G1之前收集器的特点
-
- 年轻代和老年代是各自独立且连续的内存块
- 年轻代收集器使用 eden + S0 + S1 进行复制算法
- 老年代收集必须扫描整个老年代区域
- 都是以尽可能的少而快速地执行 GC 为设计原则
G1 是什么
-
- G1 是一种面向服务端的垃圾收集器,应用在多核处理器和大容量内存环境中,在实现高吞吐量的同时,尽可能的满足垃圾收集器的暂停时间要求
- 像 CMS 收集器一样,能与应用程序线程并发执行,整理空闲空间更快,需要更多的时间来预测 GC 停顿时间,不希望牺牲大量的吞吐性能,不需要更大的 JAVA Heap
- G1 收集器的设计目的是取代 CMS 收集器,同时与 CMS 相比,G1 垃圾收集器是一个有整理内存过程的垃圾收集器,不会产生很多内存碎片。G1 的 Stop The World 更可控,G1 在停顿上添加了预测机制,用户可以指定期望的停顿时间
- JDK9 中将 G1 变成默认垃圾收集器来代替 CMS,它是一款面向服务应用的收集器
- 主要改变是 Eden、Survivor 和 Tenured 等内存区域不再是连续的,而是变成了一个个大小一样的 region,每个 region 从 1M 到 32M 不等,一个 region 有可能属于 Eden、Survivor 或者 Tenured 内存区域。
G1特点
-
- G1 能充分利用多 CPU、多核环境硬件优势,尽量缩短 STW
- G1 整体采用标记-整理算法,局部是通过是通过复制算法,不会产生内存碎片
- 宏观上看 G1 之中不在区分年轻代和老年代,被内存划分为多个独立的子区域
- G1 收集器里面将整个的内存区域混合在一起,但其本身依然在小范围内要进行年轻代和老年代的区分。保留了新生代和老年代,但他们不在是物理隔离,而是一部分 Region 的集合且不需要 Region 是连续的,也就是说依然会采用不同的 GC 方式来处理不同的区域
- G1 虽然也是分代收集器,但整个内存分区不存在物理上的年轻代和老年代的区别,也不需要完全独立的 Survivor to space 堆做复制准备。G1 只有逻辑上的分代概念,或者说每个分区都可能随 G1 的运行在不同代之间前后切换
底层原理
-
Region
-
-
Region 区域化垃圾收集器:最大好处是化整为零,避免全内存扫描,只需要按照区域来进行扫描即可
-
-
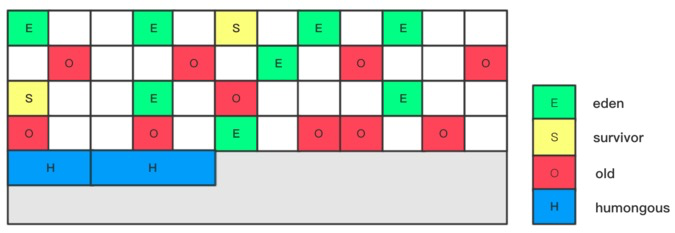
- G1的内存结构和传统的内存空间划分有比较的不同。G1将内存划分成了多个大小相等的Region(默认是512K),Region逻辑上连续,物理内存地址不连续。同时每个Region被标记成E、S、O、H,分别表示Eden、Survivor、Old、Humongous。其中E、S属于年轻代,O与H属于老年代。
- H表示Humongous。从字面上就可以理解表示大的对象(下面简称H对象)。当分配的对象大于等于Region大小的一半的时候就会被认为是巨型对象。H对象默认分配在老年代,可以防止GC的时候大对象的内存拷贝。通过如果发现堆内存容不下H对象的时候,会触发一次GC操作
-
跨代引用
在进行Young GC的时候,Young区的对象可能还存在Old区的引用, 这就是跨代引用的问题。为了解决Young GC的时候,扫描整个老年代,G1引入了Card Table 和Remember Set的概念,基本思想就是用空间换时间,这两个数据结构是专门用来处理Old区到Young区的引用。Young区到Old区的引用则不需要单独处理,因为Young区中的对象本身变化比较大,没必要浪费空间去记录下来
-
- RSet:全称Remembered Sets, 用来记录外部指向本Region的所有引用,每个Region维护一个RSet
- Card: JVM将内存划分成了固定大小的Card。这里可以类比物理内存上page的概念

