2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的
Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时间来排谁先执行
这里会有几个问题,Timestamp是什么,由谁来打,什么时候打上Timestamp
首先每个T需要有一个unique的timestamp,这个在单机很容易实现;
其次,Timestamp必须是单调递增的
最后,不同的schema会选择在不同的时间给txn打上timestamp,可能是txn刚到的时候,也可能是txn执行完的时候
Timestamp可以有多种形式,系统时间,逻辑counter,或者hybrid

Basic Timestamp Ordering Protocol
设计比较直觉,
首先,给每个object加上,读时间戳,写时间戳,表示最后一次读写该对象的时间
读的时候,拿当前事务ts和写ts比较,如果写ts比较新,那么读需要abort,因为,你不能读一个未来的值;
写的时候,要同时比较该对象的读,写ts,比较写是因为你不能用过去的值覆盖未来的值,比较读,是因为如果有未来的txn读过这个值,你就不能再更新
同时,这里无论读写,都会把当前的value,copy到local进行缓存,这是避免txn频繁冲突,因为对于一个txn数据应该可以重复读的,所以如果不缓存,那么如果这个值被别的txn改了,会很容易导致txn abort



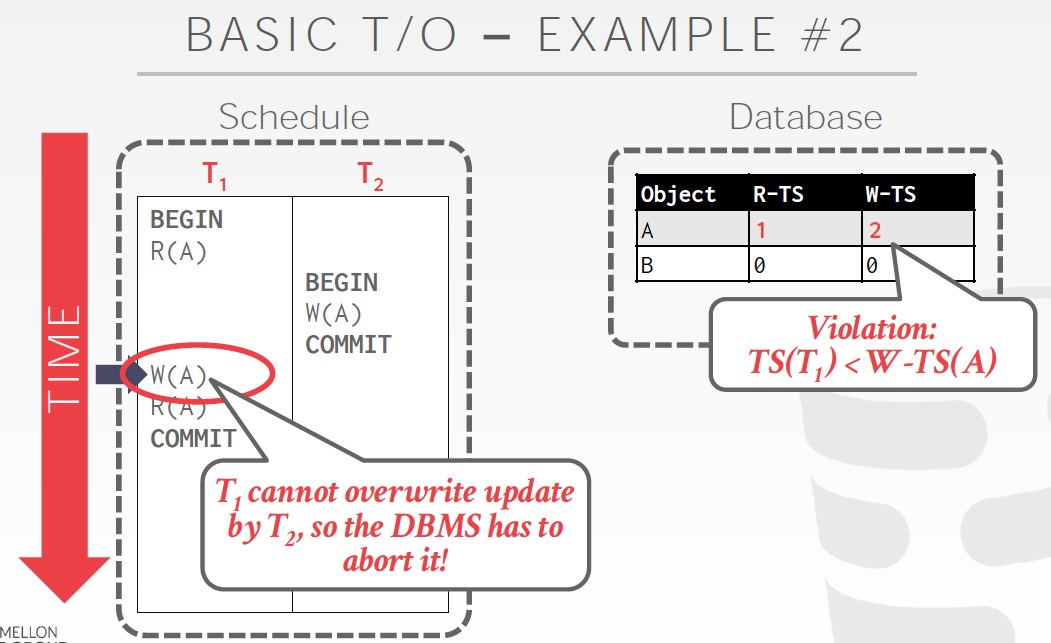
例子,
T1在更新A的时候,ts已经小于W-TS,所以不能更新,需要abort
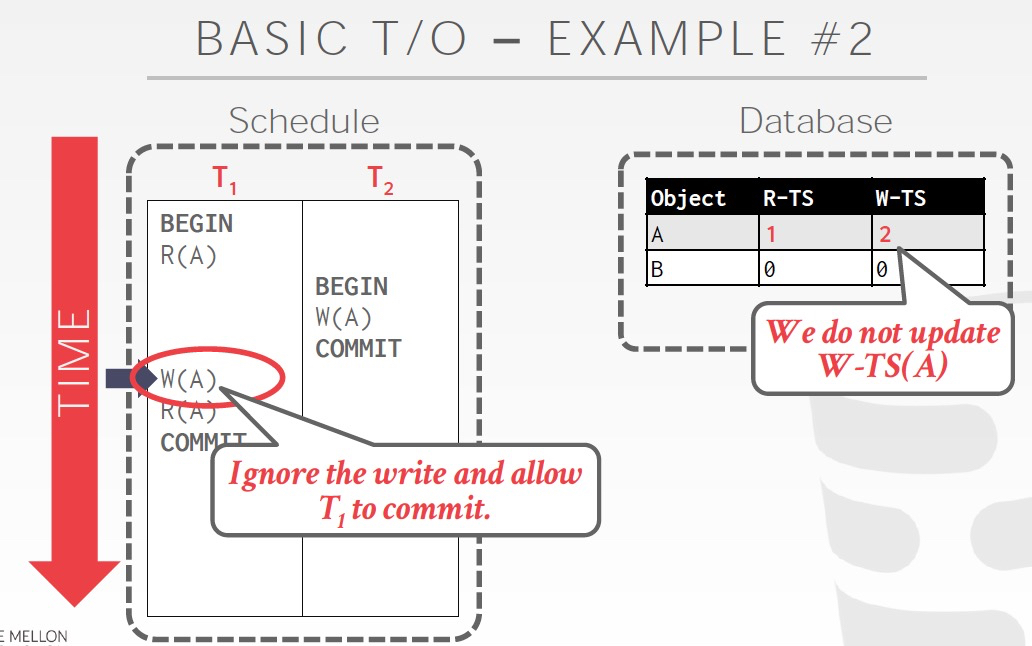
Thomas write rule,一种降低abort概率的方法
思路如果txn在write的时候发现,W-TS大,即未来的时间,那么直接跳过这个write,因为这个write反正都是被覆盖的,所以不关键;

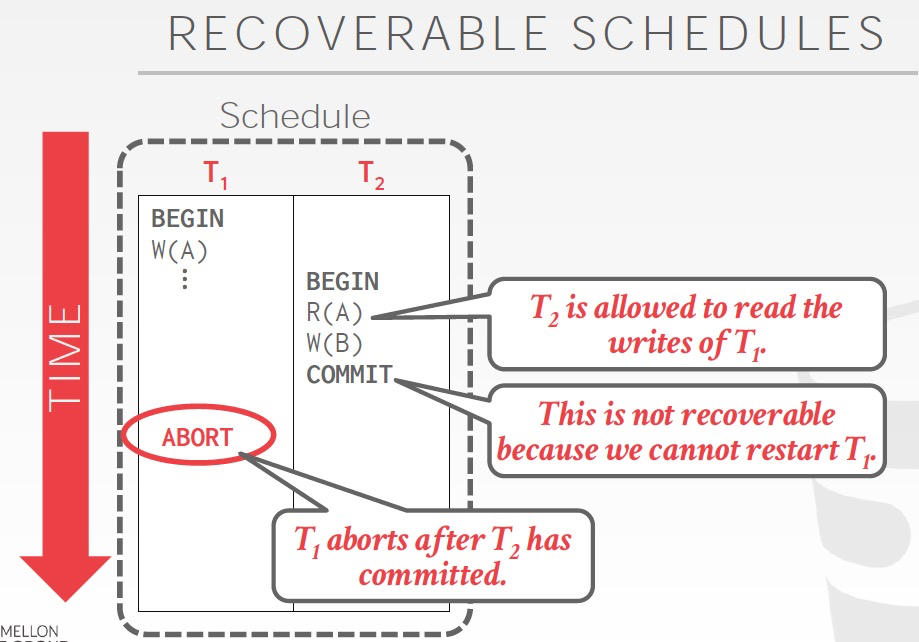
用Basic T/O产生的shedule是不可recoverable的
什么叫recoverable,当你commit的时候,你所依赖的所有txn已经完成commit;
这样才是可恢复的,不然你commit完后,数据库crash了,那么你之前看到的或依赖的txn还没有commit就丢失了,但你的结果已经完成commit,就产生不一致

Basic T/O的问题,
1. 不可recoverable
2. overhead比较重,需要每次读写都更新ts,而且还需要把数据copy到local
3. 长txn会starve,比较难成功,因为很容易被冲突,abort

乐观锁,基于的假设,冲突极少发生,否则乐观锁的成本反而更加高
所以基于这样的假设,那么算法可以进一步优化,OCC算法
分3个阶段,
1. 每个txn都创建一个独立的workspace,无论读写,都把数据copy到自己的workspace里面进行操作
2. validate,这个txn是否和其他txn冲突
3. 如果不冲突,把变更合并到global数据库


可以看到,其中比较难的是第二步,validation
validation就是判断当前txn和所有其他的txn是否有WR或WW冲突
首先假设同时只有一个txn进行validation,即serial validation
然后txn的ts是在validation阶段的开始被assign的,这个很关键
如何check当前txn和其他所有的txn之间是否有冲突?
如果Ti 先于 Tj,那么我们要满足以下3个条件中的一个

1. Ti在Tj开始之前,完成所有3个阶段,就是串行执行,这个肯定没有冲突

2. Ti在Tj开始Write phase前完成,并且Ti没有写任何会被Tj读到的对象

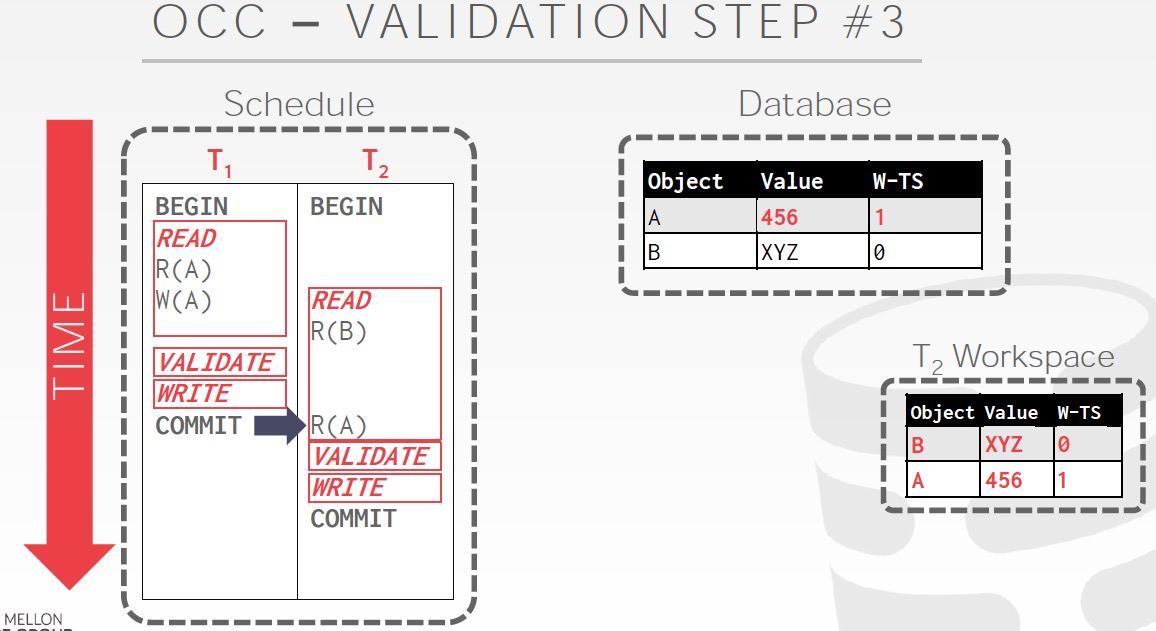
例子,
T1写了A,而在T2中会读到A,这样就不满足上面的条件2

这种情况是安全的,因为这个时候T2也已经结束了,并且T2只是读了A当并没有写任何数据
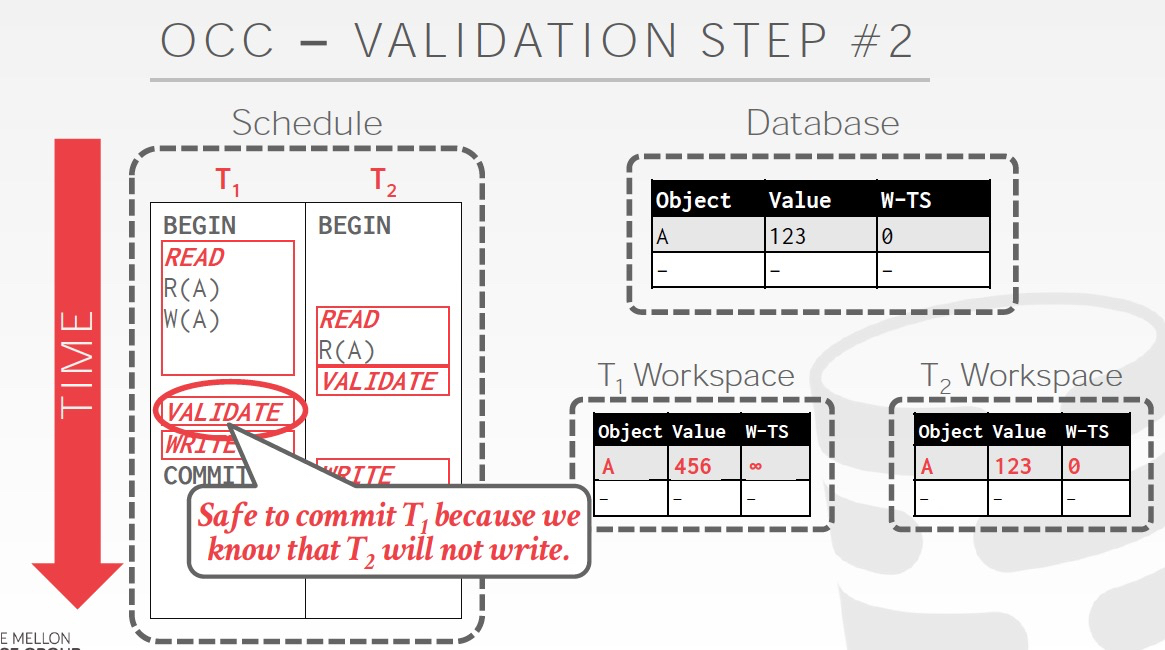
3. Ti的Read phase比Tj的Read phase早结束,并且Ti没有写任何会被Tj读或写到的对象

