Github项目地址 :https://github.com/1195653643
PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 40 |
| Development | 开发 | 900 | 670 |
| · Analysis | · 需求分析 (包括学习新技术) | 200 | 150 |
| · Design Spec | · 生成设计文档 | 40 | 20 |
| · Design Review | · 设计复审 | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 400 | 420 |
| · Code Review | · 代码复审 | 100 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 120 |
| Reporting | 报告 | 150 | 150 |
| · Test Repor | · 测试报告 | 60 | 20 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 100 |
| 合计 | 1110 | 980 |
环境
- 操作系统 :Windows 10
- IDE : Visual Studio Community 2017
- 开发语言 :C++
解题思路
说起来有意思,还没开始做题,就能听到各种同学对题目的讨论。题目是关于文本词频的统计,最早听到他们用有穷自动机来实现,还觉得奇怪,这玩意不是遍历就好了吗?记得以前看Python的时候,好像有一个简单的函数,就可以实现相关的操作。认真看完题目后发现:第一,语言只能用JAVA或C++;第二,对单词的判断,并不像我想的那么简单,结合题目所给的要求,正则表达式的确是很好的选择。题目关于单词的定义,用正则表达式写出就是:
abcd(E*);
这里的a,b,c,d是字母表中任取的元素,E是字母表或数字集合的并集。
用有穷自动机画出来就是:
其中,4为终结状态,e表示E中任取的元素。(依稀能看到柯逍老师说这图太low的表情)
代码实现也很简单,用flag来表示状态,当flag为4时表示出现一个合法的单词,单词数加一。在写代码的过程中,看了很多同学的博客,也询问了结队队友杨喜源同学,因为喜源同学的博客还没写好,这里先不给出网址。
关键代码
判别单词及统计单词频率(模拟有穷自动机)
while((ch = fgetc(file)) != EOF)
{
if ('A' <= ch && ch <= 'Z')
ch = ch + 32;
switch (flag) {
case 0:
if (ch >= 'a'&&ch <= 'z') { flag++; }
break;
case 1:
if (ch >= 'a'&&ch <= 'z') { flag++; }
else { flag = 0; }
break;
case 2:
if (ch >= 'a'&&ch <= 'z') { flag++; }
else { flag = 0; }
break;
case 3:
if (ch >= 'a'&&ch <= 'z') { flag++; }
else { flag = 0; }
break;
case 4:
if (ch >= 'a'&&ch <= 'z' || (ch >= '0'&&ch <= '9')) { }
else
{
flag = 0;
count++;
}
break;
}
} /*flag */
if (flag == 4)
{
count++;
}
性能分析
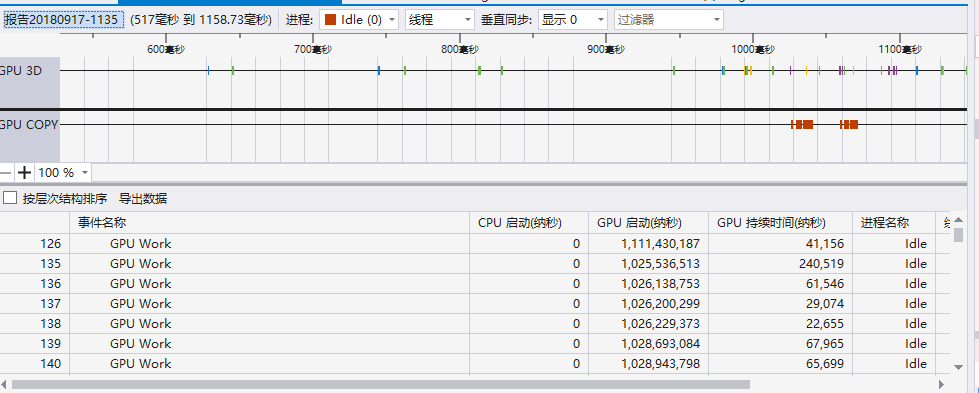
计算模块部分异常处理说明
/*当要输入的文件不存在时*/
FILE *fp;
fp = fopen(filename,"rt");
if(fp==NULL)
{
printf("The file is wrong.
