▲一些疑惑和查阅资料后的认识总结:
1、堆和栈中分别存储的是什么类型数据?
- 栈:(不用我们维护,函数调用结束自动清理栈内存):内部存储值类型数据、引用地址
- 堆:全局就一个堆,空间有限,所以才需要垃圾回收:引用类型数据、引用地址
2、为什么需要堆内存和栈内存,全部使用堆不行吗?
全部使用堆会造成极低的效率。
3、声明在函数中的引用变量 在堆还是栈?
引用类型对象任何时候都在堆里。
4、值类型对象都在栈内存吗?
值类型也有可能分配在托管堆上:
- 类上的字段
- 捕获的变量
- 迭代器块中的变量
- 闭包情况下匿名函数(lamda)中的局部变量。
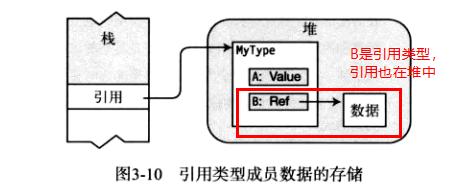
5、引用类型对象中的值类型成员 在堆还是栈?
引用类型对象整个都在堆中,所以其中的值类型字段也在堆中
6、数组元素 在堆还是栈?
数组元素值存储的都是引用【不管值类型还是引用类型】
数组元素是值类型:值存储在栈中,
引用类型:值存储在堆中
7、赋值时 如何内存分配?
对于值类型(pointStruct1),会在栈上开辟一块新的空间,将数据完全复制过去,因此pointStruct2和pointStruct1是互相独立的,对其中一个的修改不会影响到另一个;
对于引用类型(pointClass1),也会在栈上开辟一个新的空间,将栈上的数据(指向堆上实例的指针)复制到新的空间, 但是注意,此处复制的是指针,也就是说栈上的两个变量pointClass1和pointClass2虽然是不同的空间,但是它们的存储内容---指针(内存地址), 都是指向堆上的同一实例
值类型赋值给引用类型【装箱】:会在堆上开辟一块新空间,将值类型数据复制到堆中,引用类型变量存放指针(栈中)。
引用类型赋值给值类型【拆箱】:
归根结底,这些赋值转换,装箱拆箱,还是继承关系间对象的转换,不存在继承关系,转换就不可能实现。
参数传递——实参赋值给形参
当程序中进行参数传递的时候,也是默认按值传递,值类型复制数据本身,形成独立的数据块,引用类型复制引用,指向同一实例。简单一点就是传递时复制栈上的数据到新的栈上空间。
8、引用变量声明而未赋值 如何内存分配?
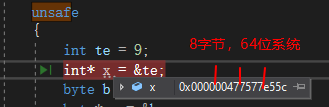
当你申明变量的时候就会为它在内存中分配内存空间8个字节(64bits系统)【用来存储堆内存地址】,引用类型必须初始化【C#8 之前如果使用未赋值的变量vs中就会编译报错,C#8 引入了可为空引用类型才可以不赋值,例如 string? name;】
当创建一个空类对象,共需要分配多大内存呢?
当前的GC实现对于一个空类来说,需要至少12个字节的对象实例。如果一个类没有定义任何实例字段,它将产生4个或8个字节的开销(用于分配到栈上来对他进行引用)。其余部分(8个字节)的将由同步块索引和类型对象指针占用。
一个对象在堆中有一块区域存储它内部的字段和成员以及两个额外成员(类型对象指针【指向的是System.Type的对象地址】、 同步块索引 ,初始时被赋值为-1。)
所以对于一个空引用类型来说,他所占用的空间大小就是`12`【12字节】。
指针所占内存和操作系统有关
9、引用类型数据的引用部分可以存储在堆也可以在栈,取决于实际环境。
见问题4。
10、堆的内存如何动态分配
实际上很多应用中,堆的分配算法往往是采取多种算法复合而成的,对于glibc来说,小于64字节的采用对象池的方法,对于大于512字节的采用最佳适配算法,对于64字节和512字节之间的采取最佳折中策略;对于大于128kb的申请,它会直接使用mmap向操作系统申请空间。
11、结构为什么不能继承类?
所有的结构都默认继承了该类ValueType,对的,是一个类,也就是说所有的结构都是有继承的,继承了ValueType,也是因为这样,所以结构不能再继承类了,只能继承接口,因为C#是单继承的。
12、为什么要装箱拆箱?
- 装箱与拆箱是我们能够统一的来考察类型系统,其中任何类型的值都可以按对象处理。
- 需要使用基类的方法时,要装箱。
- 要将值类型数据加入非泛型容器时,需要装箱。
13、如何避免值类型装箱?
首先什么时候会装箱
(1)调用一个形参为object的方法,而传入的实参为值类型时,需要装箱。
可通过重载函数避免
(2)另一个用法,非泛型容器,里边元素类型为object。
可通过使用泛型容器避免。
(3)调用基类方法,a.ToString()、GetType()。
a.ToString()编译器发现A重写了ToString方法,会直接调用ToString的指令。因为A是值类型,编译器不会出现多态行为。因此,直接调用,不装箱。(注:ToString是A的基类System.ValueType的方法) 。此处重写基类方法避免
当你调用值类型变量的GetType()方法时总是伴随着装箱过程,因为它不能被重载(非虚方法不能override)。(补一句,所有的值类型都是继承于System.ValueType的)。 可通过调用typeof() 运算符避免装箱。
将值类型转化为接口类型时也会进行装箱操作,这是因为接口类型必须包含对堆上的一个对象的引用。
(4)自定义strut结构值类型,避免装箱拆箱
所以C# 自定义结构:需要重写某些基类方法避免。
区别对待override和new:在下一篇中有详细分析
- 只有类中有虚方法重写override,才会表现出运行时类型方法特征。其他无论是不是虚方法,是不是有new 修饰,都表现出编译时类型方法特征【即声明的类型是什么就调用什么方法】。
14、值类型 strut 内存怎么分配的?
