验证码的识别
主要分成四个部分:验证码的生成、将生成的图片制作成tfrecord文件、训练识别模型、测试模型
使用pyCharm作为编译器。本文先介绍前两个部分
验证码的识别有两种方法:
验证码识别方法一:
把标签转为向量,向量长度为40。(4位数字验证码)
例如有一个验证码为0782,
它的标签转为长度为40的向量。采用one-hot编码。1000000000 0000000100 0000000010 0010000000
其实就是把验证码作为索引值。数字存在,就将该位置的数值置为1
验证码识别方法二:
拆分为4个标签
例如有一个验证码为0782,
Label0:1000000000
Label1:0000000100
Label2:0000000010
Label3:0010000000
可以使用多任务学习
先介绍识别方法二,采用多任务学习,联合训练,将一个标签拆成4个
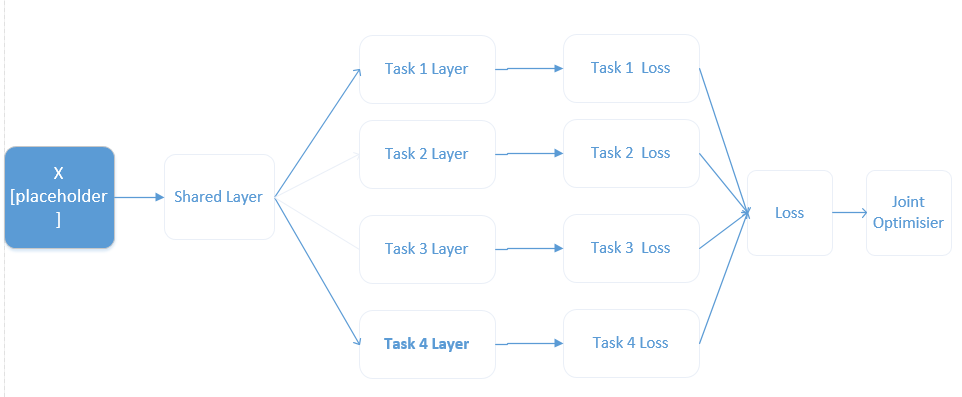
其中X是输入,Shared Layer就是一些卷积与池化操作,Task1-4对应四个标签,产生四个loss,将四个loss求和得总的loss,用优化器优化总的loss,从而降低每个标签产生的loss。
一、验证码的生成
# 验证码生成库 from captcha.image import ImageCaptcha import numpy as py # 处理图像的包 from PIL import Image import random import sys number = ['0','1','2','3','4','5','6','7','8','9'] # alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'] # ALPHABET = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'] def random_captcha_text(char_set=number, captcha_size=4): # 验证码列表 captcha_text = [] for i in range(captcha_size): # 随机选择 c = random.choice(char_set) # 加入验证码列表 captcha_text.append(c) return captcha_text # 生成字符对应的验证码 def gen_captcha_text_and_image(): image = ImageCaptcha() # 获得随机生成的验证码 captcha_text = random_captcha_text() # 把验证码列表转化为字符串 captcha_text = ''.join(captcha_text) # 根据字符串生成验证码 captcha = image.generate(captcha_text) image.write(captcha_text, 'captcha/images/' + captcha_text + '.jpg') # 写到文件 # 0000~9999总共10000,但是数量少于10000,因为重名 num = 10000 if __name__ == '__main__': for i in range(num): gen_captcha_text_and_image() sys.stdout.write(' >> Creating image %d/%d' % (i+1, num)) sys.stdout.flush() sys.stdout.write(' ') sys.stdout.flush() print("生成完毕")
使用四位数字验证码,当然也可以加入大、小写字母。四位字母有10000种可能。0000~9999,但是生成的图片是少于10000张的,因为有重名图片
生成的图片如下:

其中每张图片的label就是其中的数字。如图中的图片label为0000,其名称为0000.jpg
二、将生成的图片制作成tfrecord文件
import tensorflow as tf import os import random import math import sys from PIL import Image import numpy as np # 验证集的数量 _NUM_TEST = 500 # 随机种子 _RANDOM_SEED = 0 # 数据集路径 DATASET_DIR = "F:/PyCharm-projects/第十周/captcha/images/" # tfrecord文件存放路径 TFRECORD_DIR = "F:/PyCharm-projects/第十周" # 判断tfrecord文件是否存在 def _dataset_exists(dataset_dir): for split_name in ['train', 'name']: output_filename = os.path.join(dataset_dir, split_name + '.tfrecords') if not tf.gfile.Exists(output_filename): return False return True # 获取验证码所有图片 def _get_filenames_and_classes(dataset_dir): photo_filenames = [] for filename in os.listdir(dataset_dir): # 获取文件路径 path = os.path.join(dataset_dir, filename) photo_filenames.append(path) return photo_filenames def int64_feature(values): if not isinstance(values, (tuple, list)): values = [values] return tf.train.Feature(int64_list=tf.train.Int64List(value=values)) def bytes_feature(values): return tf.train.Feature(bytes_list=tf.train.BytesList(value=[values])) def image_to_tfexample(image_data, label0, label1, label2, label3): return tf.train.Example(features=tf.train.Features(feature={ 'image':bytes_feature(image_data), 'label0':int64_feature(label0), 'label1': int64_feature(label1), 'label2': int64_feature(label2), 'label3': int64_feature(label3), })) # 把数据转化为tfrecord格式 def _convert_dataset(split_name, filenames,dataset_dir): assert split_name in ['train', 'test'] with tf.Session() as sess: # 定义tfrecord问津的路径+名字 output_filename = os.path.join(TFRECORD_DIR, split_name + '.tfrecords') with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer: for i, filename in enumerate(filenames): try: sys.stdout.write(' >> Converting image %d/%d' % (i+1, len(filenames))) sys.stdout.flush() # 读取图片 image_data = Image.open(filename) # 根据模型的结构resize image_data = image_data.resize((224, 224)) # 由于验证码是彩色的,但是我们识别验证码并不需要彩色,灰度图就可以。这样可以减少计算量 image_data = np.array(image_data.convert('L')) # 将图片转化为bytes image_data = image_data.tobytes() # 获取level 验证码的前4位就是它的level labels = filename.split('/')[-1][0:4] num_labels = [] for j in range(4): num_labels.append(int(labels[j])) # 生成protocol数据类型 example = image_to_tfexample(image_data, num_labels[0], num_labels[1], num_labels[2], num_labels[3]) tfrecord_writer.write(example.SerializeToString()) except IOError as e: print('Cloud not read:', filename) print('Error:', e) print('Skip it ') sys.stdout.write(' ') sys.stdout.flush() # 判断tfrecord文件是否存在 if _dataset_exists(TFRECORD_DIR): print('tfrecord文件已存在') else: # 获得所有图片 photo_filenames = _get_filenames_and_classes(DATASET_DIR) # 把数据切分为训练集和测试集,并打乱。我们在后面还是会打乱的。这里不打乱也可以 random.seed(_RANDOM_SEED) random.shuffle(photo_filenames) training_filenames = photo_filenames[_NUM_TEST:] testing_filenames = photo_filenames[:_NUM_TEST] # 数据转换 _convert_dataset('train', training_filenames, DATASET_DIR) _convert_dataset('test', testing_filenames, DATASET_DIR) print('生成tfrecord文件')
制作test.tfrecords、train.tfrecords。选取500张图片作为测试集