背景
公司的物流业务系统目前实现了使用storm集群进行过门事件的实时计算处理,但是还有一个需求,我们需要存储每个标签上传的每条明细数据,然后进行定期的标签报表统计,这个是目前的实时计算框架无法满足的,需要考虑离线存储和计算引擎。
标签的数据量是巨大的,此时存储在mysql中是不合适的,所以我们考虑了分布式存储系统HDFS。目前考虑的架构是,把每条明细数据存储到HDFS中,利用Hive或者其他类SQL的解析引擎,定期进行离线统计计算。
查找相关资料后,我下载了深入理解Haddoop这本书,从大数据的一些基础原理开始调研,这一系列的笔记就是调研笔记。
系列文章:
深入理解Hadoop
安装部署-非CDH版本
总则:按照官网的文档一步一步部署即可,但是官网的太过简略,下面会补充一些内容。
前置准备
部署前需要做一些前置准备,需要jdk和ssh。
JDK
Hadoop2.7以上的需要JDK7,Hadoop之前的版本使用JDK6即可,使用OpenJDK 或者 Oracle (HotSpot)'s JDK/JRE都可以 。
安装:sudo apt install openjdk-8-jdk-headless(Ubuntu下 )
ssh
SSH本质是一种远程登陆的方式。我们可以通过两种方式使用SSH,一种是直接 ssh 用户名@主机 输入用户的密码即可登录,但这种方式不够安全,需要把自己的密码告知对方;另一种是在被远程的机器上建立一把锁,提供给需要远程登陆的人一把钥匙,如果不想让其登录,把锁删了即可。
安装:SSH的安装及使用
下面介绍通过第二种方式登录需要做的设置
首先需要在被登录的主机上,使用下面命令生成公钥和私钥,第一个等待输入直接输入直接键入enter继续,第二个等待输入,需要输入一个访问密码,第三个等待输入也输入刚才相同的密码。
ging@ubuntu:~$ ssh-keygen
这个命令会在 ~/.ssh目录下生成两个文件:id_rsa是私钥,id_rsa.pub是公钥。
ging@ubuntu:~$ ls -l ~/.ssh
total 12
-rw------- 1 ging ging 2635 Aug 25 23:27 id_rsa
-rw-r--r-- 1 ging ging 565 Aug 25 23:27 id_rsa.pub
然后输入下面的命令,把本地的ssh公钥文件,复制到另外主机的 ~/.ssh文件夹中,中间需要输入对应主机用户的密码(因为这里我就一台虚拟机,所以模拟自己登录自己的操作,直接复制给自己)
ging@ubuntu:~$ ssh-copy-id ging@127.0.0.1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/ging/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
ging@127.0.0.1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'ging@127.0.0.1'"
and check to make sure that only the key(s) you wanted were added.
这个命令后,会发现~/.ssh文件夹下出现了一个新的文件 authorized_keys
ging@ubuntu:~$ ls -l ~/.ssh
total 16
-rw-rw-r-- 1 ging ging 565 Aug 26 00:01 authorized_keys
-rw------- 1 ging ging 2655 Aug 26 00:00 id_rsa
-rw-r--r-- 1 ging ging 565 Aug 26 00:00 id_rsa.pub
远程登陆时,会提示需要输入刚才第二步设置的私钥文件的访问密码,如果成功即可远程登陆;如果连续三次输入失败,会要求输入登录用户的本地密码,正确也可以登录
ging@ubuntu:~$ ssh ging@127.0.0.1
Enter passphrase for key '/home/ging/.ssh/id_rsa':
Enter passphrase for key '/home/ging/.ssh/id_rsa':
Enter passphrase for key '/home/ging/.ssh/id_rsa':
ging@127.0.0.1's password:
Welcome to Ubuntu 20.04 LTS (GNU/Linux 5.4.0-42-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
221 updates can be installed immediately.
0 of these updates are security updates.
To see these additional updates run: apt list --upgradable
Your Hardware Enablement Stack (HWE) is supported until April 2025.
Last login: Tue Aug 25 23:23:34 2020 from 127.0.0.1
如果不希望对方登录我们的主机,直接把 ~/.ssh文件夹删除即可,这样对方就只能使用我们的本地密码才能登录。
SSH的基本原理和使用介绍到这儿,接下来需要了解Hadoop集群需要的SSH配置
ssh Hadoop集群配置
Hadoop需要配置各个节点之间免密登录。
免密登录的操作步骤和上述的步骤类似,只不过在 ssh-keygen的步骤,不输入私钥文件的访问密码,三次等待输入都直接键入enter即可。
另外,需要在集群的各个主机中的每个~/.ssh/authorized_keys 文件中,都添加上其他主机的公钥,这样集群中的所有机器就可以互相免密访问了。
具体可以参考这个博客:Hadoop集群配置免密SSH登录方法
Hadoop安装部署
我这里部署的是2.10.0版本,百度网盘下载链接
链接:https://pan.baidu.com/s/1MHBPlf5lOnKK6MXOGl0PGA
提取码:fijb
注意:解压Hadoop的tar.gz这里略去不表,读者应该知道如何解压。
解压后,需要配置一下 etc/hadoop/hadoop-env.sh 这个脚本里面的java环境变量,在
export JAVA_HOME=${JAVA_HOME}
这行的上面直接加入下面的命令即可,其中,/usr/lib/jvm/java-8-openjdk-amd64是我本地jdk的路径
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
配置成功后,执行下面命令
其中,~/hadoop/hadoop-2.10.0/是我本地的hadoop的解压路径
ging@ubuntu:~/hadoop/hadoop-2.10.0$ ~/hadoop/hadoop-2.10.0/bin/hadoop
如果出现下面的文字,就配置完成了
ging@ubuntu:~/hadoop/hadoop-2.10.0$ ~/hadoop/hadoop-2.10.0/bin/hadoop
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
credential interact with credential providers
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
Most commands print help when invoked w/o parameters.
Hadoop的部署分为三种模式。
-
单机模式:只启动一个jvm进行MapResuce任务测试,没有守护进程的概念
-
伪分布式:所有的守护进程都运行在一个单节点上
-
完整分布式:守护进程运行在集群的不同节点上。
单机模式
操作完上面的步骤后,hadoop集群默认进入单机模式,官网文档中给出了一个测试jar包,指导我们如何测试,按照官网一步一步操作即可。
伪分布式
伪分布式部署介绍了两种方式,一种是不使用Yarn的MapReduce作业执行;另一种是把MR作业提交到Yarn框架执行。
这里跟着官方文档一步一步执行即可,需要注意一点:
官方文档中有个步骤
Browse the web interface for the NameNode; by default it is available at:
- NameNode -
http://localhost:9870/
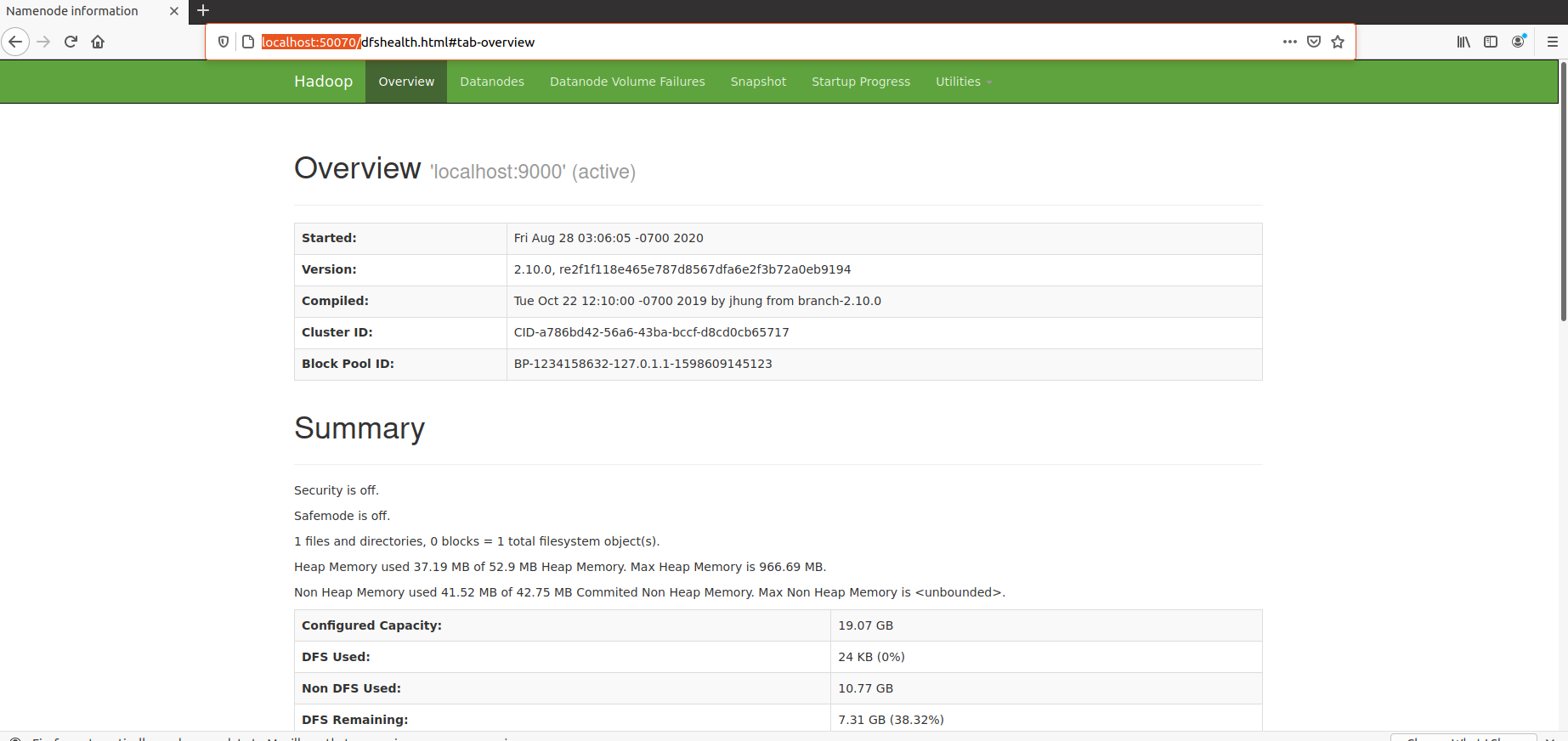
这里需要访问:http://localhost:50070/ 这个端口才可以。
访问成功后,界面显示如下:
注意:Yarn模式部署时,提交任务后,虚拟机卡住,只能强制关闭虚拟机。
初步怀疑虚拟机配置的资源数小于任务执行需要的资源数(cpu核数1核,内存2G),查阅相关资料后得知,需要修改yarn分配内存和cpu的相关参数,以匹配真实虚拟机的资源,防止分配的资源大于虚拟机的资源。
相关配置项如下(以虚拟机8G内存为例):
| Configuration File | Configuration Setting | Value Calculation | 8G VM (4G For MR) |
|---|---|---|---|
| yarn-site.xml | yarn.nodemanager.resource.memory-mb | = containers * RAM-per-container | 4096 |
| yarn-site.xml | yarn.scheduler.minimum-allocation-mb | = RAM-per-container | 1024 |
| yarn-site.xml | yarn.scheduler.maximum-allocation-mb | = containers * RAM-per-container | 4096 |
| mapred-site.xml | mapreduce.map.memory.mb | = RAM-per-container | 1024 |
| mapred-site.xml | mapreduce.reduce.memory.mb | = 2 * RAM-per-container | 2048 |
| mapred-site.xml | mapreduce.map.java.opts | = 0.8 * RAM-per-container | 819 |
| mapred-site.xml | mapreduce.reduce.java.opts | = 0.8 * 2 * RAM-per-container | 1638 |
相关项目解释参考这篇博文:Yarn 内存分配管理机制及相关参数配置
按照配置配置完成后,提交任务到Yarn,成功执行。
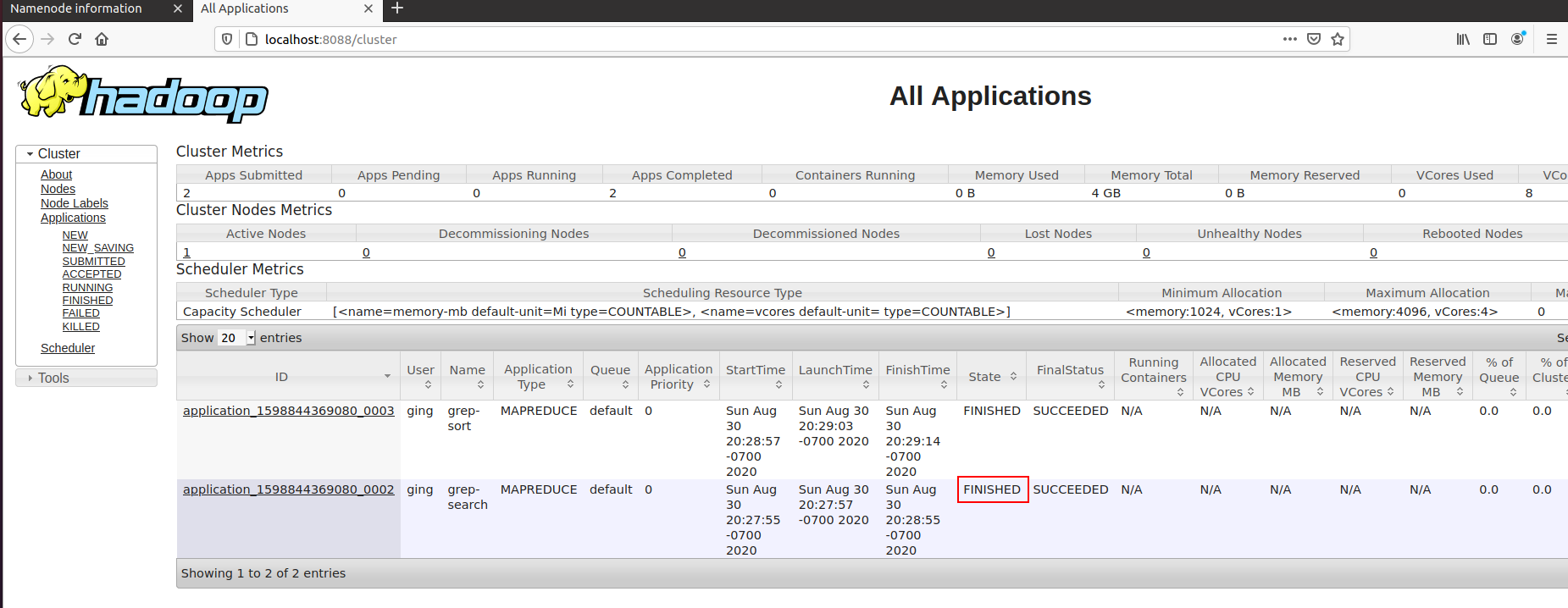
完整分布式
未完待续...