如图,每个
Region被分成了多个Card,其中绿色部分的Card表示该Card中有对象引用了其他Card中的对象,这种引用关系用蓝色实线表示。RSet其实是一个HashTable,Key是Region的起始地址,Value是Card Table (字节数组),字节数组下标表示Card的空间地址,当该地址空间被引用的时候会被标记为dirty_cardG1的GC模式
Young GC
Young GC 回收的是所有年轻代的Region。当E区不能再分配新的对象时就会触发。E区的对象会移动到S区,当S区空间不够的时候,E区的对象会直接晋升到O区,同时S区的数据移动到新的S区,如果S区的部分对象到达一定年龄,会晋升到O区

(Young GC 示意)
Mixed GC
回收部分老年代是参数
-XX:MaxGCPauseMillis,用来指定一个G1收集过程目标停顿时间,默认值200ms,当然这只是一个期望值。G1的强大之处在于他有一个停顿预测模型(Pause Prediction Model),他会有选择的挑选部分Region,去尽量满足停顿时间。Mixed GC的触发也是由一些参数控制,比如XX:InitiatingHeapOccupancyPercent表示老年代占整个堆大小的百分比,默认值是45%,达到该阈值就会触发一次Mixed GCMixed GC主要可以分为两个阶段:
1、全局并发标记(global concurrent marking)
- 初始标记(initial mark,STW)。它标记了从GC Root开始直接可达的对象。初始标记阶段借用young GC的暂停,因而没有额外的、单独的暂停阶段
- 并发标记(Concurrent Marking)。这个阶段从GC Root开始对heap中的对象标记,标记线程与应用程序线程并行执行,并且收集各个Region的存活对象信息。过程中还会扫描上文中提到的SATB write barrier所记录下的引用
- 最终标记(Remark,STW)。标记那些在并发标记阶段发生变化的对象,将被回收
- 清除垃圾(Cleanup,部分STW)。这个阶段如果发现完全没有活对象的region就会将其整体回收到可分配region列表中。 清除空Region
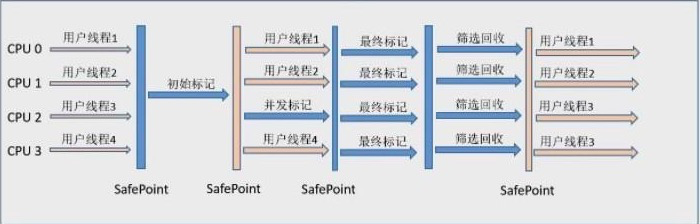
(Mixed GC 全局并发标记过程)
2、拷贝存活对象(Evacuation)
Evacuation阶段是全暂停的。它负责把一部分region里的活对象拷贝到空region里去(并行拷贝),然后回收原本的region的空间。Evacuation阶段可以自由选择任意多个region来独立收集构成收集集合(collection set,简称CSet),CSet集合中Region的选定依赖于上文中提到的停顿预测模型,该阶段并不evacuate所有有活对象的region,只选择收益高的少量region来evacuate,这种暂停的开销就可以(在一定范围内)可控

(Mixed GC 示意)
Full GC
G1的垃圾回收过程是和应用程序并发执行的,当Mixed GC的速度赶不上应用程序申请内存的速度的时候,Mixed G1就会降级到Full GC,使用的是Serial GC。Full GC会导致长时间的STW,应该要尽量避免。
导致G1 Full GC的原因可能有两个:
-
-
- Evacuation的时候没有足够的to-space来存放晋升的对象
- 并发处理过程完成之前空间耗尽
-