例子,
这个例子T1在validation的时候,T2没有读或写A,所以安全的,把T1的结果提交到Database
然后这个时候T2读A,是不会有问题的

OCC算法的性能问题,
也要把数据copy到本地,比较高的overhead
Validation和Write会成为瓶颈,因为这里需要串行
Abort的代价更高,因为这里txn已经做完了,才会validation判断是否要abort

OCC算法,还有明显的性能问题,当txn很多的时候,每个txn提交,都需要去判断是否和其他的txn冲突,就算没有冲突,但是每次比较的代价也是非常高的
所以提出Partition-based T/O,如果数据水平划分成很多partition,那么在每个partition上的txn就会变少,比较txn之间的冲突的效率就会提升

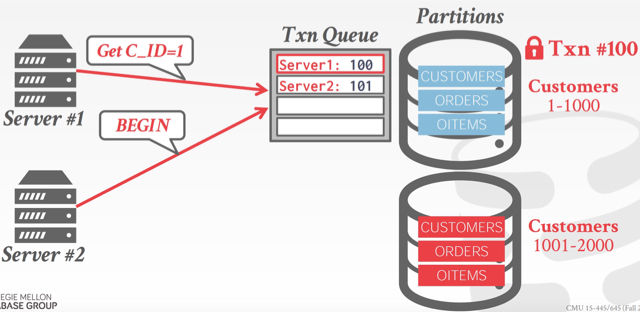

Partitioned T/O的性能问题是,
如果每个txn都只访问一个partition,那么性能会比较好

幻读
之前的txn都是读写,但是没有insert或delete
所以对于下面的情况,2PL是不管用的,因为锁机制只能锁已经存在的tuple,所以这个问题是Phantom,幻读

解决这个问题的方法,
predict locking,满足这个predict的records都lock,这个很难实现

对于predict locking一种可能的实现方式是,index locking,锁包含这个predict的index page
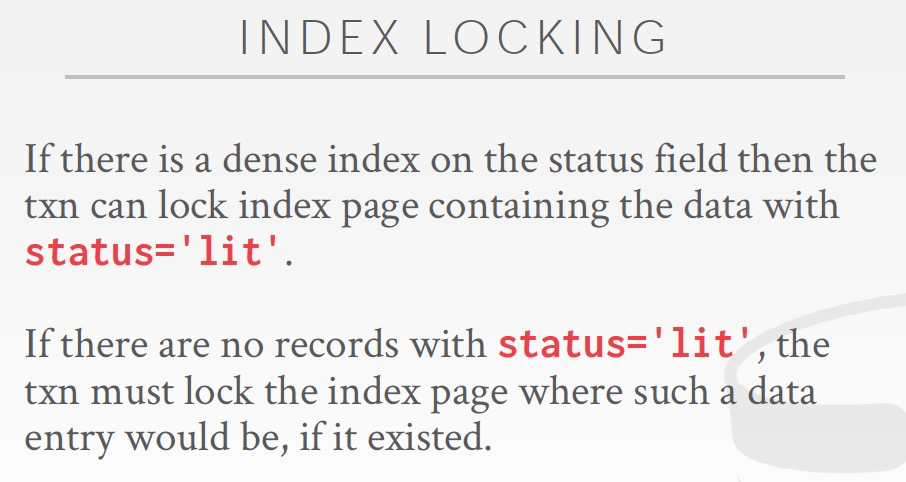
如果没有合适的index,只能锁表上的每一页或直接锁table

