1 __all__ = ['deque', 'defaultdict', 'namedtuple', 'UserDict', 'UserList', 2 'UserString', 'Counter', 'OrderedDict', 'ChainMap'] 3 4 # For backwards compatibility, continue to make the collections ABCs 5 # available through the collections module. 6 from _collections_abc import * 7 import _collections_abc 8 __all__ += _collections_abc.__all__ 9 10 from operator import itemgetter as _itemgetter, eq as _eq 11 from keyword import iskeyword as _iskeyword 12 import sys as _sys 13 import heapq as _heapq 14 from _weakref import proxy as _proxy 15 from itertools import repeat as _repeat, chain as _chain, starmap as _starmap 16 from reprlib import recursive_repr as _recursive_repr
all里面就是所有的数据结构,这里不单独详解用法了,user前缀的是提供来做接口便利用户实现自己的数据结构,其他的是有特殊用途的数据结构
大量使用了运算符重载,所以引入eq这些模块,又比如引入heapq堆实现Counter的功能
1 collections包含了一些特殊的容器,针对Python内置的容器,例如list、dict、set和tuple,提供了另一种选择; 2 3 namedtuple,可以创建包含名称的tuple; 4 5 deque,类似于list的容器,可以快速的在队列头部和尾部添加、删除元素; 6 双端队列,支持从两端添加和删除元素。更常用的栈和队列是退化形式的双端队列,仅限于一端在输入和输出。 7 dq = deque() 8 dq.append(x);dq.appendleft(x) dq.extend(seq) extendleft(seq) 9 dq.pop() popleft() 10 dq.rotate(+-x) x队列右移x -x 左移x 11 12 Counter,dict的子类,计算可hash的对象; 13 Counter 支持三种形式的初始化。它的构造函数可以调用序列,一个字典包含密钥和计数,或使用关键字参数映射的字符串名称。 14 空的Counter容器可以无参数构造,并采用update()方法进行更新 15 elements()方法可以返回一个包含所有Counter数据的迭代器 16 most_common(n)返回前n个最多的数据 17 Counter实例支持聚合结果的算术和集合操作。+ - & | 18 19 OrderedDict,dict的子类,可以记住元素的添加顺序; 20 多了一个move_to_end() pop popitem方法 21 22 defaultdict,dict的子类,可以调用提供默认值的函数; 23 标准字典包括setdefault方法()获取一个值,如果值不存在,建立一个默认。相比之下,defaultdict允许调用者在初始化时预先设置默认值。 24 import collections 25 26 def default_factory(): 27 return 'default value' 28 29 d = collections.defaultdict(default_factory, foo='bar') 30 print ('d:', d) 31 print ('foo =>', d['foo']) 32 print ('x =>', d['x']) 33 -- 34 d: defaultdict(<function default_factory at 0x000002567E713E18>, {'foo': 'bar'}) 35 foo => bar 36 x => default value
abc引入collections-abc基类模块,它记录了类似mapping的类抽象方法以及基本的类方法
init中实现了OrderedDict,namedtuple,userdict。。。counter等一系列额外的数据类型,大量的利用了上述的基类模块继承以及内置函数已经实现的运算符和数据类型方法,也大量的利用slot熟悉以及yield关键字构建生成器改写py2中占用大量内存的缺点
1 def move_to_end(self, key, last=True): 2 '''Move an existing element to the end (or beginning if last==False). 3 4 Raises KeyError if the element does not exist. 5 When last=True, acts like a fast version of self[key]=self.pop(key). 6 7 ''' 8 link = self.__map[key] 9 link_prev = link.prev 10 link_next = link.next 11 soft_link = link_next.prev 12 link_prev.next = link_next 13 link_next.prev = link_prev 14 root = self.__root 15 if last: 16 last = root.prev 17 link.prev = last 18 link.next = root 19 root.prev = soft_link 20 last.next = link 21 else: 22 first = root.next 23 link.prev = root 24 link.next = first 25 first.prev = soft_link 26 root.next = link
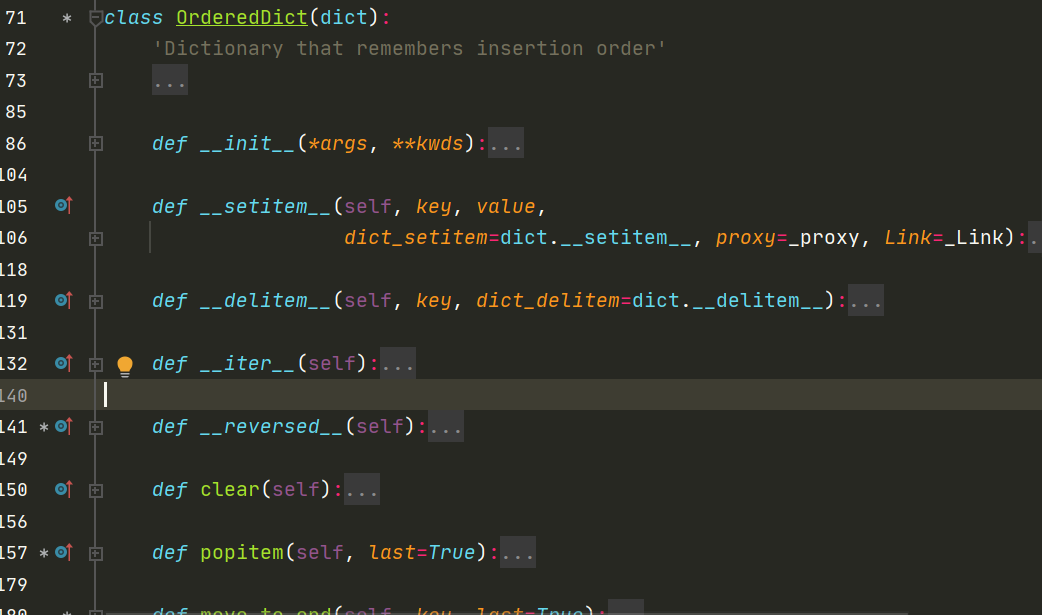
上面是ordereddict的大部分方法,还有move_to_end的实现
def namedtuple(typename, field_names, *, verbose=False, rename=False, module=None): # Validate the field names. At the user's option, either generate an error # message or automatically replace the field name with a valid name. if isinstance(field_names, str): field_names = field_names.replace(',', ' ').split() field_names = list(map(str, field_names)) typename = str(typename) if rename: seen = set() for index, name in enumerate(field_names): if (not name.isidentifier() or _iskeyword(name) or name.startswith('_') or name in seen): field_names[index] = '_%d' % index seen.add(name) for name in [typename] + field_names: if type(name) is not str: raise TypeError('Type names and field