一、DataFrame的索引
1,选择列
1 import pandas as pd 2 import numpy as np 3 from pandas import Series, DataFrame 4 5 df = DataFrame(np.random.rand(12).reshape((3,4)), 6 index = ['one', 'two', 'three'], 7 columns= list('abcd') 8 ) 9 print(df) 10 type(df['a']) 11 df[['a','c']] # dataframe

注:df[ ]--选择列,整数可以选择行,但是不能单独选择,要用切片的方式如df[:2]
2,选择行
df1 = DataFrame(np.random.rand(12).reshape((3,4)), index = [3,2,1], columns= list('abcd') ) print(df1) df.loc['one'] # 单独的行,返回的也是一个Series对象 # df1.loc[0] # 整数的索引,只能是index 是默认的整数时 df.loc[['one','three','four']] # 多行,返回的也是一个Dataframe对象 df1.loc[2:1] # df.loc['two':'three'] # index 标签切片,闭区间 # df.loc[label] 主要是针对行索引,同时指出指定index,及默认的index


注:df.loc[ ]--按index选择行,字符串标签索引
3,另外一种索引方法
df.iloc[] 按照整数位置(从0到length-1)选择行
类似于list的索引,顺序就是dataframe的整数位置,从0开始算
1 print(df) 2 df.iloc[0] # 一行 3 # df.iloc[3] 不能超出索引的范围 4 df.iloc[[0,1]] # 选择多行,返回dataframe对象 5 6 df.iloc[[1,0]] # 选择的多行,顺序可变 7 df.iloc[::2]
4,布尔型索引
原理和Series原理相同
1 # df = df/10000 2 print(df) 3 b1 = df < 20 # 返回一个和df形状相同的布尔型 dataframe 4 df[b1] # 返回一个dataframe,所有数据,True返回原数据,False 返回NaN 5 6 b2 = df['a'] > 50 # 单列,就是Series 7 # print(b2, type(b2)) 8 df[b2] # 单列做判断,保留判断为True的行数据 9 10 # 多列做判断 11 b3 = df[['a', 'b']] > 50 # 返回一个布尔型的dataframe 12 print(b3) 13 print(df[b3]) # 返回形状相同的dataframe 为True位置返回数据,False和其他位置都返回NaN
5,多重索引,同时索引列和行
1 print(df) 2 df['a'].loc[['one','three']] 3 df[['b', 'c', 'd']].iloc[::2] 4 df[df['a']<50].iloc[0]
二、DataFrame的基本操作
1,数据查看和转置
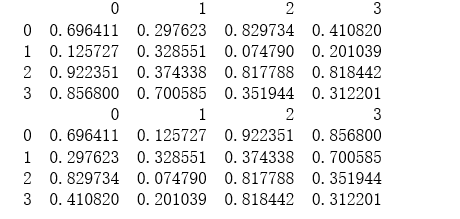
1 df = DataFrame(np.random.rand(16).reshape((4,4))) 2 df.head(2) 3 df.tail() 4 # .T 5 print(df) 6 print(df.T)
2,添加和修改
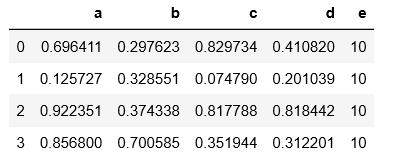
1 df.columns = list('abcd') 2 df['e'] = 10 # 指定添加一列,标量重复 3 df
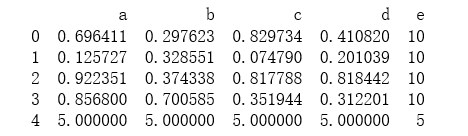
1 # 添加一行,df数据同上 2 df.loc[4]=5 3 print(df)
1 # 修改,df数据同上 2 df['e'] = 0 3 print(df)

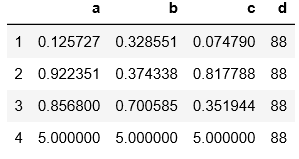
1 # 修改多列,df数据同上 2 df[['d','e']] = 88 3 print(df) 4 # 直接索引赋值

3,删除
1 # 删除一列 del df数据同上 2 del df['e'] 3 print(df)

1 # 删除的第二种方法 2 df.drop(0) # drop 默认会返回删除后的datafarme
1 # drop() axis=0 删除行 axis=1 删除列 2 df.drop('a', axis=1)
1 # drop 默认会返回一个新的值,设置 inplace=True修改原数据 2 df.drop(0,inplace=True)
3 df
4,对齐
1 df = DataFrame(np.arange(16).reshape((4,4)), columns=list('abcd')) 2 df1 = DataFrame(np.arange(9).reshape((3,3)), columns=list('cba')) 3 print(df) 4 print(df1) 5 # 按照行和列的标签自动对齐 6 df+df1


5,排序
1 df = DataFrame(np.random.randint(16,size=[4,4]), columns=list('abcd')) 2 df 3 # 按值排序 4 df.sort_values('b', ascending=False) # 按照列标签等于b的那一列的值进行排序,默认从小到大 ascending=True 默认,False降序 5 6 df.sort_values(['b','c']) # 联合


1 # 默认axis=0 ,就是要用列的值,去对行进行排序,所以第一个参数需要传入 列索引 2 # axis=1 ,就是用行的值,去对列进行排序,传入行索引 3 df.sort_values(2, axis=1)

1 # 按索引排序 2 df.index = [5,2,4,1] 3 df.columns = list('adce') 4 print(df) 5 6 df.sort_index(ascending=False) # 默认按行索引进行降序 ascending=False 降序 7 # axis=1 按列索引排序 8 df.sort_index(axis=1)
