28. 实现 strStr()
实现 strStr() 函数。
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1:
输入: haystack = "hello", needle = "ll"
输出: 2
示例 2:
输入: haystack = "aaaaa", needle = "bba"
输出: -1
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
KMP
设str=haystack, pat=needle。
这道题一开始我是奔着KMP算法去了,因为很明显的字符串匹配问题嘛,参照KMP 算法详解这片博文,用C++实现了一次KMP算法。主要要点是,主串的指针i不回退,根据模式pat计算状态转移矩阵next(状态就是指当前匹配了pat里的几个字符了,转移动作是指当前主串中要遍历到的字符),遍历主串时,根据这个状态转移矩阵转移状态,直到转移到最后一个状态则匹配成功,否则匹配失败。难点就在于这个next矩阵是怎么得到的。
加入pat字符串的长度为M,里面的字符有N个,则状态范围是[0, M], 转移操作的范围是那N个字符加上一个"other", next的维度是(M+1,N+1)。在构造next矩阵时,遇到的转移操作正好时pat的下一个字符时,很简单next相应位置为下一个状态即可。例如:
pat = ABABC
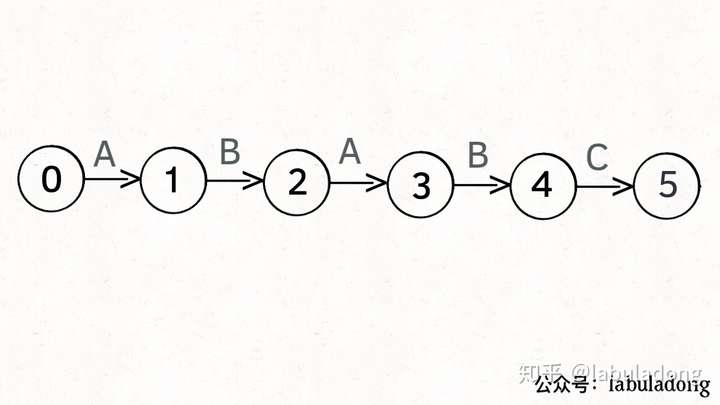
状态0遇到A字符直接跳转到状态1即可,遇到其他字符还是状态0.
那状态4遇到A要怎么办呢,可以跳到状态3,因为遇到A后,当前最后匹配的ABA和前缀ABA匹配,所以跳到状态3最省时间。那为啥跳状态3,代码里是怎么知道要跳这里的。那片博文介绍使用影子状态来记录这个位置,影子状态和当前状态有相同的前缀(应该是慢一步的相同前缀,因为如果说是相同前缀,那影子状态应该就是当前状态了)。
首先初始化next矩阵为:
| x=0 | A | B | C | other |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 |
影子状态x初始为0,构造next矩阵从状态1开始,如果遇到字符char为pat[当前状态1],则next[当前状态1] [char] = 下一个状态2。否则状态更新为影子状态遇到char后的状态。
在每次更新完一个状态的next矩阵后,需要对影子状态进行更新,更新公式为x = next[x] [pat[当前状态]],即当影子状态和当前状态下的字符一样时,影子状态才向前更新(在实际手动计算一次next矩阵后才更好理解)。这样由于当前状态是从1开始,所以影子状态永远比当前状态慢一步。更新完状态1后的next矩阵为:
| x=0 | A | B | C | other |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 |
| 1 | 1 | 2 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 |
接下来更新状态2:
| x=1 | A | B | C | other |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 |
| 1 | 1 | 2 | 0 | 0 |
| 2 | 3 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 |
此时隐藏状态x有了变化,因为状态2的pat字符A和隐藏状态x的pat字符A一样,所以x = next[x] [pat[当前状态2]] = next[0] [A] =1。
更新状态3:
| x=2 | A | B | C | other |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 |
| 1 | 1 | 2 | 0 | 0 |
| 2 | 3 | 0 | 0 | 0 |
| 3 | 1 | 4 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 |
隐藏状态x依然有了变化,因为pat[3] = B, next[1] [B] = 2, 所以x=2. 之后更新状态4:
| x=2 | A | B | C | other |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 |
| 1 | 1 | 2 | 0 | 0 |
| 2 | 3 | 0 | 0 | 0 |
| 3 | 1 | 4 | 0 | 0 |
| 4 | 3 | 0 | 5 | 0 |
| 5 | 0 | 0 | 0 | 0 |
完成了next矩阵构造,之后就可以拿这个矩阵去匹配字符串了。
注:在写C++源码时,可以用vector<map<string, int>>来表示这个二维矩阵。从char转换为string时需要利用(n, val)的初始化方式,即 char c; string cc(1, c);。
class Solution {
public:
int strStr(string haystack, string needle) {
string &str = haystack;
string &pat = needle;
if (pat.size() == 0) {
return 0; // 空模式,返回0.
}
// pat出现的所有字符,因为要包含'other'所以需要是string类型
set<string> pat_char;
for (char c : pat) {
string cc(1, c);
pat_char.insert(cc);
}
pat_char.insert("other");
// 构造next表
vector<map<string, int>> next = this->construct_next(pat, pat_char);
// 根据next表匹配
int state = 0;
for (int i = 0; i < str.size(); ++i) {
string cc(1, str[i]);
if (pat_char.find(cc) == pat_char.end()) {
cc = "other";
}
state = next[state][cc];
if (state == pat.size()) {
return i - pat.size() + 1;
}
}
return -1;
}
vector<map<string, int>> construct_next(string& pat, set<string> &pat_char) {
vector<map<string, int>> next(pat.size() + 1);
// 初始化都是0,0状态pat[0]处状态转移为1.
for (int s = 0; s <= pat.size(); ++s) {
for (string cc : pat_char) {
next[s][cc] = 0;
}
}
string cc0(1, pat[0]);
next[0][cc0] = 1;
int x = 0; // 影子状态
for (int s = 1; s < pat.size(); ++s) {
string current_char(1, pat[s]);
for (string cc : pat_char) {
if (cc == current_char) {
next[s][cc] = s + 1;
} else {
next[s][cc] = next[x][cc];
}
}
// 更新影子状态
x = next[x][current_char];
}
return next;
}
};
带预处理的暴力求解BS
使用KMP提交后,发现并没有那么好的效果,翻题解后发现只用暴力求解就可以很快了,因为KMP需要构造next矩阵,如果面对比较小型的字符串可能效果还不如暴力求解,当然暴力求解也要考虑先排除一些情况才会很快:
- pat为空时返回0.
- str为空时返回-1.
- pat长度小于str时返回-1.
最终代码如下:
class Solution {
public:
int strStr(string haystack, string needle) {
if (needle == "") return 0;
if (haystack == "") return -1;
int l1 = haystack.size(); // size方法返回一个unsigned的数值,所以直接相减会返回一个很大的数。
int l2 = needle.size();
for (int i = 0; i <= l1 - l2; ++i) {
int j = 0;
if (haystack[i] == needle[j]) {
while (j < needle.size()) {
if (haystack[i + j] != needle[j]) {
j = 0;
break;
} else {
++j;
}
}
if (j == needle.size()) {
return i;
} else {
;
}
}
}
return -1;
}
};
两者的通过情况对比:
KMP: 
BS:
看来这道题的测试样例没有特别大特别复杂的测试样例,特别大的测试样例都可以被BS的预处理部分很快的处理掉。