一、简单描述表结构,字段类型
desc tabl_name;
显示表结构,字段类型,主键,是否为空等属性,但不显示外键。
二、查询表中列的注释信息
select * from information_schema.columns where table_schema = 'db' #表所在数据库 and table_name = 'tablename' ; #你要查的表
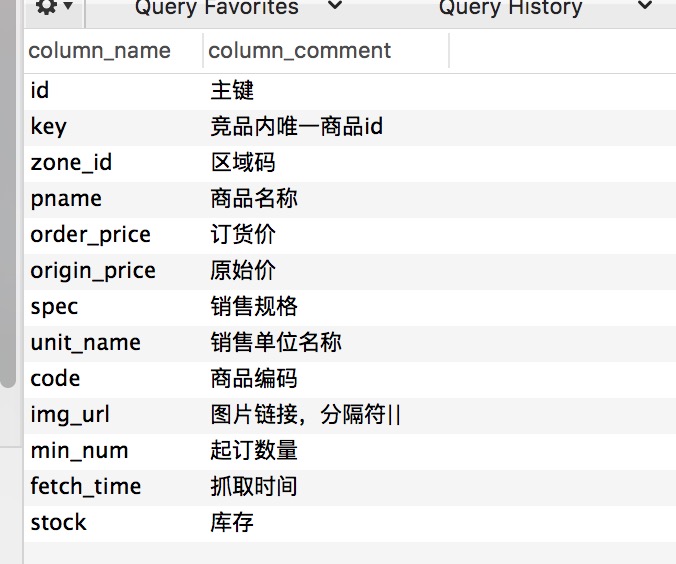
三、只查询列名和注释 select column_name, column_comment from information_schema.columns where table_schema ='db' and table_name = 'tablename' ;
例如:
可以自动选择你需要信息
三、只查询列名和注释 select column_name, column_comment from information_schema.columns where table_schema ='db' and table_name = 'tablename' ;
例如:
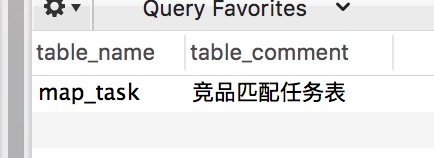
四、#查看表的注释 select table_name,table_comment from information_schema.tables where table_schema = 'db' and table_name ='tablename'
例如:
五、查看表生成的DDL
show create table table_name;
例如:

这个命令虽然显示起来不是太容易看, 这个不是问题可以用G来结尾,使得结果容易阅读;该命令把创建表的DDL显示出来,于是表结构、类型,外键,备注全部显示出来了。
我比较喜欢这个命令:输入简单,显示结果全面。
补充一些可能用到的命令:
建表命令: CREATE TABLE `t_sold_order` ( `id` int(11) NOT NULL AUTO_INCREMENT, `dt` date DEFAULT NULL COMMENT '日期', `hour` tinyint(2) DEFAULT '0' COMMENT '小时', `hour_order` int(11) DEFAULT '0' COMMENT '小时订单数', `total_order` int(11) DEFAULT '0' COMMENT '总的订单数', `prediction` int(11) DEFAULT '0' COMMENT '预测订单数', PRIMARY KEY (`id`), UNIQUE KEY `dt_hour` (`dt`,`hour`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='实时订单数'
表操作命令: 复制表结构:create table table1 like table; 复制数据:insert into table1 select * from table
机器授权: grant select on *.* to 'reader'@'%' identified by '123456' WITH GRANT OPTION flush privileges
查询数据直接插入 insert into t_visual_user_domain(`user_id`,`domain`,`group`) select id,'www.baidu.com' as domain,`group` from t_visual_user;
修改表结构 alter table competitor_goods add sku_id bigint(20) unsigned DEFAULT NULL COMMENT '商品销售码';
查询user表中,user_name字段值重复的数据及重复次数
select user_name,count(*) as count from user group by user_name having count>1;
1.添加PRIMARY KEY(主键索引)
mysql>ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
2.添加UNIQUE(唯一索引)
mysql>ALTER TABLE `table_name` ADD UNIQUE (
`column`
)
3.添加INDEX(普通索引)
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
4.添加FULLTEXT(全文索引)
mysql>ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
5.添加多列索引
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
2. 创建索引
在执行CREATE TABLE语句时可以创建索引,也可以单独用CREATE INDEX或ALTER TABLE来为表增加索引。
1.ALTER TABLE
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
|
1
2
3
|
ALTER TABLE table_name ADD INDEX index_name (column_list)ALTER TABLE table_name ADD UNIQUE (column_list)ALTER TABLE table_name ADD PRIMARY KEY (column_list) |
其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。索引名index_name可选,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。
2.CREATE INDEX
CREATE INDEX可对表增加普通索引或UNIQUE索引。
|
1
2
|
CREATE INDEX index_name ON table_name (column_list)CREATE UNIQUE INDEX index_name ON table_name (column_list) |
table_name、index_name和column_list具有与ALTER TABLE语句中相同的含义,索引名不可选。另外,不能用CREATE INDEX语句创建PRIMARY KEY索引。
3.索引类型
在创建索引时,可以规定索引能否包含重复值。如果不包含,则索引应该创建为PRIMARY KEY或UNIQUE索引。对于单列惟一性索引,这保证单列不包含重复的值。对于多列惟一性索引,保证多个值的组合不重复。
PRIMARY KEY索引和UNIQUE索引非常类似。事实上,PRIMARY KEY索引仅是一个具有名称PRIMARY的UNIQUE索引。这表示一个表只能包含一个PRIMARY KEY,因为一个表中不可能具有两个同名的索引。
下面的SQL语句对students表在sid上添加PRIMARY KEY索引。
4. 删除索引
可利用ALTER TABLE或DROP INDEX语句来删除索引。类似于CREATE INDEX语句,DROP INDEX可以在ALTER TABLE内部作为一条语句处理,语法如下。
|
1
2
3
|
DROP INDEX index_name ON talbe_nameALTER TABLE table_name DROP INDEX index_nameALTER TABLE table_name DROP PRIMARY KEY |
其中,前两条语句是等价的,删除掉table_name中的索引index_name。 第3条语句只在删除PRIMARY KEY索引时使用,因为一个表只可能有一个PRIMARY KEY索引,因此不需要指定索引名。如果没有创建PRIMARY KEY索引,但表具有一个或多个UNIQUE索引,则MySQL将删除第一个UNIQUE索引。 如果从表中删除了某列,则索引会受到影响。对于多列组合的索引,如果删除其中的某列,则该列也会从索引中删除。如果删除组成索引的所有列,则整个索引将被删除。
5.查看索引
|
1
2
|
mysql> show index from tblname;mysql> show keys from tblname; |
· Table 表的名称。 · Non_unique 如果索引不能包括重复词,则为0。如果可以,则为1。 · Key_name 索引的名称。 · Seq_in_index 索引中的列序列号,从1开始。 · Column_name 列名称。 · Collation 列以什么方式存储在索引中。在MySQL中,有值‘A'(升序)或NULL(无分类)。 · Cardinality 索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机会就越大。 · Sub_part 如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。 · Packed 指示关键字如何被压缩。如果没有被压缩,则为NULL。 · Null 如果列含有NULL,则含有YES。如果没有,则该列含有NO。 · Index_type 用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。 · Comment
SELECT * FROM table a LEFT JOIN (SELECT key,count(*) as c FROM table GROUP BY key ) b on a.key=b.key ORDER BY c desc