
论文源址:https://arxiv.org/pdf/1703.06870.pdf
开源代码:https://github.com/matterport/Mask_RCNN
摘要
Mask R-CNN可以在进行检测的同时,进行高质量的分割操作。基于Faster R-CNN并进行扩展,增加了一个分支在进行框识别的同时并行的预测目标的mask。Mask R-CNN易于训练,相比Faster R-CNN增加了一点点花销。此外,Mask R-CNN可以很容易扩展至其他任务中。如关键点检测。本文在COCO数据集中的三个任务效果表现优异,包含实例分割,边界框的目标检测及关键点检测。
介绍
本文的目标在于建造一个有效进行实例分割的系统。实例分割由于需要对图片中的所有目标进行正确的检测及分割,具有一定的挑战性。 因此,本文结合目标检测及分割两种计算机视觉任务。目标检测的目标是对单独的object进行分类。同时,使用框对每个位置进行定位操作。 分割是不管不同的实例目标对每个像素进行分类。
Mask R-CNN扩展Faster R-CNN通过增加一个分支用于预测每个RoI的分割masks.同时,利用现有的分支进行分类及框回归任务。如下图,mask分支是一个小型的FCN应用到每个RoI上,以像素级的方式进行分割预测。

Mask R-CNN基于Faster R-CNN训练更快,同时,可以扩展结构设计用于其他任务。Faster R-CNN中网络的输入与输出并未满足像素级别的对齐。这是因为RoiPool在特征提取过程中进行粗糙的空间量化操作效果明显。为了解决不匹配的情况,本文提出了一个简单的去量化层RoIAlign,可以准确的保存空间位置。设计上进行了一点改造,RoIAlign发挥重大作用:将mask的准确率相对提升了10%至50%。另外,本文发现同时进行mask与分类十分重要。针对每个类别进行二分类。同时,依赖于网络的RoI分类分支进行类别预测。相反,通常对每个像素进行多分类操作。Mask R-CNN重点在于实例级别的分析。
Mask R-CNN
Faster R-CNN中每个候选目标有两个输出,一个为类别,另一个为边界框的偏移。Mask R-CNN增加了一个分支用于输出目标的mask。Mask 输出与分类及框预测输出是独立的,mask需要提取大量目标的合适形状信息。
Faster R-CNN
主要包含两部分,(1)Region Proposal Network(RPN)用于提取候选目标框。(2)此部分本质上为Fast R-CNN,对每个候选框利用RoIPool提取特征,接着执行分类及框回归操作。 提取的特征被共享便于更快的推理。
Mask R-CNN
Mask R-CNN同样采用两阶段处理过程。第一阶段的操作相同,为RPN,在第二阶段,并行的进行分类及框偏移预测。Mask R-CNN同时针对每个RoI输出一个二分类的mask。参考Fast R-CNN同时进行边界框的分类及回归。大大简化了R-CNN的多阶段过程。
正常情况下,训练时,针对每个RoI样本定义一个多任务的损失: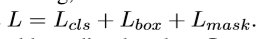 分类损失与边界框损失与Fast R-CNN相似。mask 分支中,针对么个RoI,包含Km^2维度的输出。用于编码K个二分类的mask,大小为mxm,针对K个类别。因此,我们应用一个像素级的sigmoid。定义Lmask为平均二分类交叉熵损失函数。与类别K相对应的ground truth,Lmaks只定义第k个mask。其他mask的输出对此loss损失无影响。Lmask的定义允许网络生成每个类别的masks,与其他类别无关。依赖于分类分支,用于预测输出mask的标签。这里,包含mask及类别的预测。同时,与常用的FCN不同,基于像素级的损失函数及交叉熵损失。本文中,基于像素级的sigmoid及二分类损失,不存在类别之间的竞争。
