表类型(存储引擎)的选择
本文引用:https://www.cnblogs.com/jswang/p/6923911.html
7.1 mysql存储引擎概述
插件式存储引擎是mysql数据库最重要的特性之一,用户可以根据应用的需要选择ruhr存储和索引数据,是否使用事务等。
InnoDB和BDB提供事务安全表,其他存储引擎都是非事务安全表
创建新表时如果不指定存储引擎,那么系统就会使用默认存储引擎,mysql5.5之前的默认引擎时MyISAM,之后是InnoDB(关键字:ENGINE)
7.2 各种存储引擎的特性
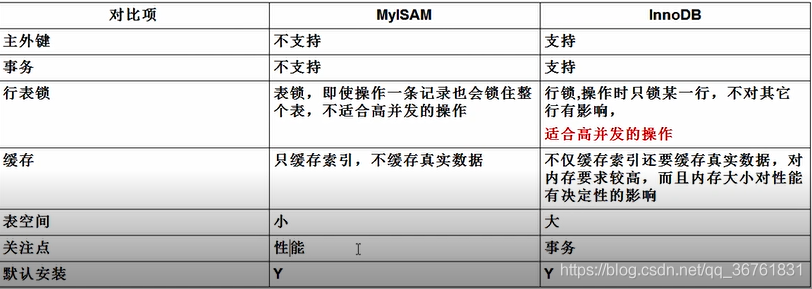
7.2.1 MyISAM
缺点:不支持事务,也不支持外键
优点:访问速度快,对事务的完整性没有要求或者以select、insert为主的应用基本上都可以使用这个引擎来创建
MyISAM再磁盘上存储成三个文件,其文件名都和表名相同,但扩展名分别是:.frm(存储表定义),.MYD(存储数据),.MYI(存储索引)
数据文件和索引文件可以放置在不同的目录,平均分布IO,获得更快的速度。通过(创建表时DATA DIRECTORY和INDEX DIRECTORY(需要时据对路径,和访问权限))
MyISAM类型的表可能会损坏,原因可能是多种多样,check table ,repair table。
表损坏可能导致数据库异常重新启动,需要尽快修复并尽可能地确认损坏的原因。
MyISAM表嗨支持3中不同的存储格式:1.静态(固定长度)表 2.动态表 3.压缩表
静态表是默认的存储格式。静态表中的字段都是非变长字段,这样每个记录都是固定长度,这种存储的优点是存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多。静态表的数据再存储时会按照列的宽度定义补足空格,但是在应用访问的时候不会得到这些空格。但是需要特别注意的问题,如果需要保存的内容后面本来就有空格,那么在返回的时候也会被去掉。
动态表中包含变长的字段,记录不是固定长度的。这样优点是节省存储空间,但是频繁的更新和删除记录会产生碎片,需要定期执行optimize table 或 myisamchk-r命令来改善性能,并且在出现故障时恢复起来比较困难。
压缩表由myisampack工具创建,占据非常小的磁盘空间,因为每个记录是被单独压缩的,所以只有非常小的访问开支。
7.2.2 InnoDB
InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM,处理效率差一些,并且会占用更多的磁盘空间以保留数据和索引。
1.自动增长列
如果插入的是空或者0,则实际插入的僵尸自动增长后的值。通过“alter table *** auto_increment = n”语句强制设置自动增长列的初始值,如果在使用之前重新启动数据库,则需要重新设置,不设置默认初始值为1.对于InnoDB表来说自动增长列必须是索引。如果是组合索引,也必须是组合索引的第一列,但是对于MyISAM表,自动增长列可以是组合索引的其他列,这样插入记录后,自动增长列按照组合索引前面几列进行排序后递增的。
2.外键约束
MySQL支持外键的存储引擎只有InnoDB,在创建外键的时候,要求父表必须有对应的索引,字表在创建外键的时候也会自动创建对应的索引。
当某个表被其他表创建的外键参照,那么该表的对应索引或者主键禁止被删除。
在导入多个表的数据时,如果需要忽略表之前的导入顺序,可以暂时关闭外键的检查,在处理LOAD DATA 和 ALTER TABLE操作的时候,可以关闭外键约束来加快处理速度,“set foreign_key_checks = 0(1开)”
对于InnoDB类型的表,外键信息通过使用show create table 或者 show table status命令显示
3.存储方式
InnoDB存储表和索引有以下两种方式。
使用共享表空间存储,这种方式创建的表的表结构保存在.frm文件中,数据和索引保存在innodb_data_home_dir和innodb_data_file_path定义的表空间中,可以是多个文件。
使用多表空间存储,这种方式创建的表的表结构仍然保存在.frm文件中,但是每个表的数据和索引单独保存在.ibd中。如果是分区表,则每个分区对应单独的.ibd文件,文件名是“表名+分区名”,可以在创建分区的时候指定每个分区的数据文件的位置,一次来将表的IO均匀的分布在多个磁盘上。要使用多表空间的存储方式,需要设置参数innodb_file_per_table,并且重启服务才能生效,对于新建的表按照多表空间的方式创建,已经有的仍然使用共享表空间存储。多表空间的数据文件没有大小限制,不需要设置初始化大小,也不需要设置文件的最大限制、扩展大小等参数。对于使用多表空间特性的表,可以比较方便地进行单表备份和恢复操作,
