开篇:Hadoop是一个强大的并行软件开发框架,它可以让任务在分布式集群上并行处理,从而提高执行效率。但是,它也有一些缺点,如编码、调试Hadoop程序的难度较大,这样的缺点直接导致开发人员入门门槛高,开发难度大。因此,Hadop的开发者为了降低Hadoop的难度,开发出了Hadoop Eclipse插件,它可以直接嵌入到Hadoop开发环境中,从而实现了开发环境的图形界面化,降低了编程的难度。
一、天降神器插件-Hadoop Eclipse

Hadoop Eclipse是Hadoop开发环境的插件,在安装该插件之前需要首先配置Hadoop的相关信息。用户在创建Hadoop程序时,Eclipse插件会自动导入Hadoop编程接口的jar文件,这样用户就可以在Eclipse插件的图形界面中进行编码、调试和运行Hadop程序,也能通过Eclipse插件查看程序的实时状态、错误信息以及运行结果。除此之外,用户还可以通过Eclipse插件对HDFS进行管理和查看。
总而言之,Hadoop Eclipse插件不仅安装简单,使用起来也很方便。它的功能强大,特别在Hadoop编程方面为开发者降低了很大的难度,是Hadoop入门和开发的好帮手!
二、Hadoop Eclipse的开发配置
2.1 获取Hadoop Eclipse插件
(1)为了方便,我们可以直接百度一下,我这里hadoop版本是1.1.2,因此只需要搜索一下hadoop-eclipse-plugin-1.1.2.jar即可,我们可以从下面的链接中下载该插件。
URL:http://download.csdn.net/download/azx321/7330363
(2)将下载下来的插件jar文件放置到eclipse的plugins目录下,然后重新启动eclipse。
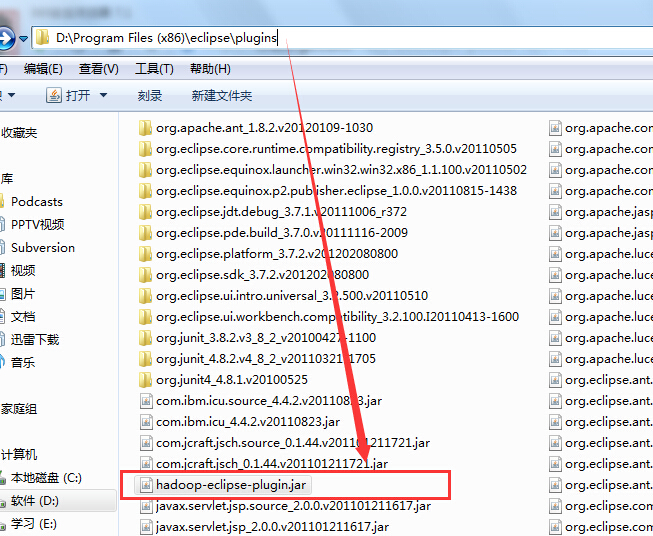
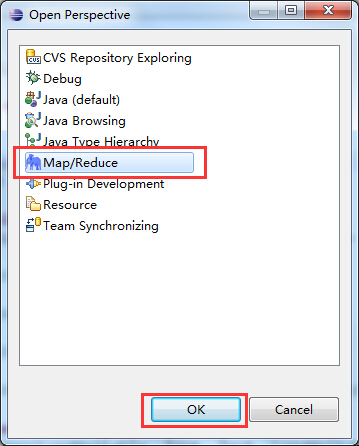
(3)重新启动eclipse之后,单击 按钮,添加hadoop eclipse插件视图按钮:首先选择Other选项,弹出如下图所示的对话框,从中选择Map/Reduce选项,然后单击OK即可。
按钮,添加hadoop eclipse插件视图按钮:首先选择Other选项,弹出如下图所示的对话框,从中选择Map/Reduce选项,然后单击OK即可。
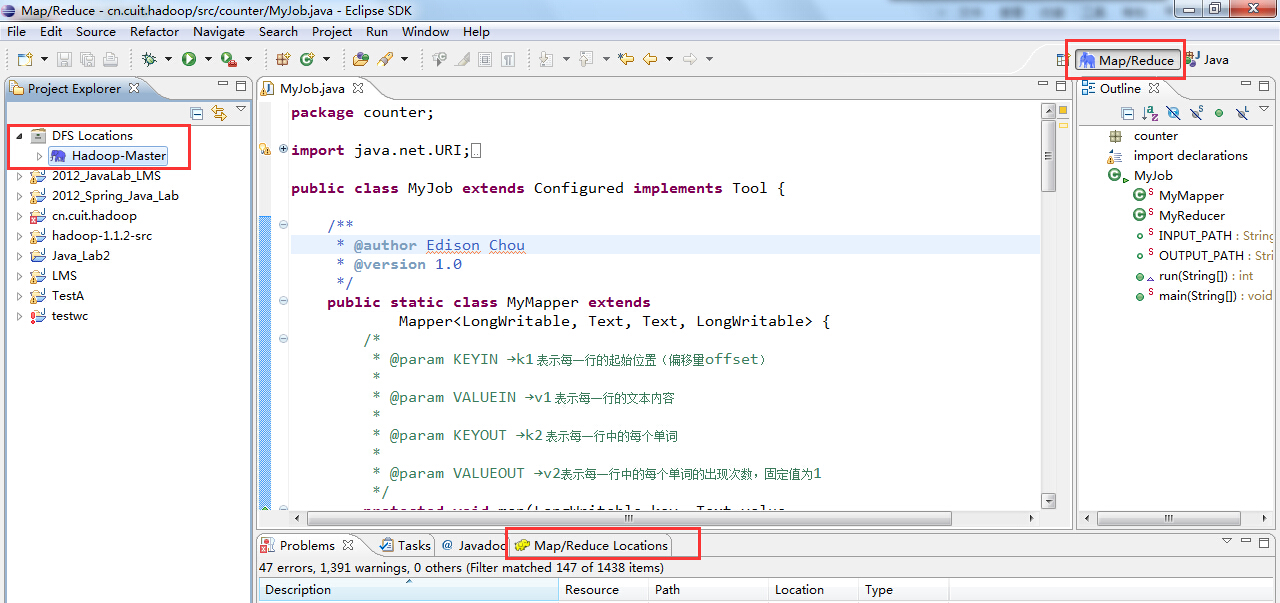
(4)添加完成后,eclipse中就会多出一个Map/Reduce视图按钮,我们可以点击进入Map/Reduce工作目录视图:
2.2 Hadoop Eclipse插件的基本配置
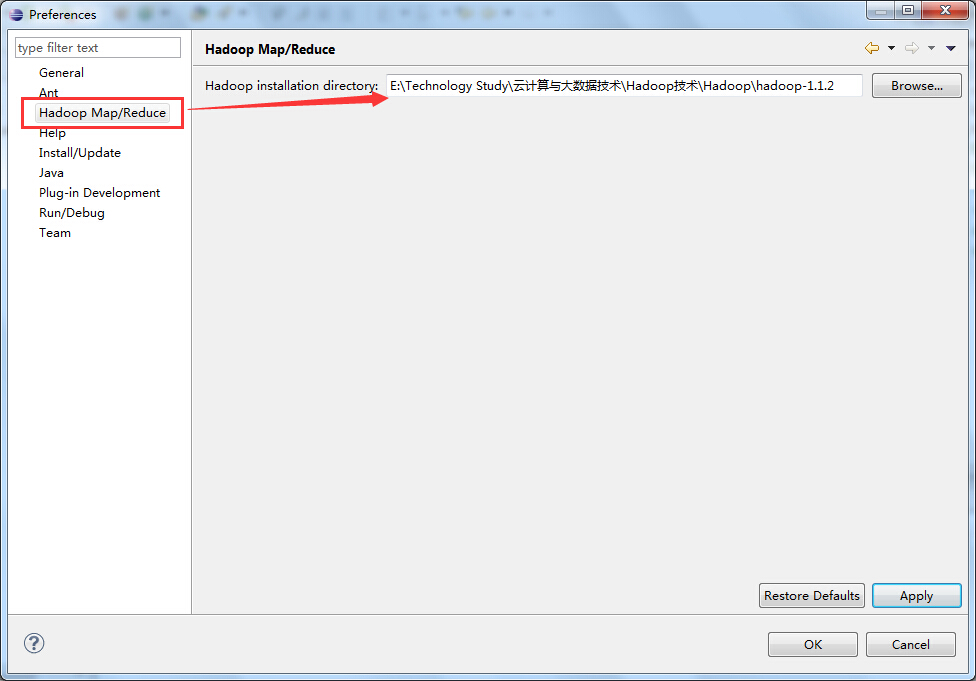
(1)设置Hadoop的安装目录
在eclipse中选择Windows→Preference按钮,弹出一个对话框,在该对话框左侧会多出一个Hadoop Map/Reduce选项,然后单击此选项,在右侧设置Hadoop的安装目录。
(2)设置Hadoop的集群信息
这里需要与Hadoop集群建立连接,在Map/Reduce Locations界面中右击,弹出选项条,选择New Hadoop Location选项;
