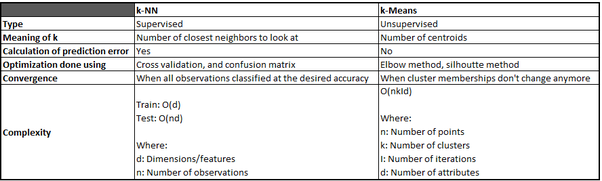
1. The difference between classification and clustering. from here.
Classification: supervised learning with labels.
Clustering: unsupervised learning without labels.
Classification and Clustering are the two types of learning methods which characterize objects into groups by one or more features. These processes appear to be similar, but there is a difference between them in the context of data mining. The prior difference between classification and clustering is that classification is used in supervised learning technique where predefined labels are assigned to instances by properties, on the contrary, clustering is used in unsupervised learning where similar instances are grouped, based on their features or properties.
2. The difference between k-means and k-NN. from here.
k-means: an unsupervised algorithm used for clustering.
k-NN: a supervised algorithm used for classification.
3. K-NN algorithm
K-nearest neighbours needs labelled data to train on. With the given data, KNN can classify new, unlabelled data by analysis of the k number of the nearest data points.
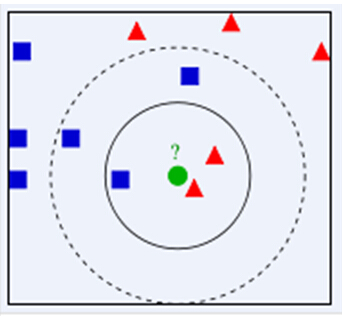
Steps
- 计算测试数据与各个训练数据之间的距离;
-
按照距离的递增关系进行排序;
-
选取距离最小的K个点;
-
确定前K个点所在类别的出现频率;
-
返回前K个点中出现频率最高的类别作为测试数据的预测分类。
影响KNN结果的两个因素: i. k的选取, ii. 距离的测算
- k过小,导致容易受噪声影响,将噪声学习到模型中,而忽略了数据的真实分布. k过大, 模型简化,忽略训练数据中的大量有用信息,导致无法学习. 如果k=N(N为训练样本的个数),那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类。这时,模型是不是非常简单,这相当于你压根就没有训练模型!

4. K-means algorithm
Steps
- Initially, randomly pick k centroids/cluster centers. Try to make them near the data but different from one another.
- Then assign each data point to the closest centroid.
- Move the centroids to the average location of the data points assigned to it.
- Repeat the preceding two steps until the assignments don’t change, or change very little.
5. How to optimize K in k-means?
SSE + elbow method; silhouette coefficient; Calinski-Harabaz index; 信息准则: AIC-Akaike information criterion; BIC-Bayesian information criterion.
SSE,sum of the squared errors,误差的平方和。在K-means 算法中,SSE 计算的是每类中心点与其同类成员距离的平方和。
 其中, ui 表示第i类的中心点.
其中, ui 表示第i类的中心点.
手肘法的核心思想是:
随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。
当k小于最佳聚类数时,k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大;
当k到达最佳聚类数时,再增加k所得到的聚合程度,回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓。
也就是说SSE和 k 的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的最佳聚类数。这也是该方法被称为手肘法的原因。
from here.
6. how to optimize KNN?
cross-validation;
Supplementary knowledge:
1. cross-validation 交叉验证
from here.
在机器学习里,通常来说我们不能将全部用于数据训练模型,否则我们将没有数据集对该模型进行验证,从而评估我们的模型的预测效果。
交叉验证是在机器学习建立模型和验证模型参数时常用的办法。交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓“交叉”。
根据切分的方法不同,交叉验证分为下面三种:
第一种是简单交叉验证,所谓的简单,是和其他交叉验证方法相对而言的。首先,我们随机的将样本数据分为两部分(比如: 70%的训练集,30%的测试集),然后用训练集来训练模型,在测试集上验证模型及参数。接着,我们再把样本打乱,重新选择训练集和测试集,继续训练数据和检验模型。最后我们选择损失函数评估最优的模型和参数。
第二种是S折交叉验证(S-Folder Cross Validation)。和第一种方法不同,S折交叉验证会把样本数据随机的分成S份,每次随机的选择S-1份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择S-1份来训练数据。若干轮(小于S)之后,选择损失函数评估最优的模型和参数。
第三种是留一交叉验证(Leave-one-out Cross Validation),它是第二种情况的特例,此时S等于样本数N,这样对于N个样本,每次选择N-1个样本来训练数据,留一个样本来验证模型预测的好坏。此方法主要用于样本量非常少的情况,比如对于普通适中问题,N小于50时,我一般采用留一交叉验证。
Reference: