| 这个作业属于哪个课程 | 福州大学软件工程 |
|---|---|
| 这个作业要求在哪里 | 第一次个人编程作业要求 |
| 这个作业的目标 | 了解github的使用以及json数据的处理 |
| 学号 | 031802538 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 90 |
| Estimate | 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 120 | 180 |
| Analysis | 需求分析 (包括学习新技术) | 240 | 360 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 30 | 60 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| Design | 具体设计 | 30 | 60 |
| Coding | 具体编码 | 120 | 240 |
| Code Review | 代码复审 | 30 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 90 |
| Reporting | 报告 | 30 | 60 |
| Test Report | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 50 | 60 |
| 合计 | 890 | 1420 |
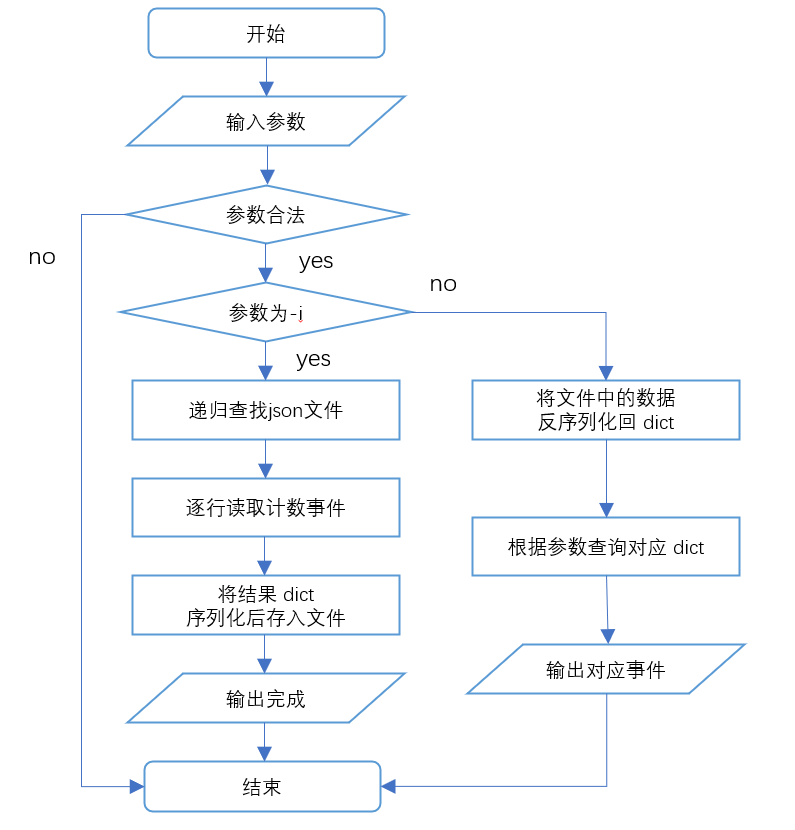
解题思路
前言
对于只会基础C++的我,看到这题的时间直接当场GG,在向大佬了解情况后知道对于数据处理方面,python比较实用而且便利,于是开启一场从零开始copy的旅程。首先对于github小白,我先是学习学长发布的B站视频,了解git指令的使用,这部分可能会是最简单的部分。之后便开始学习各类python指令,学习命令行参数的设置(以及这些到底都是什么),在用python读取json中一直报错(疑惑),只好向大佬求助,学习了其读取方式,用递归遍历文件夹后取文件逐行解析。而对于数据分析的部分,大佬推荐的正则表达式的匹配优化,于是我将其运用同时咨询优化方法。对于示例程序的递归展开部分运行了许多冗余信息,直接遍历搜索更快。最后在快提交的时间才知道fork仓库(甚至是别人帮我fork)
具体思路
- 作业要求:通过命令行参数设置解析 json 文件,统计用户或项目发生的某种事件的数量
- 目前情况:什么都不会,选择了学习python来完成实践,同时不懂就问大佬
- 编程计划:首先通过慕课网了解python的基本使用,然后通过分析示例程序优化
- 日常思考:有空可以思考优化方面,同时不断更新github
设计实现过程
- 首先设置好命令行参数与及初始化部分
- 通过os.walk() 方法遍历文件夹下的文件,读取多个.json文件,并且通过.append()与json.loads()方法将多个 json数据存入同一数组
- 通过正则表达式匹配其中的字符串分析
- 将dict序列化后存入1、2、3.json文件
代码说明
具体查看代码注释,暂时不是很规范仅为美观
# -*- coding: utf-8 -*-
import os
import argparse
import pickle
import re
DATA = ("PushEvent", "IssueCommentEvent", "IssuesEvent", "PullRequestEvent" )
# 匹配时使用
pattern = re.compile(r'"type":"(w+?)".*?actor.*?"login":"(S+?)".*?repo.*?"name":"(S+?)"')
# 正则表达式的使用,优化匹配速度
class Data:
def __init__(self):
self._user = {}
self._repo = {}
self._user_repo = {}
# 初始化记录读取的内存
# 可使函数无参使用
@staticmethod
def __parse(file_path: str):
# 从json文件中逐行抽取所需信息元组(event, user, repo)
# 将有用信息存入此空间
records = []
# 打开json文件
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
# 运用正则表达式匹配有效数据
res = pattern.search(line)
if res is None or res[1] not in DATA:
continue
records.append(res.groups())
return records
def init(self, dir_path: str):
records = []
# 跑目录
for cur_dir, sub_dir, filenames in os.walk(dir_path):
# 保留后缀为json
filenames = filter(lambda r: r.endswith('.json'), filenames)
for name in filenames:
# 将列表扩展拼合
records.extend(self.__parse(f'{cur_dir}/{name}'))
for record in records:
event, user, repo = record
# 取值或创建
self._user.setdefault(user, {})
self._user_repo.setdefault(user, {})
self._repo.setdefault(repo, {})
self._user_repo[user].setdefault(repo, {})
# 如果不存在就初始化为0
self._user[user][event] = self._user[user].get(event, 0)+1
self._repo[repo][event] = self._repo[repo].get(event, 0)+1
self._user_repo[user][repo][event] = self._user_repo[user][repo].get(event, 0)+1
# 字典转为字符串
# 将数据写入1、2、3.json
with open('1.json', 'wb') as f:
pickle.dump(self._user, f)
with open('2.json', 'wb') as f:
pickle.dump(self._repo, f)
with open('3.json', 'wb') as f:
pickle.dump(self._user_repo, f)
def load(self):
if not any((os.path.exists(f'{i}.json') for i in range(1, 3))):
raise RuntimeError('error: data file not found')
with open('1.json', 'rb') as f:
self._user = pickle.load(f)
with open('2.json', 'rb') as f:
self._repo = pickle.load(f)
with open('3.json', 'rb') as f:
self._user_repo = pickle.load(f)
def get_user(self, user: str, event: str) -> int:
return self._user.get(user, {}).get(event, 0)
def get_repo(self, repo: str, event: str) -> int:
return self._repo.get(repo, {}).get(event, 0)
def get_user_repo(self, user: str, repo: str, event: str) -> int:
return self._user_repo.get(user, {}).get(repo, {}).get(event, 0)
class Run:
# 参数设置
def __init__(self):
self.parser = argparse.ArgumentParser()
self.data = None
self.arg_init()
# 设置可能有的参数,便于解析
def arg_init(self):
self.parser.add_argument('-i', '--init', type=str)
self.parser.add_argument('-u', '--user', type=str)
self.parser.add_argument('-r', '--repo', type=str)
self.parser.add_argument('-e', '--event', type=str)
def analyse(self):
args = self.parser.parse_args()
self.data = Data()
if args.init:
self.data.init(args.init)
return 'init done'
self.data.load()
if not args.event:
raise RuntimeError('error: the following arguments are required: -e/--event')
if not args.user and not args.repo:
raise RuntimeError('error: the following arguments are required: -u/--user or -r/--repo')
# 判断询问
if args.user and args.repo:
res = self.data.get_user_repo(args.user, args.repo, args.event)
elif args.user:
res = self.data.get_user(args.user, args.event)
else:
res = self.data.get_repo(args.repo, args.event)
return res
if __name__ == '__main__':
a = Run()
print(a.analyse())
单元测试
单元测试的unittest使用代码
import unittest
import os
from GHAnalysis import Data
class TestGHA(unittest.TestCase):
def setUp(self):
self.data = Data()
self.assertIsInstance(self.data, Data)
def tearDown(self):
pass
def test_init(self):
self.data.init('./data')
file_exist = all((os.path.exists(f'{i}.json') for i in range(1, 3)))
self.assertTrue(file_exist)
def test_user(self):
self.data.load()
num = self.data._user.get('waleko', {}).get('PushEvent', 0)
self.assertEqual(num, 2)
def test_repo(self):
self.data.load()
num = self.data._repo.get('katzer/cordova-plugin-background-mode', {}).get('PushEvent', 0)
self.assertEqual(num, 0)
def test_user_repo(self):
self.data.load()
num = self.data._user_repo.get('cdupuis', {}).get('atomist/automation-client', {}).get('PushEvent', 0)
self.assertEqual(num, 1)
if __name__ == '__main__':
unittest.main()
同时使用了fork库中的run.bat文件,所得结果相同
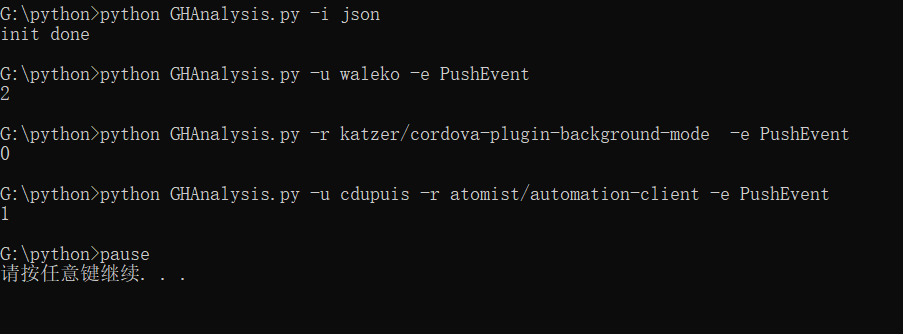
单元测试覆盖率优化
使用coverage得到覆盖率

性能优化
对面目前已经了解并运用到的优化:
- 正则表达式的匹配优化
- 对于冗余数据的不处理
了解但未实现的优化:
- 多进程优化
(听说简单多进程跑的更久了)
代码规范链接
总结
个人小结
对于这次作业对于我来说应该是非非非常难
首先是没有任何开发经验对于这些参数和读取完全不懂
从最开始时的无从下手,盲目学习各种报错逐渐转至正轨
关键还是在于询问有过经验的大佬,事实证明老师存在的重要性
同时意识到学习这些语言和开发环境配置的重要性
对于成为一个真正的程序员,我还有很多东西要学习
学习到的内容
- 先按要求分析任务
- 事先规划好具体实践
- 代码风格规范很重要
- 敢于询问能人能让你事半功倍