作业一:
代码:
bookSpiders.py:
import scrapy
from bs4 import UnicodeDammit
from MySQL.items import BookItem
class bookSpider(scrapy.Spider):
name = "bookSpider"
key = 'python'
source_url = 'http://search.dangdang.com/'
def start_requests(self):
url = bookSpider.source_url + "?key=" + bookSpider.key
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath(
"./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# detail有时没有,结果None
item = BookItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
# link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next'] / a / @ href").extract_first()
# if link:
# url = response.urljoin(link)
# yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
items.py:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()pipelines.py
import pymysql
class BookPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened: self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "本书籍")
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute(
"insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values(%s,%s,%s,%s,%s,%s)",
(item["title"], item["author"], item["publisher"], item["date"], item["price"], item["detail"]))
self.count += 1
except Exception as err:
print(err)
return itemsettings.py:
ITEM_PIPELINES = {
'MySQL.pipelines.BookPipeline': 300,
}run.py:
from scrapy import cmdline
cmdline.execute("scrapy crawl bookSpider -s LOG_ENABLED=False".split())结果展示:

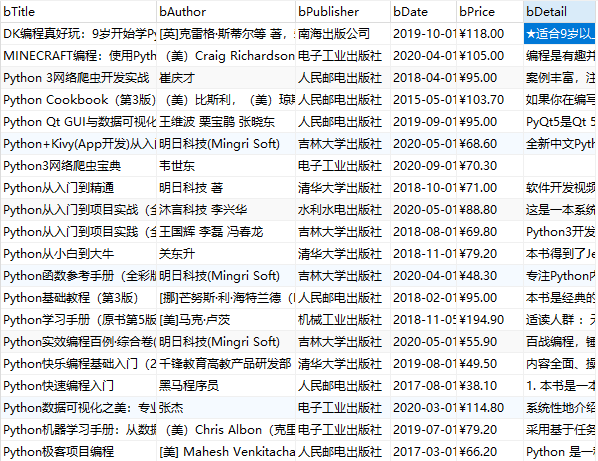
心得:
参照书上的内容,学习mysql的保存方法,同时学习使用mysql软件的使用,之前还没有使用过。
作业二:
代码:
sharespider.py:
import scrapy
from selenium import webdriver
from share.items import lineItem
class sharespider(scrapy.Spider):
name = "sharespider"
source_url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board'
def start_requests(self):
url = sharespider.source_url
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
print('1')
driver = webdriver.Chrome()
driver.get(sharespider.source_url)
# html = driver.page_source
# print(html)
lis = driver.find_elements_by_xpath("//*[@id='table_wrapper-table']/tbody/tr")
for li in lis:
lists = li.text.split(" ")
item = lineItem()
item["id"] = lists[1]
item["name"] = lists[2]
item["new_price"] = lists[6]
item["up_rate"] = lists[7]
item["down_rate"] = lists[8]
item["pass_number"] = lists[9]
item["pass_money"] = lists[10]
item["rate"] = lists[11]
item["highest"] = lists[12]
item["lowest"] = lists[13]
item["today"] = lists[14]
item["yesterday"] = lists[15]
yield item
except Exception as err:
print(err)
items.py:
import scrapy
class lineItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id=scrapy.Field()
name=scrapy.Field()
new_price=scrapy.Field()
up_rate=scrapy.Field()
down_rate=scrapy.Field()
pass_number=scrapy.Field()
pass_money=scrapy.Field()
rate=scrapy.Field()
highest=scrapy.Field()
