
论文链接:https://blog.csdn.net/qq_34889607/article/details/8053642
摘要
该文重新窥探空洞卷积的神秘,在语义分割领域,空洞卷积是调整卷积核感受野和DCNN feature map分辨率的有力工具。该文应用不同sample rate的空洞卷积以级联或者平行的方式来处理分割任务中的多尺寸问题。另外,增强了ASPP使其在图像级编码global context来生成卷积特征。该文与DeepLabv1,DeepLabv2不同,将作为后处理的CRF移除,但取得的效果更好。
介绍
针对分割目标不同的尺寸,该文主要从四个方面入手。(1)将DCNN应用于ASPP,不同尺寸的图片在对应网络层中特征更加明显。(2)encoder-decoder结构,利用encoder中的多尺度特征,在decoder中恢复为原图尺寸。(3)添加一个模块级联在DCNN的顶部,用于捕捉远距离像素之间的信息(有使用Dense CRF或者级联基层卷积层)。(4)ASPP具有不同的rate和感受野,可以捕获不同尺寸目标物的信息。
该文主要分析空洞卷积的应用方式,级联或者平行。并分析了当应用一个感受野较大的3x3的空洞卷积时,由于图像边界处无法得到远距离的信息,进而退化为1x1的卷积,该文还将图像级的特征与ASPP结合。针对稀少的有标记物体,作者提出了一种简单但有效的引导方法。
相关工作
全局特征和上下文信息对语义分割进行正确的像素级分类十分重要。该文分析了四种类型的全卷积网络,如下图

Image Pyramid: 应用于多尺寸输入,来自小尺寸的特征响应可以编码远距离的上下文信息。较大尺寸的输入图片可以包含更多的物体细节信息。将不同尺寸的图片输入DCNN,并融合所有尺寸的feature maps。这种结构的缺点是对于较深的DCNN由于GPU的限制并不能对输入图片进行很好的scale操作。
Encoder-decoder:主要包含两部分,a)编码层feature map的空间维度降低很多,更长距离的信息在更深的编码层中更容易被捕捉到。b)解码层的物体细节和空间维度逐渐恢复。应用反卷积将低分辨率的feature map进行上采样。SegNet重新利用编码层中max-pooling 的indices和添加的卷积层来细化得到的特征。UNet是将对应层的特征信息进行拼接,并重新构造了网络。
Context module: 此模块包含额外的级联的模型,用于编码长距离下的语义信息。比如DenseCRF接到DCNN的后面,在DCNN最后一层增加几层卷积,使CRF和DCNN可以联合训练。目前,有一种普适性与稀疏性的高卷积,结合高斯条件随机场来进行分割。
Spatial pyramid pooling: 该文将ResNet的最后几个模块进行复制,并将他们级联,并重新考虑ASPP,这里训练要注意训练时要加上batch normalization。
方法
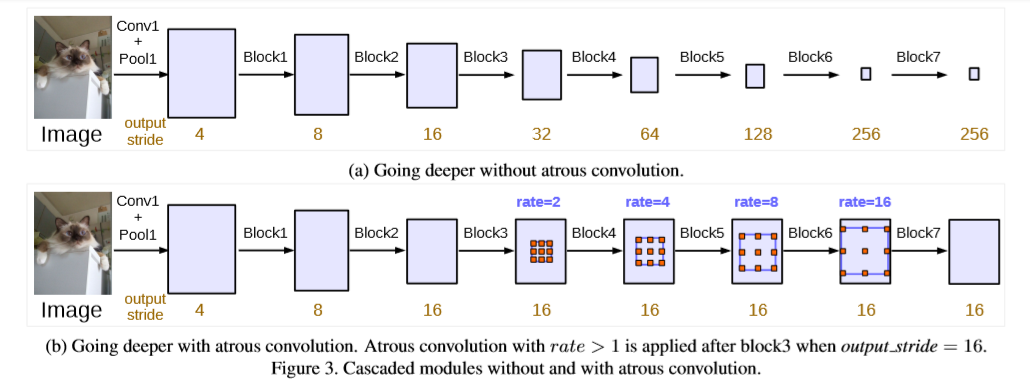
该文主要讨论空洞卷积的两种应用方式-级联或者平行。该文将空洞卷积进行级联,复制了几个ResNet最后的block,使网络加深进而可以获得更长距离的语义信息。但网络层数加深使物体的细节信息就会有损失,所以这里引入了空洞卷积。(output_stride:图像从原始分辨率到最终分辨率降低的倍数。)增加了multi_grid,通过block4到block7之间的不同的sample rate,定义了Multi_Grid={r1,r2,r3},最终,rate的大小值等于Multi_Grid与相应rate值的乘积。
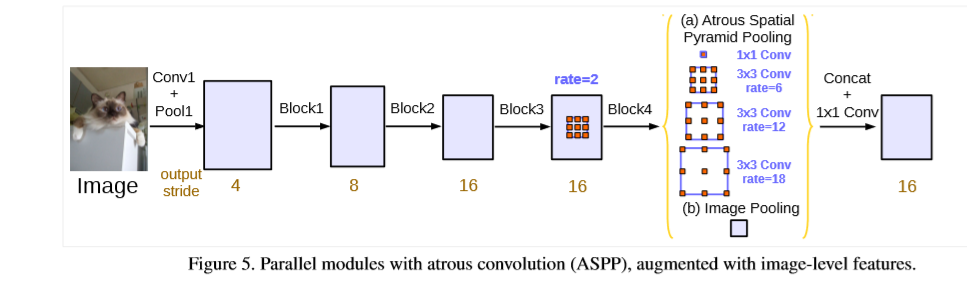
对于ASPP,该文在ASPP中引入了BN层加速训练。但随着sample rate 的增大,filter 的权重有效值越来越小。当rate的大小变为feature map大小时,3x3的filter无法捕捉到全局信息,进而退化为1x1的(相当于1x1的效果),这是因为filter只有中心的权重是有效的。为此,采用图片级的特征,在模型的最后一层增加一层平均池化层,然后将得到的feature map送到,1x1x256的卷积层中,后接BN层,并通过双线性插值上采样到理想分辨率。最终,本文的方法包含一个1x1的卷积和三个3x3的卷积(rates=(6,12,18)),最后所有分支得到的feature map进行拼接,然后送到1x1的卷积(自带BN)中,最后还有一个1x1的卷积来产生最后的logits,结构图如下。
实验
该文在实验中用到了几个策略:(1)学习率的更新策略和deeplabV2相同,poly,(2)进行了裁剪(目的是使空洞卷积的rate尽可能的有效,crop的大小裁剪为513)(3)Batch Normalization(4)Upsampling logits 保证groundtruth的完整性十分重要,将输出上采样8倍与完整的ground Truth进行比较。 (5)数据增强。
参考
[1] M. Abadi, A. Agarwal, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv:1603.04467, 2016.
[2] A. Adams, J. Baek, and M. A. Davis. Fast high-dimensional filtering using the permutohedral lattice. In Eurographics, 2010.