分类损失与边界框损失与Fast R-CNN相似。mask 分支中,针对么个RoI,包含Km^2维度的输出。用于编码K个二分类的mask,大小为mxm,针对K个类别。因此,我们应用一个像素级的sigmoid。定义Lmask为平均二分类交叉熵损失函数。与类别K相对应的ground truth,Lmaks只定义第k个mask。其他mask的输出对此loss损失无影响。Lmask的定义允许网络生成每个类别的masks,与其他类别无关。依赖于分类分支,用于预测输出mask的标签。这里,包含mask及类别的预测。同时,与常用的FCN不同,基于像素级的损失函数及交叉熵损失。本文中,基于像素级的sigmoid及二分类损失,不存在类别之间的竞争。
Mask Representation
mask将输入目标的空间外形进行编码。因此,不同于通过全连接层压缩为向量的类别标记及框偏差,可以通过卷积提取mask的像素级空间结构特征。对于每个RoI使用FCN预测一个mxm的mask。使mask分支中的每一层保持mxm的目标空间形状信息,而不是将特征压缩为向量,从而丢失空间维度。不同于全连接层进行mask预测,全卷积表述需要更少的参数量,同时准确率较高。为了实现像素对像素,要求feature maps很小的RoI特征,很好的保留每个像素对应的空间响应。为此,本文提出了RoIAlign。在进行mask 预测时发挥着重要作用。
RoIAlign
RoIPool对每个RoI提取小feature map(7x7)的标准方法。RoIPool首先量化浮点数的RoI得到离散化feature map。离散处理后的RoI被分为几个空间bins。其中,每个bin也是离散的。每个bin通过最大池化处理得到一个特征值。在连续的坐标x上执行量化操作,如[x/16],16代表feature map的stride,[.]代表近似操作。量化操作在划分bins中。量化操作使RoI与提取的特征不匹配。此变化对类别预测无影响,但是十分不利于像素级的mask预测。
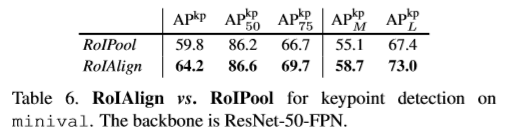
为解决RoI与feature map不匹配问题,本文提出了RoIAlign,用于消除RoIPool造成的量化损失,使提取的特征与输入进行精准的匹配。本文的方法很简单:去除RoI边界或bins中的所有量化操作。比如,使用x/16替换为[x/16]使用双线性插值计算每个RoI bi中输入特征四个角采样位置的精确值,通过使用最大化和均值操作得到结果。如下图,值得注意的是,采样位置及采样点的个数对结果无影响,中间并无量化操作。

Network Architecture
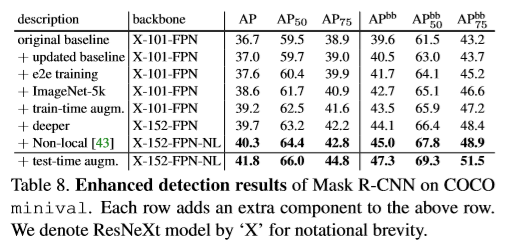
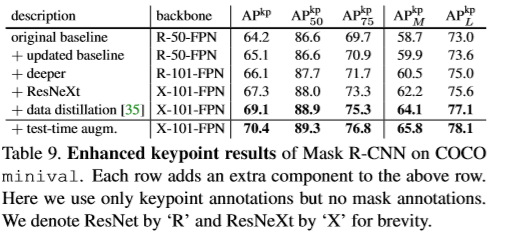
为了证明Mask R-CNN结构的通用性,将Mask R-CNN应用多几个结构。按如下几类特征进行区分:(1)卷积网络结构作为backbone用于提取整张图片的特征。(ii)网络的头部用于边界框的识别(分类及回归)每个RoI单独进行mask预测。本文用网络深度特征作为backbone结构。分别用50层的ResNet及101层的ResNetXt作为backbone。原始的基于ResNet的Faster R-CNN从第四stage的最后一层卷积层进行特征提取。称为C4。本文也采用FPN作为backbone。FPN使用自上而下带侧连接的结构对于单个尺寸的输入建立特征金字塔。通过基于ResNet-FPN的Mask R-CNN取得了较大的提高。