在弹出的对话框中填写连接hadoop集群的信息,如下图所示:

在上图所示的红色区域是我们需要关注的地方,也是我们需要好好填写的地方。
PS:Location name: 这个随便填写,我填写的是我的Hadoop Master节点的主机名;
Map/Reduce Master 这个框里:
Host:就是jobtracker 所在的集群机器,我这里是192.168.80.100
Hort:就是jobtracker 的port,这里写的是9001(默认的端口号)
这两个参数就是mapred-site.xml里面mapred.job.tracker里面的ip和port;
DFS Master 这个框里:
Host:就是namenode所在的集群机器,我这里由于是伪分布,都在192.168.80.100上面
Port:就是namenode的port,这里写9000(默认的端口号)
这两个参数就是core-site.xml里面fs.default.name里面的ip和port
(Use M/R master host,这个复选框如果选上,就默认和Map/Reduce Master这个框里的host一样,如果不选择,就可以自己定义输入,这里jobtracker 和namenode在一个机器上,所以是一样的,就勾选上)User name:这个是连接hadoop的用户名,我这里是root用户;
接下来,单击Advanced parameters选项卡中的hadoop.tmp.dir选项,修改为你的Hadoop集群中设置的地址,我这里Hadoop集群中设置的地址是/usr/local/hadoop/tmp,然后单击Finish按钮(这个参数在core-site.xml中进行了配置)

PS:Advanced parameters选项卡中大部分的属性都已经自动填写上了,其实就是把那几个核心xml配置文件里面的一些配置属性展示出来。
刚刚的配置完成后,返回eclipse中,我们可以看到在Map/Reduce Locations下面就会多出来一个Hadoop-Master的连接项,这就是刚刚建立的名为Hadoop-Master的Map/Reduce Location连接,如下图所示:

2.3 查看HDFS
(1)通过选择eclipse左侧的DFS Locations下面的Hadoop-Master选项,就会展示出HDFS中的文件结构;
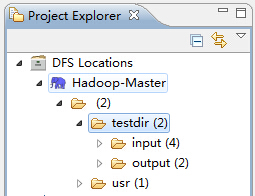
(2)这里在testdir文件夹处右击选择一个指定的文件,如下图所示:
三、在Eclipse下运行WordCount程序
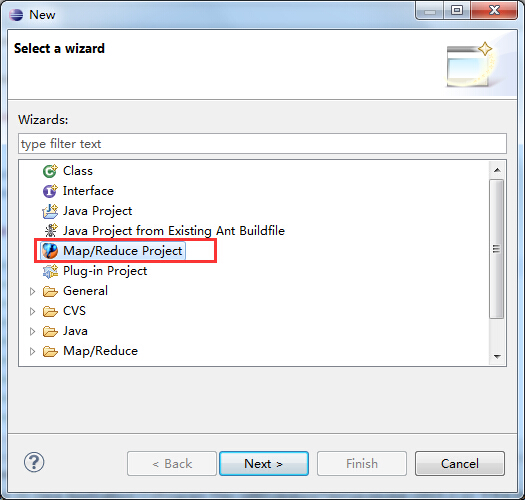
3.1 创建Map/Reduce项目
选择File→Other命令,找到Map/Reduce Project,然后选择它,如下所示:
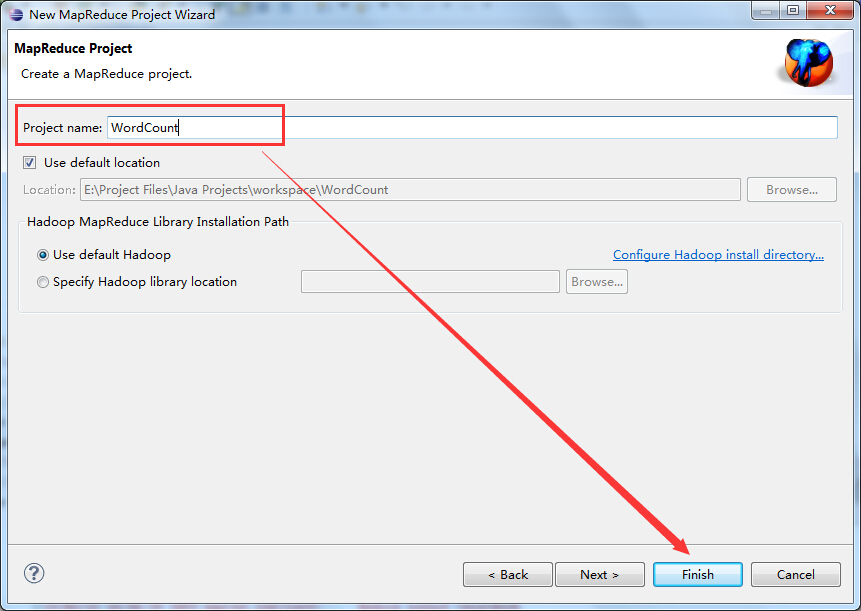
输入Map/Reduce工程的名称,这里取为:WordCount,单击Finish按钮完成,如下图所示:
3.2 创建WordCount类
这里新建一个WordCount类,输入以下代码:


public class WordCount extends Configured implements Tool { /** * @author Edison Chou * @version 1.0 */ public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { /* * @param KEYIN →k1 表示每一行的起始位置(偏移量offset) * * @param VALUEIN →v1 表示每一行的文本内容 * * @param KEYOUT →k2 表示每一行中的每个单词 * * @param VALUEOUT →v2表示每一行中的每个单词的出现次数,固定值为1 */ protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws java.io.IOException, InterruptedException { Counter sensitiveCounter = context.getCounter("Sensitive Words:", "Hello"); String line = value.toString(); // 这里假定Hello是一个敏感词 if(line.contains("Hello")){ sensitiveCounter.increment(1L); } String[] spilted = line.split(" "); for (String word : spilted) { context.write(new Text(word), new LongWritable(1L)); } }; } /** * @author Edison Chou * @version 1.0 */ public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { /* * @param KEYIN →k2 表示每一行中的每个单词 * * @param VALUEIN →v2 表示每一行中的每个单词的出现次数,固定值为1 * * @param KEYOUT →k3表示每一行中的每个单词 * * @param VALUEOUT →v3 表示每一行中的每个单词的出现次数之和 */ protected void reduce(Text key, java.lang.Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws java.io.IOException, InterruptedException { long count = 0L; for (LongWritable value : values) { count += value.get(); } context.write(key, new LongWritable(count)); }; } // 输入文件路径 public static String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/words.txt"; // 输出文件路径 