");
}
整体运行结果
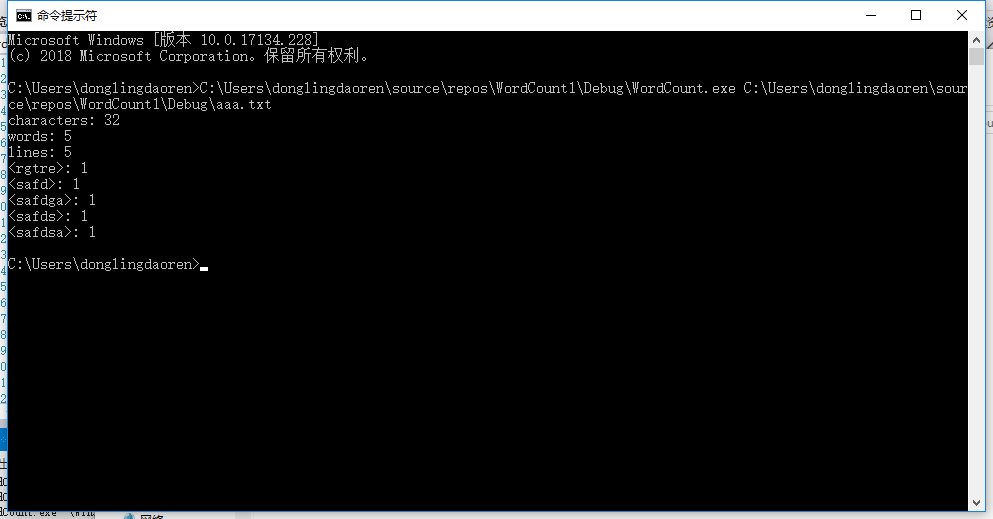
总结和感想
- 在碰到一个新问题的时候,焦虑和烦躁不能解决任何事情。静下心来,定一份合理的计划,循序地去学习新知识,最后完成任务的那一刻,你会很有成就感,发现自己学到很多。
- 计划与实践不能一概而论,但可以作为一个很好的参照。这次作业,原先制定的计划与最后实际完成的结果有许多差别。照本宣科,是不可能很好地完成任务的。
- 要熟练地运用搜索引擎,这次询问同学得到的最多的答复就是:百度啊。许多知识在互联网上都能寻找到,而查阅资料和学习新事物的本领对我们来说是必不可少的。要养成每天学习新东西的习惯。
- 做事情,不能畏惧困难,在得到比失去更多的情况下,完全可以迎难而上。
附录
刚刚发现我没有git push,只是git add,因此代码没有上传到仓库里面。
git push密码输错,现在,,,
把代码黏贴到这,证明赶过作业。
include "CharCount.h"
include<fstream>
include<iostream>
int CharCount(char * filename)
{
int num = 0;
char c;
FILE *file;
fopen_s(&file,filename, "rt");
while (fgetc(file) != EOF)
{
num++;
}
fclose(file);
return num;
}
include "LineCount.h"
int LineCount(char * filename)
{
FILE *file;
fopen_s(&file,filename, "rt");
int num = 0;
char c;
int flag = 0;
while((c = fgetc(file)) != EOF)
{
if (!isspace(c))
{
flag = 1;
}
if (flag && c == '
')
{
flag = 0;
num++;
}
}
if (flag == 1)
{
num++;
}
fclose(file);
return num;
}
include"Word_Fre.h"
typedef pair<string, double> PAIR;
struct CmpByValue {
bool operator()(const PAIR& lhs, const PAIR& rhs) {
return lhs.second > rhs.second;
}
};
int Word_Fre(char * filename)
{
map<string, int> Word_Num_map;
char ch;
FILE *file;
fopen_s(&file, filename, "rt");
int flag = 0; // 有穷自动机的判定
string word;
while ((ch = fgetc(file)) != EOF)
{
if ('A' <= ch && ch <= 'Z')
ch = ch + 32;
switch (flag)
{
case 0: if (ch >= 'a'&&ch <= 'z') { flag++; word = word + ch; } break;
case 1:
if (ch >= 'a'&&ch <= 'z') { flag++; word = word + ch; }
else { flag = 0; word = ""; }
break;
case 2:
if (ch >= 'a'&&ch <= 'z') { flag++; word = word + ch; }
else { flag = 0; word = ""; }
break;
case 3:
if (ch >= 'a'&&ch <= 'z') { flag++; word = word + ch; }
else { flag = 0; word = ""; }
break;
case 4:
if (ch >= 'a'&&ch <= 'z' || (ch >= '0'&&ch <= '9')) { word = word + ch; }
else {
Word_Num_map[word]++;
word = "";
flag = 0;
}
break;
}
}
if (flag == 4) {
Word_Num_map[word]++;
}
if (flag == 4) {
Word_Num_map[word]++;
}
vector <PAIR> Word_Num_vec(Word_Num_map.begin(), Word_Num_map.end());
sort(Word_Num_vec.begin(), Word_Num_vec.end(), CmpByValue());
/*
for (int i = 0; i != Word_Num_vec.size(); ++i) {
const char *ss = Word_Num_vec[i].first.c_str();