lowest=scrapy.Field()
today=scrapy.Field()
yesterday=scrapy.Field()
passpipelines.py
import pymysql
class SharePipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from share")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
self.count += 1
if self.opened:
self.cursor.execute(
"insert into share(count,id,name,new_price,up_rate,down_rate,"
"pass_number,pass_money,rate,highest,lowest,today,yesterday)"
"values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(self.count, item["id"], item["name"], item["new_price"], item["up_rate"], item["down_rate"],
item["pass_number"], item["pass_money"], item["rate"], item["highest"], item["lowest"],
item["today"], item["yesterday"]))
except Exception as err:
print(err)
return itemsettings.py:
ITEM_PIPELINES = {
'share.pipelines.SharePipeline': 300,
}run.py:
from scrapy import cmdline
cmdline.execute("scrapy crawl sharespider -s LOG_ENABLED=False".split())结果展示:
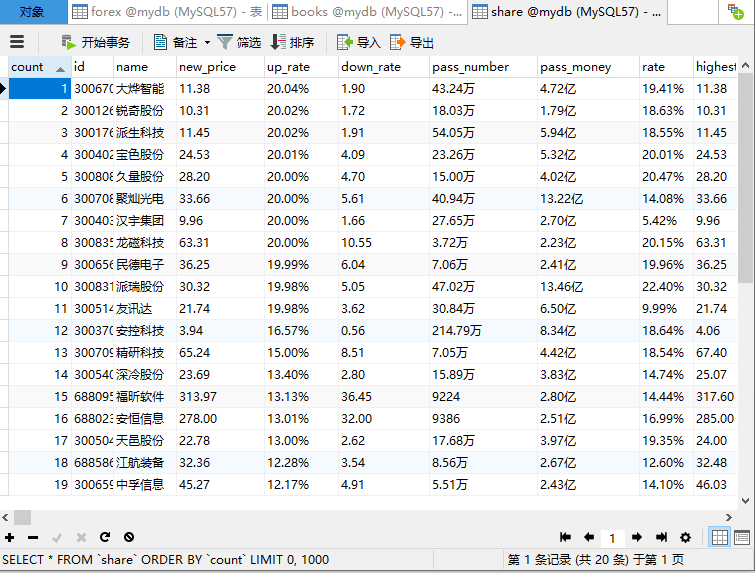
心得:
要求使用Xpath,之前用的js爬的数据方式不行,使用Selenium方式爬取网站再用Xpath方法,按照ppt里的教程整个实现起来也挺快的,学习了一种新的好用的爬取动态数据的方法。
作业三:
代码:
forexspider.py:
import scrapy
from selenium import webdriver
from forex.items import ForexItem
class forexspider(scrapy.Spider):
name = "forexspider"
source_url = 'http://fx.cmbchina.com/hq/'
def start_requests(self):
url = forexspider.source_url
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
print('start')
driver = webdriver.Chrome()
driver.get(forexspider.source_url)
# html = driver.page_source
# print(html)
lis = driver.find_elements_by_xpath("//*[@id='realRateInfo']/table/tbody/tr")
for li in lis:
lists = li.text.split(" ")
if lists[0] != '交易币':
item = ForexItem()
item["Currency"] = lists[0]
item["TSP"] = lists[3]
item["CSP"] = lists[4]
item["TBP"] = lists[5]
item["CBP"] = lists[6]
item["Time"] = lists[7]
yield item
except Exception as err:
print(err)
items.py:
import scrapy
class ForexItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
passpipelines.py
import pymysql
class forexPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from forex")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
self.count += 1
if self.opened:
print("写入", item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"])
self.cursor.execute(
"insert into forex(id,Currency,TSP,CSP,TBP,CBP,Time) values (%s,%s,%s,%s,%s,%s,%s)",
(self.count, item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"]))
except Exception as err:
print(err)
return item
settings.py:
ITEM_PIPELINES = {
'forex.pipelines.forexPipeline': 300,
}run.py:
from scrapy import cmdline
cmdline.execute("scrapy crawl forexspider -s LOG_ENABLED=False".split())结果展示:
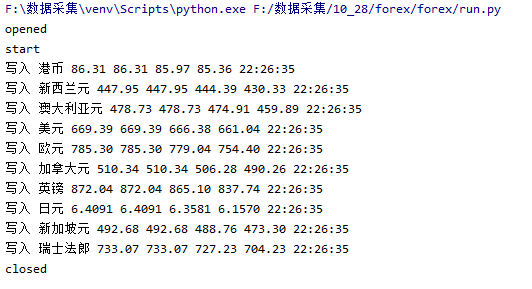
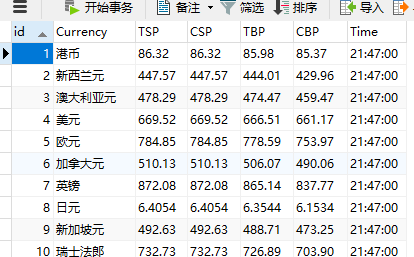
心得:
在实现了作业二后,实现作业三的整个流程更加熟悉,加深了对Xpath,MySQL的使用。