public static String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/wordcount"; @Override public int run(String[] args) throws Exception { // 首先删除输出路径的已有生成文件 FileSystem fs = FileSystem.get(new URI(INPUT_PATH), getConf()); Path outPath = new Path(OUTPUT_PATH); if (fs.exists(outPath)) { fs.delete(outPath, true); } Job job = new Job(getConf(), "WordCount"); // 设置输入目录 FileInputFormat.setInputPaths(job, new Path(INPUT_PATH)); // 设置自定义Mapper job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); // 设置自定义Reducer job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // 设置输出目录 FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); System.exit(job.waitForCompletion(true) ? 0 : 1); return 0; } public static void main(String[] args) { Configuration conf = new Configuration(); try { int res = ToolRunner.run(conf, new WordCount(), args); System.exit(res); } catch (Exception e) { e.printStackTrace(); } } }
3.3 运行WordCount程序
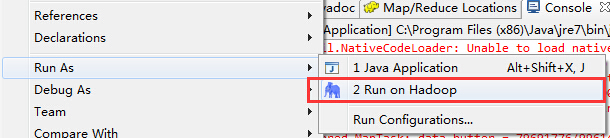
选择WordCount并右击,选择Run on Hadoop方式运行,如下图所示:
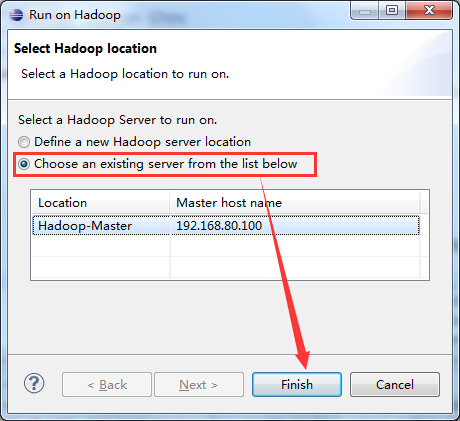
运行结果如下图所示:

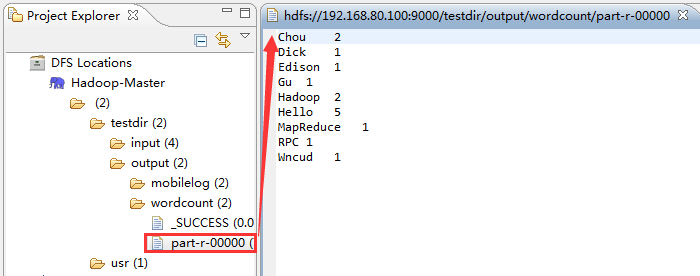
3.4 查看HDFS中的运行结果
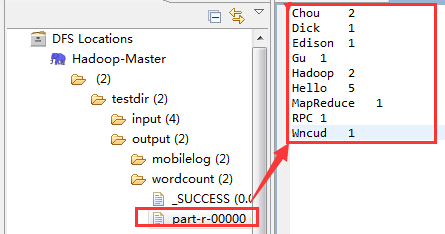
打开设定的输出文件夹output下的part-r-00000文件,就是WordCount程序的执行结果,如下图所示:
参考资料
(1)万川梅、谢正兰,《Hadoop应用开发实战详解(修订版)》:http://item.jd.com/11508248.html
(2)cybercode,《eclipse hadoop开发环境配置》:http://blog.csdn.net/cybercode/article/details/7084603