Vuzzer 是由计算机科学机构 Vrije Universiteit Amsterdam、Amsterdam Department of Informatics 以及 International Institute of Information Technology, Hyderabad 共同开发的工具。
项目来源 : https://github.com/vusec/vuzzer
参考资料 :《VUzzer: Application-aware Evolutionary Fuzzing》
VUzzer 是什么?
为何选择 VUzzer
自动漏洞测试技术当前主要为基于fuzzing的有结果反馈能力的AFL与使用符号执行的driller等。
符号执行(symbolic execution)的一大优势在于发现尽可能多的路径,实现高覆盖率,但其消耗大量运行空间的方式使其难以扩展,而vuzzer能在不使用符号执行的情况下,对AFL效率进行大幅的提升。
VUzzer使用应用感知的”智能“变异策略——基于数据流和控制流,使用轻量静态分析与动态分析,通过结果反馈和优化输入的生成过程以求产生更优秀更少的测试输入,达到加快挖掘效率,增加挖掘深度的目的。
案例
用以下简单的情况进行对比
...
read(fd,buf,size);
if(buf[5] == 0xD8 && buf[4] == 0xFF){
//在汇编代码中以CMP形式出现,同时应注意其检查顺序
if(...)
//if的嵌套
...some useful code containg bug...
}else{
...
EXIT_ERROR("Invalid file
");
}
输入buf中的buf[4],buf[5]包含着被污染的数据(tained data)。
对于工具AFL—-对程序进行黑盒测试的fuzzer:
1.必须通过变异输入完全猜对两字节为FFD8才能进入深层代码
2.必须找对该在buf[4],buf[5]的位置进行变异
3.作为一基于覆盖率的fuzzer,AFL追求发现新路径,当AFL没能通过if而进入了else,对其来说仍然发现了新路径,将会以这个进入else的输入作为新的反馈。可能致使AFL过分轻视if分支,这种情况在嵌套判断语句中会更加明显。
这将会使fuzzer浪费大量时间与运算资源,在else和其下的错误处理中。
而对于VUzzer:
1.在静态分析阶段,vuzzer会通过在程序的汇编码中寻找cmp指令集相关命令,将if语句中的判断值提取出来存储在Lcmp当中,找到这些magic bytes值是什么(如 FFD8)
2.而在动态分析中,通过不断迭代,将Lcmp 与取地址值类操作Llea中信息与种子文件输入和新生成输入进行类型匹配等,找到这些magic bytes在输入中的可能位置,更精准的进行变异
3.而对于嵌套判断语句引起的深度代码不易发现的问题,VUzzer的基本块(Basic Block)权重管理将会很好的解决这个问题
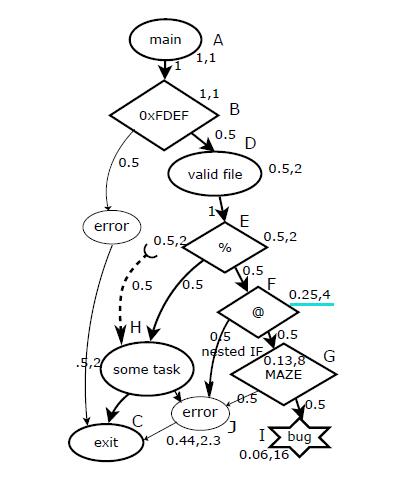
对于应用反汇编后,汇编码中的每一个基本块(Basic Block),都有一个权重值,由于VUzzer追求更深层的代码,所以对可能执行到概率越小的块,他的权重值要更高,若从main到达块A的概率为P,其权重就为1/p。
但如何做到这一点?