7.2.3 MEMORY
MEMORY存储引擎使用存在于内存中的内容来创建表。每个MEMORY表只实际对应一个磁盘文件,格式是.frm。MEMORY类型的表访问非常地快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢掉。服务器需要足够的内存来维持所有在同一时间使用的MEMORY表,当不再需要MEMORY表的内容是释放资源。每个MEMORY表中可以放置的数据量的大小,收到max_heap_table_size系统变量的约束,这个系统变量的初始值是16MB,通过MAX_ROWS指定表的最大行。
MEMORY类型的存储引擎主要用于那些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地对中间结果进行分析并得到最终的统计结果。对存储引擎为MEMORY的表进行更新操作要谨慎,因为数据没有写到磁盘中,所以一定要对下次重启服务后如何获得这些修改后的数据。
7.2.4 MERGE
MERGE存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构相同,MERGE表本生没有数据结构,对MERGE类型可以进行查询、更新、删除操作,这些操作实际上是对内部的MyISAM表进行的
对MERGE类型表进行插入操作,是通过INSERT_METHOD子句定义插入的表,可以有3个不同的值,first、no、last。当不定义或者为no时,不能对表进行进行插入操作。
对MERGE表进行drop操作实际上只是删除MERGE的定义,对内部的表没有任何影响。
MERGE表在磁盘上保留两个文件,.frm文件存储表的定义,.MRG文件包含组合表的信息,包括MERGE表由哪些表组成、插入新的数据时的依据。可以通过修改.MRG文件来修改MERGE表,但是修改后要通过flush tables刷新
7.2.4 TokuDB
第三方常用的存储引擎:列式存储引擎infobright,高写性能高压缩的TokuDB
TokuDB是一个高性能、支持事务处理的Mysql和MariaDB的存储引擎,具有高扩展性、高压缩率、高效的写入性能,支持大多数在线DDL操作。
特性:
使用Fractal树索引保证高效的插入性能
优秀的压缩特性,比InnoDB高近10倍
Hot Schema Changes特性支持在线创建索引和添加、删除属性列等DDL操作
使用Bulk Loader达到快速加载大量数据
提供主从延迟消除技术
支持ACID(指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability))和MVCC(多版本并发控制)
使用场景:
日志数据,因为日志通常插入频繁且存储量大
历史数据,通常不会再有写操作,可以利用TokuDB的高性能压缩特性进行存储
在线DDL比较频繁的场景,使用TokuDB可以大大增加系统的可用性。
7.2 如何选择合适的存储引擎
在选择存储引擎时,应根据应用特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
MyISAM:默认的Mysql插件式存储引擎(5.5之前)。如果应用是以读操作和插入操作为主,只有少量的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎非常合适。例如:Web、数据仓库和其他应用环境下最常用的存储引擎之一
InnoDB:用于处理事务应用程序,支持外键。如果应用对事务的完整性有较高的要求,在并发条件下要求数据的一致性,数据除了插入查询之外,还包括很多的更新、删除操作,那么InnoDB存储引擎应该是比较合适的。InnoDB存储引擎除了有效的降低由于删除和更新导致的锁定,还可以确保事务的完整的提交和回滚,对于类似计费系统或者财务系统等对数据准确性要求比较高的系统,InnoDB都是合适的选择。
MEMORY:将所有的数据保存在RAM中,在需要快速定位记录和其他类似数据的环境下,可提供几块的访问,MEMORY的缺陷是对表的大小有限制,太大的表无法缓存在内存中,其次是要确保表的数据可以恢复,数据库异常终止后表中的数据数据是可以恢复的。MEMORY表通常更新不太频繁的小表,用以快速得到访问结果。
MERGE:用于将一系列的MyISA表以逻辑方式组合在一起,并作为一个对象引用它们。有点突破了单个MyISAM表大小的限制,并且通过将不同的表分布在多个磁盘上,可以有效地改善MERGE表的访问效率。这对于数据仓库等VLDB(超大型数据库)环境十分合适