会对左右篮子进行笛卡尔积从而得到每一对pair,对每一对pair应用 JoinFunction。不过目前(Flink 1.1.x)JoinedStreams 只是简单地实现了流上的join操作而已,距离真正的生产使用还是有些距离。因为目前 join 窗口的双流数据都是被缓存在内存中的,也就是说如果某个key上的窗口数据太多就会导致 JVM OOM(然而数据倾斜是常态)。双流join的难点也正是在这里,这也是社区后面对 join 操作的优化方向,例如可以借鉴Flink在批处理join中的优化方案,也可以用ManagedMemory来管理窗口中的数据,并当数据超过阈值时能spill到硬盘。
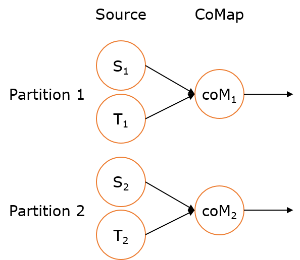
ConnectedStreams
在 DataStream 上有一个 union 的转换 dataStream.union(otherStream1, otherStream2, ...),用来合并多个流,新的流会包含所有流中的数据。union 有一个限制,就是所有合并的流的类型必须是一致的。ConnectedStreams 提供了和 union 类似的功能,用来连接两个流,但是与 union 转换有以下几个区别:
- ConnectedStreams 只能连接两个流,而 union 可以连接多于两个流。
- ConnectedStreams 连接的两个流类型可以不一致,而 union 连接的流的类型必须一致。
- ConnectedStreams 会对两个流的数据应用不同的处理方法,并且双流之间可以共享状态。这在第一个流的输入会影响第二个流时, 会非常有用。
如下 ConnectedStreams 的样例,连接 input 和 other 流,并在input流上应用map1方法,在other上应用map2方法,双流可以共享状态(比如计数)。
|
val input: DataStream[MyType] = ...
val other: DataStream[AnotherType] = ...
val connected: ConnectedStreams[MyType, AnotherType] = input.connect(other)
val result: DataStream[ResultType] =
connected.map(new CoMapFunction[MyType, AnotherType, ResultType]() {
override def map1(value: MyType): ResultType = { ... }
override def map2(value: AnotherType): ResultType = { ... }
})
|
当并行度为2时,其执行图如下所示:
总结
本文介绍通过不同数据流类型的转换图来解释每一种数据流的含义、转换关系。后面的文章会深入讲解 Window 机制的实现,双流 Join 的实现等。