这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解。
第一步.随机生成质心
由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给定两个质心,我们这个算法的目的就是将这一堆点根据它们自身的坐标特征分为两类,因此选取了两个质心,什么时候这一堆点能够根据这两个质心分为两堆就对了。如下图所示:
第二步.根据距离进行分类
红色和蓝色的点代表了我们随机选取的质心。既然我们要让这一堆点的分为两堆,且让分好的每一堆点离其质心最近的话,我们首先先求出每一个点离质心的距离。假如说有一个点离红色的质心比例蓝色的质心更近,那么我们则将这个点归类为红色质心这一类,反之则归于蓝色质心这一类,如图所示: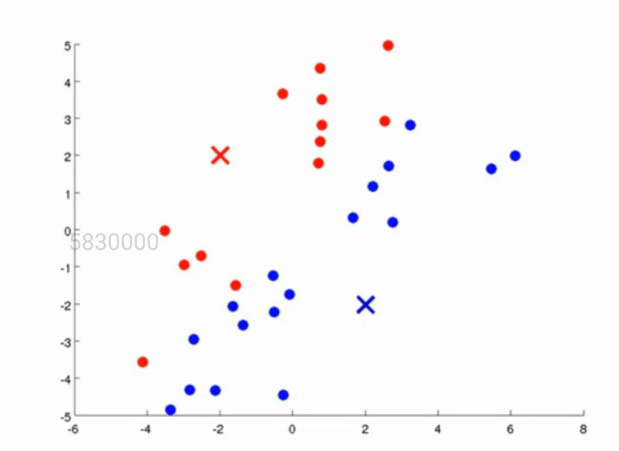
第三步.求出同一类点的均值,更新质心位置
在这一步当中,我们将同一类点的xy的值进行平均,求出所有点之和的平均值,这个值(x,y)则是我们新的质心的位置,如图所示:
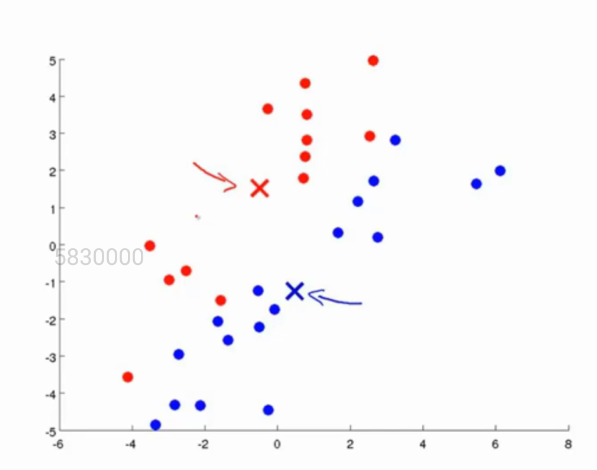
我们可以看到,质心的位置已经发生了改变。
第四步.重复第二步,第三步
我们重复第二步和第三部的操作,不断求出点对质心的最小值之后进行分类,分类之后再更新质心的位置,直到得到迭代次数的上限(这个迭代次数是可以我们自己设定的,比如10000次),或者在做了n次迭代之后,最后两次迭代质心的位置已经保持不变,如下图所示:

这个时候我们就将这一堆点按照它们的特征在没有监督的条件下,分成了两类了!!
五.如果面对多个特征确定的一个点的情况,又该如何实现聚类呢?
首先我们引入一个概念,那就是欧式距离,欧式距离是这样定义的,很容易理解:

很显然,欧式距离d(xi,xj)等于我们每一个点的特征去减去另一个点在该维度下的距离的平方和再开根号,十分容易理解。
我们也可以用另一种方式来理解kmeans算法,那就是使某一个点的和另一些点的方差做到最小则实现了聚类,如下图所示:
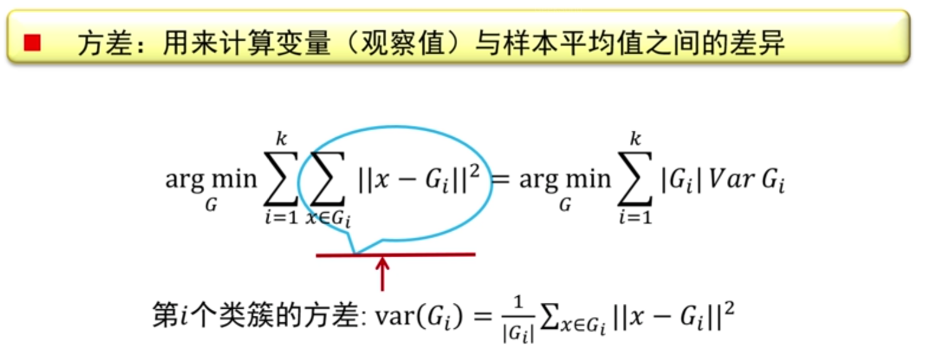
得解,有问题可以在评论区留言!