cout << ss << ":" << Word_Num_vec[i].second << endl;
}
*/
ofstream outfile("result.txt", ios::app);
if (Word_Num_vec.size() < 10)
for (int i = 0; i != Word_Num_vec.size(); ++i)
{
const char *ss = Word_Num_vec[i].first.c_str();
cout << "<" << ss << ">" << ": " << Word_Num_vec[i].second << endl;
outfile << "<" << ss << ">" << ": " << Word_Num_vec[i].second << endl;
}
else
for (int i = 0; i != 10; ++i)
{
const char *ss = Word_Num_vec[i].first.c_str();
cout << "<" << ss << ">" << ": " << Word_Num_vec[i].second << endl;
outfile << "<" << ss << ">" << ": " << Word_Num_vec[i].second << endl;
}
return 0;
}
// WordCount.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
include<string>
include<stdio.h>
include <iostream>
include <fstream>
include "CharCount.h"
include "LineCount.h"
include "Word_Fre.h"
include "WordNum.h"
using namespace std;
//int argc, char *argv[]
int main(int argc, char *argv[])
{
if (argv[1] == NULL)
{
printf("The file is null");
return -1;
}
int Char_Count = CharCount(argv[1]);
int Lines_Count = LineCount(argv[1]);
int Words_Count = WordNum(argv[1]);
ofstream outfile("result.txt", ios::out);
printf("characters: %d
", Char_Count);
printf("words: %d
", Words_Count);
printf("lines: %d
", Lines_Count);
outfile << "characters: " << Char_Count << endl;
outfile << "words: " << Words_Count << endl;
outfile << "lines: " << Lines_Count << endl;
Word_Fre(argv[1]);
return 0;
}
include"WordNum.h"
int WordNum(char * filename)
{
map<string, int> Word_Num_map;
char ch;
FILE *file;
fopen_s(&file, filename, "rt");
int flag = 0; // 有穷自动机的五个状态是 0 1 2 3 4,其中4是终结状态,0为初始状态
int count = 0;
while((ch = fgetc(file)) != EOF)
{
if ('A' <= ch && ch <= 'Z')
ch = ch + 32;
switch (flag) {
case 0:
if (ch >= 'a'&&ch <= 'z') { flag++; }
break;
case 1:
if (ch >= 'a'&&ch <= 'z') { flag++; }
else { flag = 0; }
break;
case 2:
if (ch >= 'a'&&ch <= 'z') { flag++; }
else { flag = 0; }
break;
case 3:
if (ch >= 'a'&&ch <= 'z') { flag++; }
else { flag = 0; }
break;
case 4:
if (ch >= 'a'&&ch <= 'z' || (ch >= '0'&&ch <= '9')) { }
else
{
flag = 0;
count++;
}
break;
}
} /*flag */
if (flag == 4)
{
count++;
}
return count;
}
// pch.cpp: 与预编译标头对应的源文件;编译成功所必需的
include "pch.h"
// 一般情况下,忽略此文件,但如果你使用的是预编译标头,请保留它。