然而在.net托管环境中,CLR提供了更自由的方式来控制struct中Layout:我们可以在定义struct时,在struct上运用StructLayoutAttribute特性来控制成员的内存布局。默认情况下,struct实例中的字段在栈上的布局(Layout)顺序与声明中的顺序相同
a.[StructLayout(LayoutKind.Sequential)]
struct StructDeft//C#编译器会自动在上面运用[StructLayout(LayoutKind.Sequential)] { bool i; //1Byte double c;//8byte bool b; //1byte }
b.[StructLayout(LayoutKind.Explicit)]
[StructLayout(LayoutKind.Explicit)] struct BadStruct { [FieldOffset(0)] public bool i; //1Byte [FieldOffset(0)] public double c;//8byte [FieldOffset(0)] public bool b; //1byte }
sizeof(BadStruct)得到的结果是9byte,显然得出的基数9显示CLR并没对结构体进行任何内存对齐(Align);本身要占有10byte的数据却只占了9byte,显然有些数据被丢失了,这也正是我给struct取BadStruct作为名字的原因。如果在struct上运用了[StructLayout(LayoutKind.Explicit)],计算FieldOffset一定要小心
c.[StructLayout(LayoutKind.Auto)]
sizeof(StructAuto)得到的结果是12byte。下面来测试下这StructAuto的三个字段是如何摆放的:
unsafe { StructAuto s = new StructAuto(); Console.WriteLine(string.Format("i:{0}", (int)&(s.i))); Console.WriteLine(string.Format("c:{0}", (int)&(s.c))); Console.WriteLine(string.Format("b:{0}", (int)&(s.b))); } // 测试结果: i:1242180 c:1242172 b:1242181
即CLR会对结构体中的字段顺序进行调整,将i调到c之后,使得StructAuto的实例s占有尽可能少的内存,并进行4byte的内存对齐(Align),
结论:
默认(LayoutKind.Sequential)情况下,CLR对struct的Layout的处理方法与C/C++中默认的处理方式相同,即按照结构中占用空间最大的成员进行对齐(Align);
使用LayoutKind.Explicit的情况下,CLR不对结构体进行任何内存对齐(Align),而且我们要小心就是FieldOffset;
使用LayoutKind.Auto的情况下,CLR会对结构体中的字段顺序进行调整,使实例占有尽可能少的内存,并进行4byte的内存对齐(Align)。
15、数据是如何从程序到内存中的?
- 所有数据都是值类型【基本类型+结构类型 如DateTime】实例保存的数据。但在内存中位置不一样,
- 纯基本类型对象保存在栈中,内存分配效率高
- 不纯的基本类型【引用类实例中值类型成员,数组值类型元素(元素都是引用,元素值在堆或栈中)】,内存分配效率低
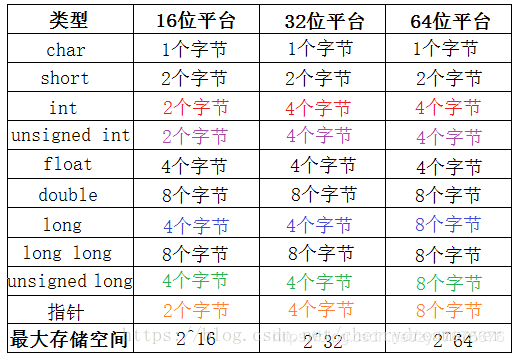
- 数据最终都是由纯基本类型组成的【或字符串这个特殊的引用类型,编码不同占用字节数不同】,纯基本类型又是由一个一个字节组成的【int占32位4个字节,byte8位占一个字节,short16位2个字节,long64位8字节。】。都是可以预知内存大小的。
- 计算机中有个存储数据的叫储存器(分为 ram 和 rom), 首先是储存在 内存中(也就是ram 随机存储器,与cpu 直接交互的,其内部有好多的元器件进行存储,这个元器件就有两种状态0或1也就是有电,没电(多好要么有要么没),虽然一个元器件只有两种状态,但是多个组合就很大了,突然一组合就有了 Bit,Byte,KB,MB,GB,TB,PB,EB 的概念了 那么元器件也就有了另一个名字 比特(bit)或位,),在内存中数据有不同的类型,而不同类型数据占用的字节数不一样【相同类型的不同数据根据编码规则分别由 一些字节(单字节或多字节)唯一表示】,如 int 占4个字节,byte 占1 个字节,字符根据编码不同占用字节数也不同,一个汉字Unicode编码为两个字节,UTF8编码为三个字节,为了正确访问这些存储的数据,必须给每个字节都编上号码,每个编号都是惟一的,根据编号就能准确找到某个字节,而在内存中字节的编号又被称为地址(Address)或指针(Pointer)。