修复一个损坏的gzip文件的关键环节在于找到下一个正常压缩包的起始点。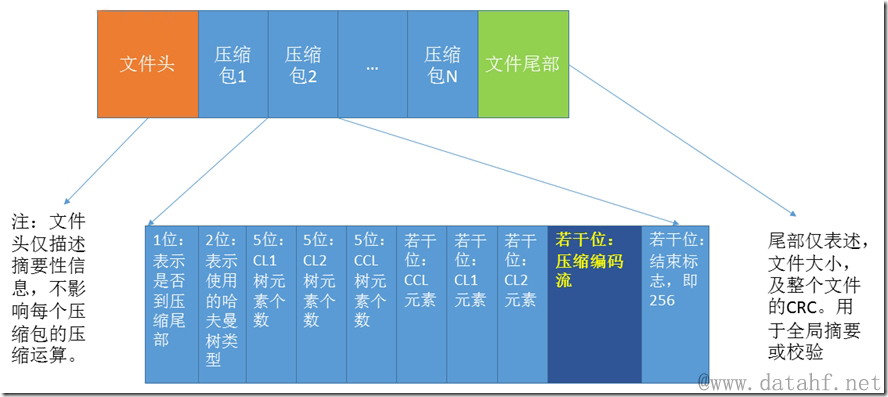
根据结构图中的信息可知,每个压缩包的开始结构中有是否到达尾部标志、使用的哈夫曼树类型、以及3个哈夫曼树的树元素个数等。如果某个gzip文件中间有一个坏扇区,要找到坏扇区后的一个正常起点,仅需按位右移,一直移位到可以正常解压的某个位,就可能找到了正确的压缩包起始。而根据gzip文件的压缩作业窗口为32KB大小推算,这个遍历不会超过64KB即可找到。在内存中快速循环可以很快找到,但需要有明确的判断错误的方法。
首先可以明确的是结尾标志,应该为0(我们是从损坏的点向后查)。而哈夫曼树类型也大致应该是动态哈夫曼(0x02),cl1的元素个数应该取值为257到286之间(包含边界),cl2的元素个数应小于等于30,ccl的元素个数取值可为1-15(包含边界)。
其实,还可以参考的东西有,解开的哈夫曼树是否异常,或者通过规律性原则找到最后一个取值为256的值,但这些算法应该是较为麻烦的,有上面的算法连续校验几个压缩块就足够了。
具体方法是对gzip的源码做修改,进行遍历。因时间关系,未做成通用工程,仅快速修改了部分代码。大致的修改点为:
一,找到损坏点:
在unzip.c中,
error("invalid compressed data--format violated");
这一行前,获取当前解码字节位置即可。
二、遍历找到损坏点:
1、inflate.c文件中,改
if (nl > 286 || nd > 30) #endif return 1;
为:
if (nl > 286 || nd > 30||nl <257 || nd <1) #endif return 1;
2、inflate.c文件中,在int inflate_block(e)函数中
在如下代码前
bb = b;
bk = k;
加入代码:
if ((t != 2) || (*e != 0)) return 2;
3、inflate.c文件中,在int inflate_block(e)函数尾部
把if (t == 0) 与if (t == 1)的情况都直接返回错误值2。
4、inflate.c文件中,函数int inflate()中,改
if ((r = inflate_block(&e)) != 0) return r; end
为:
unsigned t; /* block type */ register ulg b; /* bit buffer */ register unsigned k; /* number of bits in bit buffer */ while (inptr <= insize) { unsigned int tptr = inptr; unsigned int tbk = bk; unsigned long tbb = bb; unsigned int twp = wp; long long tstart = *(long long*)(inbuf + tptr); if ((r = inflate_block(&e)) != 0) { inptr = tptr; bb = tbb; bk = tbk; wp = twp; b = bb; k = bk; NEEDBITS(1) DUMPBITS(1) } else { printf("get by www.datahf.net!"); //也可输出tstart,bb,bk 值,转载时请保留版权信息:www.datahf.net张宇 } }
此4步完成后,试着调试这个错误的.gz文件,当然,也可以在代码中解释完头部结构后加一个seek,直接seek到损坏位置。
通常情况下,输出printf(“get by www.datahf.net!”)这行代码时,已经找到了正确的起始位。
找到起始位后,也可以构造或拷贝一个正常的gzip文件头,再拼接好找到的位流,即可解压了。(如果位流不是字节对齐的,可能要全部做位移)。拼接后很多压缩文件就可以打开甚至于解压了,不过,有可能会报错,主要是尾部的校验和大小错,其实可以忽略。
如果拼接好了linux下,不能直接用“gzip –d”解压,因其crc有错误,会导致解压到99%后报错,然后把文件删除,换成管道命令即可: