一、为什么要集群?
1.JavaEE项目,如果部署在一台Tomcat上,所有的请求,都由这一台服务器处理,存在很大风险:
A:并发处理能力有限(一般单台服务器处理的并发量为250左右,超过250,可能会出现数据丢失,链接不稳定的情况)。因为单服务器的性能有限制。所以单台Tomcat的最大连接数有限制,
B:容错率低,一旦服务器故障,整个服务就无法访问了。
eBay于 1999年6月停机22小时的事故,中断了约230万的拍卖,使eBay的股票下降了9.2个百分点。
C:单台服务器计算能力低,无法完成复杂的海量数据计算。
提高CPU主频和总线带宽是最初提供计算机性能的主要手段。但是这一手段对系统性能的提供是有限的。接着人们通过增加CPU个数和内存容量来提高性能,于是出现了向量机,对称多处理机(SMP)等。但是当CPU的个数超过某一阈值,这些多处理机系统的可扩展性就变的极差。主要瓶颈在于CPU访问内存的带宽并不能随着CPU个数的增加而有效增长。与SMP相反,集群系统的性能随着CPU个数的增加几乎是线性变化的。
二、什么是集群
集群是是指将多台服务器集中在一起,每台服务器都实现相同的业务,做相同的事情。但是每台服务器并不是缺一不可,存在的作用主要是缓解并发压力和单点故障转移问题。可以利用一些廉价的符合工业标准的硬件构造高性能的系统。实现:高扩展、高性能、低成本、高可用!

2.1伸缩性(Scalability)
在一些大的系统中,预测最终用户的数量和行为是非常困难的,伸缩性是指系统适应不断增长的用户数的能力。提高这种并发会话能力的一种最直观的方式就增加资源(CPU,内存,硬盘等),集群是解决这个问题的另一种方式,它允许一组服务器组在一起,像单个服务器一样分担处理一个繁重的任务,我们只需要将新的服务器加入集群中即可,对于客户来看,服务无论从连续性还是性能上都几乎没有变化,好像系统在不知不觉中完成了升级
2.2高可用性(High availability)
单一服务器的解决方案并不是一个健壮方式,因为容易出现单点失效。像银行、账单处理这样一些关键的应用程序是不能容忍哪怕是几分钟的死机。它们需要这样一些服务在任何时间都可以访问并在可预期的合理的时间周期内有响应。高可用性集群的出现是为了使集群的整体服务尽可能可用,以便考虑计算硬件和软件的易错性。如果高可用性集群中的主节点发生了故障,那么这段时间内将由次节点代替它。次节点通常是主节点的镜像,所以当它代替主节点时,它可以完全接管其身份,并且因此使系统环境对于用户是一致的。
2.3负载均衡(Load balancing)
负载均衡集群为企业需求提供了更实用的系统。如名称所暗示的,该系统使负载可以在计算机集群中尽可能平均地分摊处理。该负载可能是需要均衡的应用程序处理负载或网络流量负载。这样的系统非常适合于运行同一组应用程序的大量用户。每个节点都可以处理一部分负载,并且可以在节点之间动态分配负载,以实现平衡。
2.4高性能 (High Performance )
通常,第一种涉及为集群开发并行编程应用程序,以解决复杂的科学问题。这是并行计算的基础,尽管它不使用专门的并行超级计算机,这种超级计算机内部由十至上万个独立处理器组成。但它却使用商业系统,如通过高速连接来链接的一组单处理器或双处理器 PC,并且在公共消息传递层上进行通信以运行并行应用程序。因此,您会常常听说又有一种便宜的 Linux 超级计算机问世了。但它实际是一个计算机集群,其处理能力与真的超级计算机相等
三、为什么要进行分布式
传统的项目中,我们将各个模块放在一个系统中,系统过于庞大,开发维护困难,各个功能模块之间的耦合度增高,无法针对单个模块进行优化,也无法进行水平扩展。

四、什么事分布式
分布式是指将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情。并且每台服务器都缺一不可,如果某台服务器故障,则网站部分功能缺失,或导致整体无法运行。存在的主要作用是大幅度的提高效率,缓解服务器的访问和存储压力。

注意:该图中最大特点是:每个Web服务器(Tomcat)程序都负责一个网站中不同的功能,缺一不可。如果某台服务器故障,则对应的网站功能缺失,也可以导致其依赖功能甚至全部功能都不能够使用。
五、分布式和集群的关系。
在开发中我们可以将分布式和集群分开吗?
针对这个问题,我们可以根据分布式的介绍看出,其主要的功能是用了将我们的系统模块化,将系统进行解耦的,方便我们的维护和开发的,但是其并不能解决我们的并发问题,也无法保证我们的系统在服务器宕机后的正常运转。
而集群呢?其恰好弥补了分布式的缺陷,集群,就是多个服务器处理相同的业务,这在一方面可以解决或者说改善我们系统的并发问题,一方面可以解决我们服务器如果出现一定数量的宕机后,系统仍然可以正常运转。
因此我说,分布式和集群式一堆好基友,谁也离不开谁。。。
六、事务处理
集群部署的是同一个服务,处理的数据还是同一个数据库,需要开启本地事务;
分布式事务需要用到事务补偿机制(度娘提供)
方式一、
1、微服务-中间件-消息组件
生产者
发出带流水号(唯一)订单消息。调用消息组件。
消息组件
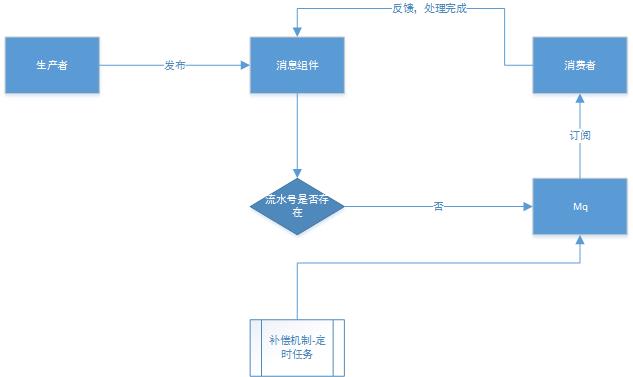
- 消息组件-消息表:id为生产者的流水号。(具备幂等性)
- 生产者发布请求,查询消息表,判断流水号是否存在,存在,不发送到mq;不存在:发送到mq,消息表插入记录,消息状态为“已发送”。
- 收到消费者反馈,处理完成请求。将消息置为“处理成功”。
- 补偿机制-定时任务,不仅仅要mq自身的重试机制,还要有任务补偿机制,即扫描消息表,状态=“已发送”且发送时间>当前时间-n(n不为0)的数据进行重试,要有时间间隔。
消费者
收到mq消息,调用消息组件。
方式二、
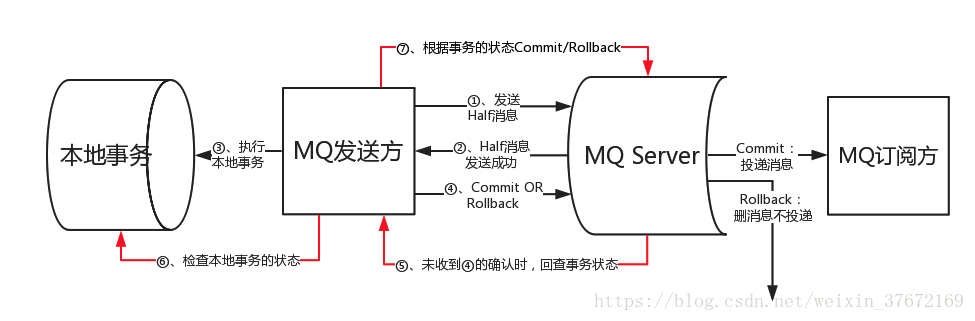
1、MQ发送方发送远程事务消息到MQ Server;
2、MQ Server给予响应, 表明事务消息已成功到达MQ Server.
3、MQ发送方Commit本地事务.
4、若本地事务Commit成功, 则通知MQ Server允许对应事务消息被消费; 若本地事务失败, 则通知MQ Server对应事务消息应被丢弃.
5、若MQ发送方超时未对MQ Server作出本地事务执行状态的反馈, 那么需要MQ Servfer向MQ发送方主动回查事务状态, 以决定事务消息是否能被消费.
6、当得知本地事务执行成功时, MQ Server允许MQ订阅方消费本条事务消息.
之前写服务的时候没有用2-pc,用的还是异步消息的事务补偿机制,但没有上面的这么复杂,首先 A->B, A→C结合一些A的本地DB操作被包裹进大的事务里,若C调用失败触发回滚,在捕获C调用失败的异常时往kafka写入消息通知给B回滚,A不会直接调用B的接口去手动回滚因为这个动作耗时且可能失败,而送入kafka让B的消费者线程来消费可以保证多次重试以及日志准确记录。
方式三、
基于事务消息的最终一致性
模型
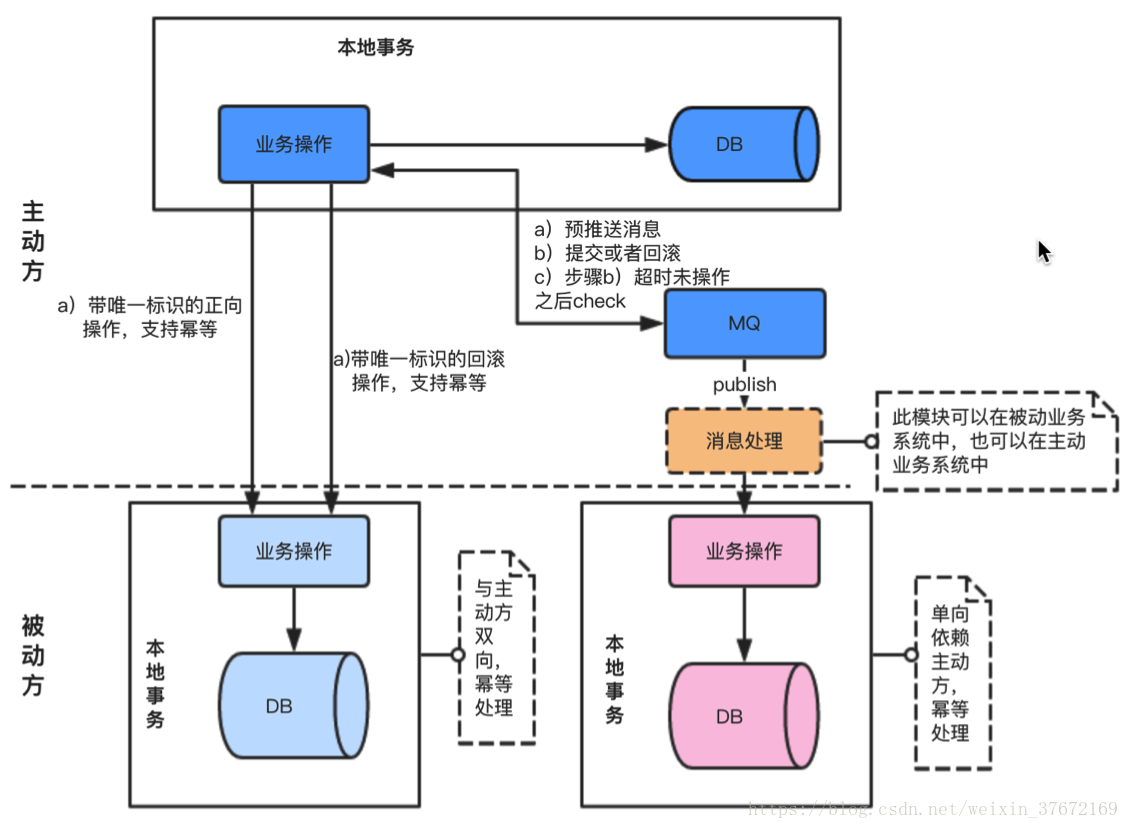
由多个独立的本地事务和事务消息实现最终一 致性,事务消息保证成功的情况下投递,失败时不投递,超时未知的情况下check,具体的实现方式不固定,常用的策略是一个唯一业务标识和幂等操作,下图是基于事务 MQ 的最终一致性常用模型:
优缺点
1)优点
性能好,把全局事务拆分成多个本地事务,对资源的锁定只是一个本地事务的时间,通过在数据库外部实现事务机制达到了最终一致性
对SOA/微服务的支持友好
2)缺点
对应用的侵入大,需要应用自身根据业务实现最终一致性逻辑,在应用系统中实现事务检查与回滚的细节
存在中间不一致状态
其实补偿机制都是自己根据业务设计自己的,只要实现数据的一致性就行了,这几个觉得讲的不错记一下