以上图为例如果说有main开始,那么执行到main的概率就是1,main后有两个可能方向,那么就划分两者概率均为0.5,依次向下。
例如$H{概率}=E*0.5+P{外来}(0.5)*0.5=0.5$
则$H{权重}=1/H{概率}=2$
例图中蓝线所表示为F块触发概率为0.25,权重为倒数4
特别的,对于很小可能含有bug的错误处理块其权重为1(通过动态分析才能发现错误处理块)
由此有了,解决深层代码被隐藏的方法。
VUzzer 概述
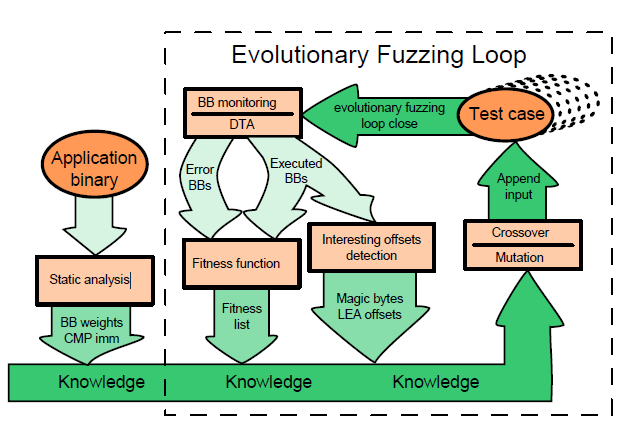
vuzzer顶层图(具体术语参见下表)

静态分析阶段
1).在汇编码中进行,找出基本块,计算块权重并将块重量存入
LBB2).扫描编码中的cmp指令相关的立即数,存入
Limm(包含如上文中的0xFF,0xD8等)
动态分析阶段—–每一loop为一代
1).对种子文件(使用者提供的基础输入)进行DTA分析,捕获输入中的共同特征,以期找到magic bytes的位置与错误处理块,使新产生的孩子测试输入,不会陷于外围的判断和出错处理
2).对于发现了新的基本块的输入用例,进行DTA分析,追踪输入的值在程序中的运行,监测数据流特征,以推断输入的结构
3).适应度计算
适应度是对每一个输入而言的,适应度越高,代表其可进入更多的块,更深的块(权重更大的块),是更有价值的输入。
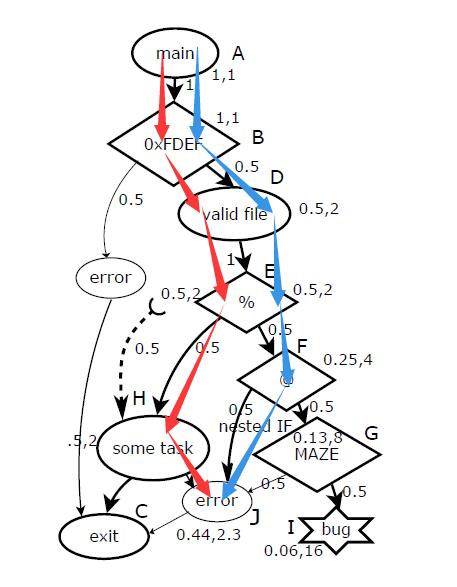
再结合此图,对于每一个输入,运行中必会通过一条路径,输入A的适应度就是改路径所经过块的权重和
例如路径1(红色)2(蓝色):
$p1=A-B-D-E-H-J=1+1+2+2+2-1=7$
$p2=A-B-D-E-F-J=1+1+2+2+4-1=9$
则
$适应度{P2}>适应度{P1}$
输入2将更被看重,更多的参与到生成下一代去,具体做法是将输入按适应度呈顺序排列存入Lfit,再选取使用时,使用前n%的做法
4).生成下一代
其变异来源是被称为vuzzer下的ROOT set的输入集合,其中包含种子文件,tainted input, Lfit中的前n%。

典型的子测试用例演化算法
vuzzer采用典型演化算法步骤并优化
INITIALIZE population with seed inputs
repeat
SELECT1 parents
RECOMBINE parents to generate children
MUTATE parents/children
EVALUATE new candidates with FITNESS function
SELECT2 fittest candidates for the next population
until TERMINATION CONDITION is met //迭代次数超过限制 或 触发crash
return BEST Solution| 变异策略 | 具体步骤 || —– | —————- || 交叉 | 取一个偏移量,而后使两半互换 || 删去 | 删除字节 || 替换与插入 | 在特定的位置改变或插入特定的字节 |
特定的字节 ,是通过从程序的汇编码中cmp指令集族的代码中取出立即数置入Limm,并从Limm中取出。生成为不同长度的新字节串得到的
特定的位置 ,是通过从父测试用例集中,寻找其偏移量,并在此之上变异引起的
产生孩子测试用例后由此再进行一轮,在达到迭代上限或发现bug前,循环往复
vuzzer安装
这里结合官方安装说明 进行讲解:
需求条件:
环境:
32位Linux系统,因vuzzer作者声明仅在Ubuntu14.04版本中完成测试,所以建议使用该版本系统。
vuzzer_github 在本地目录准备源码
$ git clone https://github.com/vusec/vuzzer
C++11 编程以及 Unix 开发利用 (例如: GNU Make).
gcc4.8开始默认支持c++11
Ubuntu14.04当前自带版本为4.8.*的gcc,g++,支持c++11。
通过以下命令可以检查当前版本
$ gcc --version
$ g++ --version
若不合适可通过过以下命令安装该版本
$ sudo apt-get install gcc-4.8
$ sudo apt-get install g++-4.8
准备Intel Pin:Intel Pin 的较新版本 (>=2.13) 。必须在 VUzzer 顶级目录中的 pin 目录中保存框架。
PIN的下载可以通过以下两个方法:
(1).(推荐)使用vuzzer自带pin配置脚本,自动下载合适版本pin并配置,在vuzzer根目录输入以下命令,使用此方法pin会被下载至vuzzer/support/
make -C support -f makefile.pin
(2) . 在官方网站 Pin – A Binary Instrumentation Tool 下载合适版本pin工具(查看release note寻找对应版本)
后在vuzzer目录下建立一个到pin的链接:
$ cd vuzzer$ ln -s /path-to-pin-home pin 其中/path-to-pin-home是Pin的根目录,不是可执行文件
利用 Python 2.7 ,使用 Turtle 语法将源代码转换成 PROV 形式:
Ubuntu14.04 带有 python2.7
通过以下命令检查
$ python --version如果未安装执行以下命令安装
$ sudo apt-get install python-2.7安装EWAGBoolArray:只需将 headers 文件 复制粘贴到 /usr/include 文件夹中即可安装:
完成该步骤仅需将指定头文件下载放置到/usr/include目录下
具体为下载headers file所指向链接下4个.h格式文件。
后通过以下命令拷贝头文件,其中headers为包含4个头文件的文件夹
$ sudo cp headers/* /usr/include/安装 BitMagic:
输入以下命令安装 BitMagic
$ sudo apt-get install bmagic要求修改过的libdft,在当前vuzzer目录的support下已有该版本,已准备好编译,无需操作
BitVector module for python.点击bitvector下载
官方网站:https://engineering.purdue.edu/kak/dist/BitVector-2.2.html
安装通过以下命令:在解压后的BitVector目录下
$ sudo python setup.py install
环境准备结束
安装
First do cd vuzzer and then
export PIN_ROOT=$(pwd)/pin
设置PIN_ROOT,由于当前目录(pwd)下的pin根目录链接,该命令将使PIN_ROOT指向可执行文件pin
编译libdft,在vuzzer/support/libdft/src目录下
make clean清空make文件,再回到vuzzer目录下执行
make support-libdft编译libdft
make编译vuzzer
make -f mymakefile
(截图未做make clean,且已安装过,仅供参考)
安装完成
vuzzer基础参数说明
位于根目录下的
runfuzzer.py是启动vuzzer的入口
config.py是包含vuzzer代数上限等设置的配置文件
$ python runfuzzer.py -h
usage: runfuzzer.py [-h] -s SUT -i INPUTD -w WEIGHT -n NAME [-l LIBNUM] -o OFFSETS [-b LIBNAME]
这里假定以tiff2pdf(图片格式转换工具)为测试对象,同时监测其运行库libtiff.so
-s (SUT commandline): 被测程序命令行
e.g. -s "./bin/tiff2pdf -d %s -o result.pdf"
是要进行vuzzer的对象,具体为将普通执行程序语句中传入参数文件语句替换为%s,使vuzzer以此处输入为基础进行漏洞挖掘。如果有其他参数与设置将保留在其原位置,
-i (seed input directory (relative path)): 种子文件目录
e.g. -i "datatemp/tiff_seeds/" (该目录下存有4个.tiff文件)
种子文件是自动化漏洞挖掘的起始输入,vuzzer将在此之上进行输入变异。这里指向种子文件所在文件夹,建议对每一个被测程序,在vuzzer/datatemp/目录下新建文件夹存放其种子,种子文件至少4个(实际上有的官方示例种子文件却只有3个),大小被明确要求小于20kb。
-w (path of the pickle file(s) for BB wieghts (separated by comma in case there are two)
-n (Path of the pickle file(s) containing strings from CMP inst (separated by comma if there are two))
e.g.
-w "idafiles/tiff/tiff2pdf.pkl,idafiles/tiff/libtiff.so.pkl"
-n "idafiles/tiff/tiff2pdf.names,idafiles/tiff/libtiff.so.names"
这两类文件分别为 基本块描述文件 和 被测程序汇编码中用到cmp指令集的语句的有关信息。目前,这两类文件需要通过装有python扩展的IDA生成,将二进制可执行文件通过IDA打开,运行(Alt+F7)位于vuzzer目录下的BB-weightv4.py,将在二进制文件目录下生成.pkl,.names的文件。
如果要同时vuzzer一个该应用的库文件,那么也应对它的库(如libtiff.so)做同样的操作,并在使用参数时添上,再以“,”隔开。如上示例

需要注意的是,若在windows下使用IDA生成.pkl,.names文件,要在vuzzer上使用时,需要对这两个文件进行部分编码的转换,具体操作为:
$ dos2unix tiff2pdf.pkl
$ dos2unix tiff2pdf.names
-l (Number of binaries to monitor) 需要监测的二进制文件数量
e.g.
-l 2
默认为1,当仅需对程序进行vuzzer时忽略此项,若同时要对库文件进行vuzzer则该数=库数量+1
如本例为2
-o(base-address of application and library (if used))程序或库的起始地址
e.g.
-o "0x00000000,0x00000000"
默认”0×00000000″当仅检测程序时可忽略此项,若同时检测一个库则如上设置,一次运行后会提示库地址偏移已显示。在根目录下寻找到imageoffset.txt,取出其中的库地址偏移并修改-o值,如下,重新执行该命令,则会正常启动。(没错这确实是很奇怪的操作,作者说在下一版本会改正)
-o "0x00000000,0xba45760"
-b (library name to monitor)要监测的库名
e.g.
-b "libtiff"
参数使用要检测的库的名字,一般去掉拓展名(.so等)
示例程序测试
Project vuzzer 本身带有几个可供试验的程序,在bin目录下,其pickle文件在idafiles下,种子文件在datatemp下。
在vuzzer目录下,运行样例的命令为
peter@ubuntu:~/Desktop/vuzzer$ export PIN_ROOT=$(pwd)/pin ******设置pin根目录******
peter@ubuntu:~/Desktop/vuzzer$ echo 0 |sudo tee /proc/sys/kernel/randomize_va_space
[sudo] password for peter: ******关闭缓冲区随机化******
0
peter@ubuntu:~/Desktop/vuzzer$ echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
0
peter@ubuntu:~/Desktop/vuzzer$ python runfuzzer.py -s './bin/who %s' -i 'datatemp/utmp/' -w 'idafiles/who.pkl' -n idafiles/who.names ******启动vuzzer******运行一段时间后
ROOT集可能会保存在data中
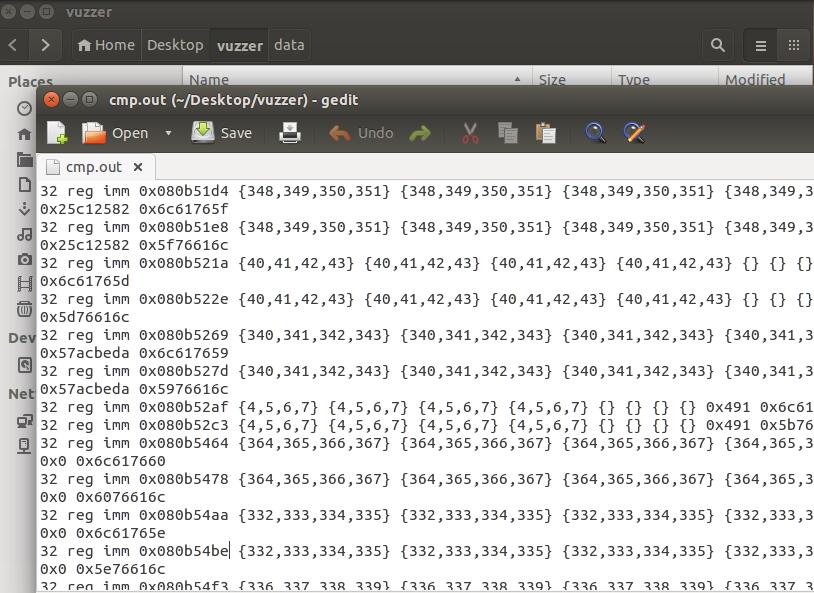
静态分析结果limm存放在cmp.out中
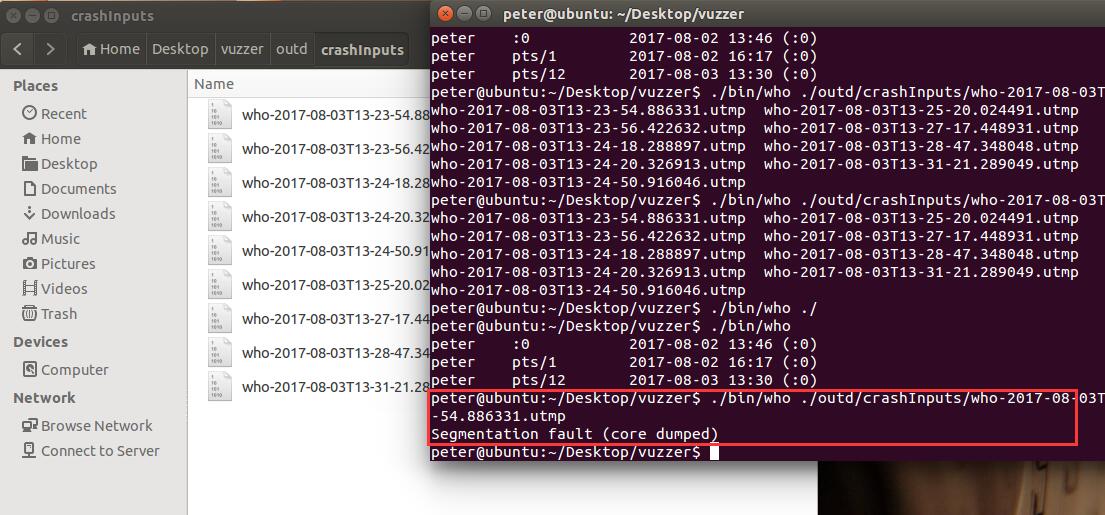
如果触发程序crash会在error.log记录
触发bug的输入存留在outd/crashInput/中
可以用该输入测试该程序
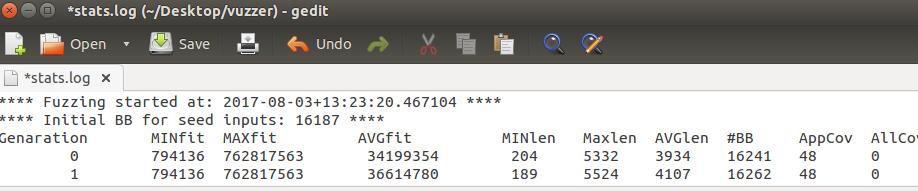
status.log中存有每一代的记录
同时监测程序与程序调用的库的vuzzer命令脚本
例如:对 tiff2pdf 及其引用库libtiff.so
#!/bin/bash
cd /home/peter/Desktop/vuzzer/
export PIN_ROOT=/home/peter/Desktop/vuzzer/pin
export LD_LIBRARY_PATH=/usr/lib/
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
echo "done"
python runfuzzer.py -s './bin/tiff2pdf %s -o result.pdf'
-i 'datatemp/tiff2pdftemp/'
-w './idafiles/tiff2pdf.pkl,./idafiles/libtiff.so.pkl'
-n './idafiles/tiff2pdf.names,./idafiles/libtiff.so.names'
-l 2
-o '0x00000000, 0xb67a5000'
-b 'tiff'#!/bin/bash
cd /home/peter/Desktop/vuzzer/
export PIN_ROOT=/home/peter/Desktop/vuzzer/pin
export LD_LIBRARY_PATH=/usr/lib/
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
echo "done"
python runfuzzer.py -s './bin/tiff2pdf %s -o result.pdf'
-i 'datatemp/tiff2pdftemp/'
-w './idafiles/tiff2pdf.pkl,./idafiles/libtiff.so.pkl'
-n './idafiles/tiff2pdf.names,./idafiles/libtiff.so.names'
-l 2
-o '0x00000000, 0xb67a5000'
-b 'tiff'感谢实习期间,在北京奇虎360公司,网络安全研究院对我的细致指导
附录
安装使用如遇到问题可在vuzzer_Issues讨论