对了网络的头部,在原有网络基础上增加了一个全卷积用于mask预测的分支。更确切的说是本文扩展了Faster R-CNN的box的head。细节如下。

Implementation Details
基于Fast/Faster R-CNN进行参数初始化。
训练:如同Fast R-CNN 当RoI与ground truth的阈值超过0.5则规定为正样例,否则规定为负样例。mask损失只定义在正样例样本(RoI)上。输入图片进行resize操作,尺寸为800x800,mini-batch为2,每张image包含N个采样RoIs。正负样例的比例为1:3,对于基于ResNet的N设置为64,对于FPN的N设置为512;weight decay为0.0001,动量为0.3.RPN中的anchor设置为5个尺寸及3个比例。为方便起见,RPN单独进行训练,与Mask R-CNN不进行特征共享。由于RPN与Mask R-CNN存在相同的backbone,因此,可以进行特征共享。
推理:测试时,proposal的数量为基于ResNet的为300,对于FPN的为1000。在这些proposal上进行box分支预测,同时,使用NMS处理。maks分支应用到分数最高的100个检测框。由于数量少但精度较高的RoIs的存在,mask分支可以对每个RoI预测K个masks。但本文并未使用全部的K个类别,而时只使用分类分支预测出的类别。将mxm大小的浮点数mask 输出进行resize操作,调整至RoI大小,同时以阈值0.5进行二值化处理。
实验
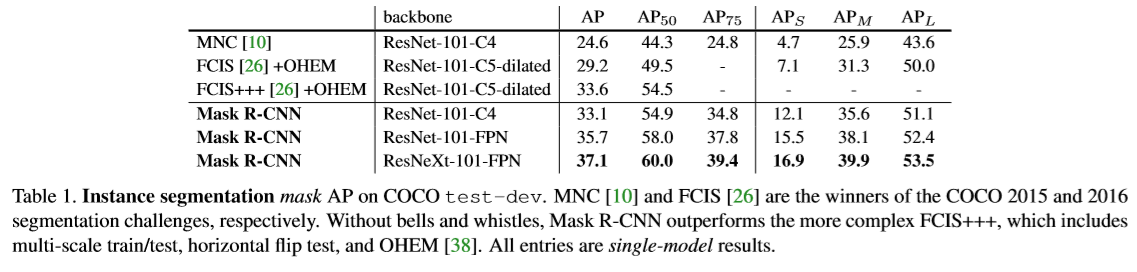
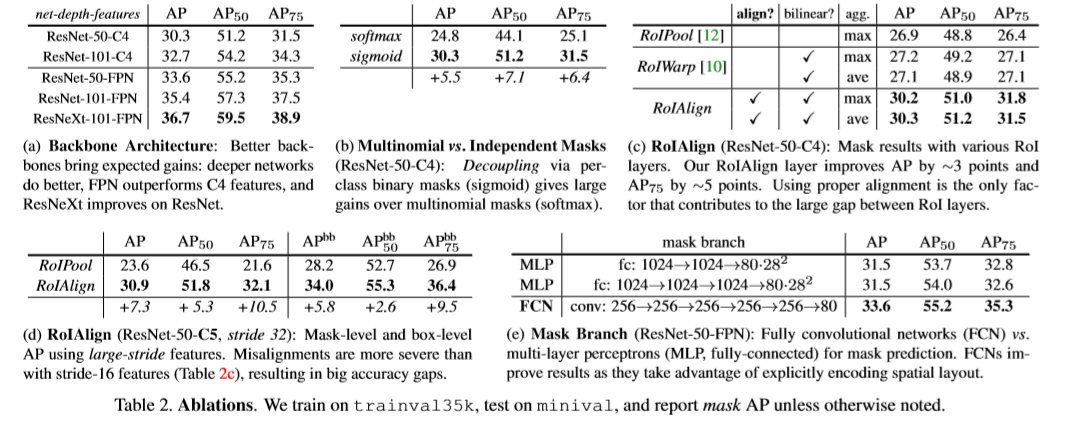
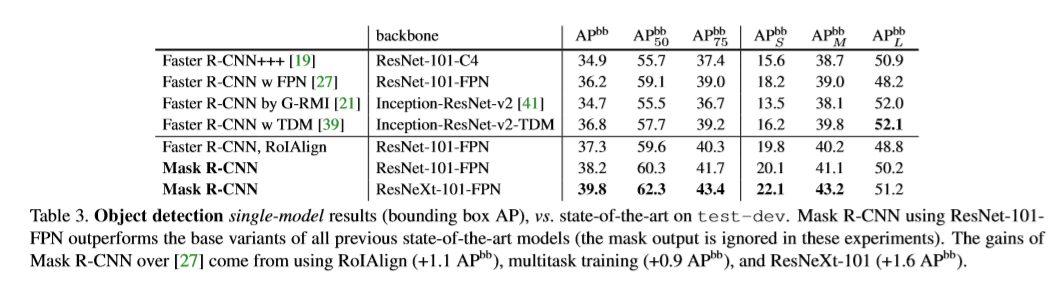








Reference
[1] M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele. 2D human pose estimation: New benchmark and state of the art analysis. In CVPR, 2014. 8
[2] P. Arbel´aez, J. Pont-Tuset, J. T. Barron, F. Marques, and J. Malik. Multiscale combinatorial grouping. In CVPR, 2014. 2
[3] A. Arnab and P. H. Torr. Pixelwise instance segmentation with a dynamically instantiated network. In CVPR, 2017. 3, 9
[4] M. Bai and R. Urtasun. Deep watershed transform for instance segmentation. In CVPR, 2017. 3, 9
[5] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Insideoutside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, 2016. 5
[6] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Realtime multiperson2dposeestimationusingpartaffinityfields. InCVPR, 2017. 7, 8