通过重复查询来判断是否有幻读,很低效的方式,一般数据库都不会采用

这里最后再讲一个概念,隔离级别
最强的就是之前一直在讲的,serializable,虽然有最强的一致性,但也大大牺牲了数据库的并发性
但是有的应用和场景,其实不需要那么强的一致性,所以可以牺牲一些一致性来换取一定的并发性
不同的隔离级别会产生哪些不一致情况在右图可以看出

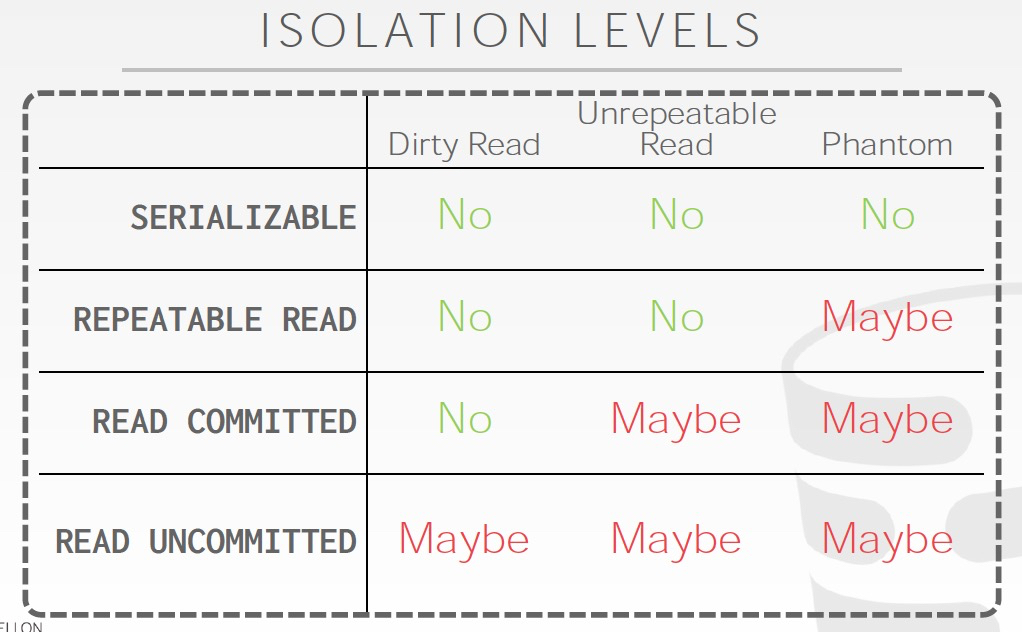
那么如何实现这些隔离级别?

列出在SQL标准中,如果设置隔离级别

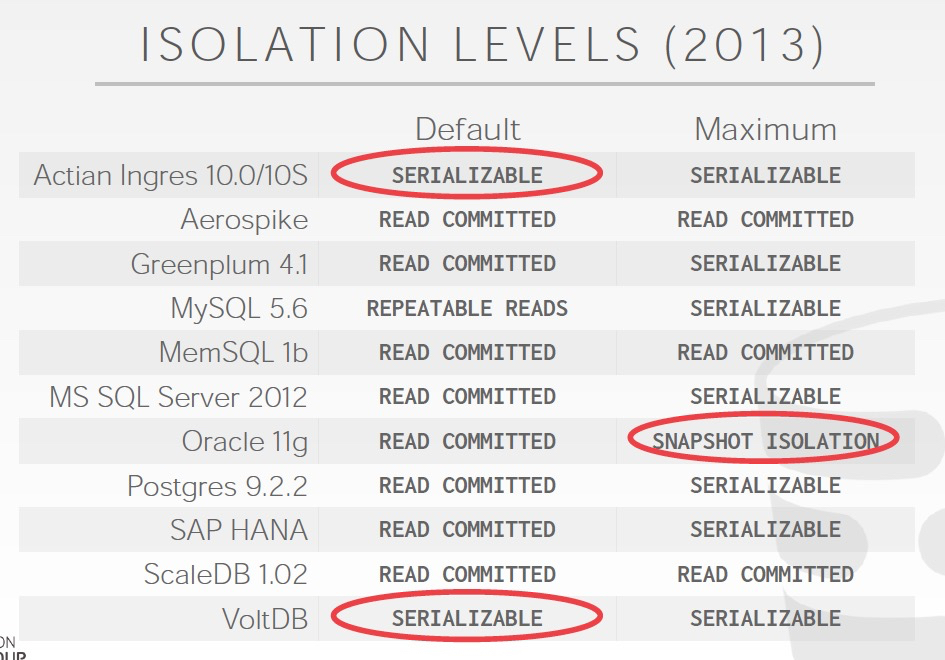
这里列存各个数据库引擎,默认的和支持的隔离级别