names must be strings') if not name.isidentifier(): raise ValueError('Type names and field names must be valid ' 'identifiers: %r' % name) if _iskeyword(name): raise ValueError('Type names and field names cannot be a ' 'keyword: %r' % name) seen = set() for name in field_names: if name.startswith('_') and not rename: raise ValueError('Field names cannot start with an underscore: ' '%r' % name) if name in seen: raise ValueError('Encountered duplicate field name: %r' % name) seen.add(name) # Fill-in the class template class_definition = _class_template.format( typename = typename, field_names = tuple(field_names), num_fields = len(field_names), arg_list = repr(tuple(field_names)).replace("'", "")[1:-1], repr_fmt = ', '.join(_repr_template.format(name=name) for name in field_names), field_defs = ' '.join(_field_template.format(index=index, name=name) for index, name in enumerate(field_names)) ) # Execute the template string in a temporary namespace and support # tracing utilities by setting a value for frame.f_globals['__name__'] namespace = dict(__name__='namedtuple_%s' % typename) exec(class_definition, namespace) result = namespace[typename] result._source = class_definition if verbose: print(result._source) if module is None: try: module = _sys._getframe(1).f_globals.get('__name__', '__main__') except (AttributeError, ValueError): pass if module is not None: result.__module__ = module return result
namedtuple则根据传参的不同采用不同的初始化方法,类型名总是固定的字符串,后面的字段名称可以传字段空格字段的字符串形式,也可以用可迭代对象的形式 字符串会split分割后转换成list,然后就都是可迭代对象了,利用*拆包传参,再利用set构造具名数组,我们用named[index]其实就是因为具名元组内部使用for index,name in enumerate(seq)的方式给set1[index]=name 赋值构造的
def __init__(*args, **kwds): ''' >>> c = Counter() # a new, empty counter >>> c = Counter('gallahad') # a new counter from an iterable >>> c = Counter({'a': 4, 'b': 2}) # a new counter from a mapping >>> c = Counter(a=4, b=2) # a new counter from keyword args ''' if not args: raise TypeError("descriptor '__init__' of 'Counter' object " "needs an argument") self, *args = args if len(args) > 1: raise TypeError('expected at most 1 arguments, got %d' % len(args)) super(Counter, self).__init__() self.update(*args, **kwds) def __missing__(self, key): 'The count of elements not in the Counter is zero.' # Needed so that self[missing_item] does not raise KeyError return 0 def most_common(self, n=None): '''List the n most common elements and their counts from the most common to the least. If n is None, then list all element counts. >>> Counter('abcdeabcdabcaba').most_common(3) [('a', 5), ('b', 4), ('c', 3)] ''' # Emulate Bag.sortedByCount from Smalltalk if n is None: return sorted(self.items(), key=_itemgetter(1), reverse=True) return _heapq.nlargest(n, self.items(), key=_itemgetter(1))
__missing__魔术方法用来实现当dict找不到key时要做的操作,collections大部分dict都有实现这个
然后比如我们常用的Counter的most_common这个方法,是通过堆实现的,return _heapq.nlargest(n, self.items(), key=_itemgetter(1))
上面说的大量使用运算符就以Counter为例,如果是简单的更新就用update(*,**)的方式更新计数器,函数内部会判断具体每个元素出现过没有,以此决定是新建一个键值对还是在原有的数量上+=(不是+=,我看内部好像一般不用+=都是直接赋值,可能是出于安全的考虑吧),构造了--add--、-sub等方法,新建一个counter合并或者怎样两个计数器对象,分别是self,other将他们按照方法意义将结果返回到result这个新建的计数器中,找不到指定的key当然调用missing方法,不过这只是针对结构相比字典变化大的类型,例如counter的missing是不存在的返回0,这很符合常理对吧,再比如说userdict 这种就是先用判断你有没有实现,有了用没有就抛异常
def __getitem__(self, key):
if key in self.data:
return self.data[key]
if hasattr(self.__class__, "__missing__"):
return self.__class__.__missing__(self, key)
raise KeyError(key)
而类似UserList Dict Str等用于给用户继承的类型则是大量的实现了常用方法,避免继承内置类型抄cpython近路使得一些方法不生效而编写的,当然如果你有需要可以再次重写某些方法,我们的目的也是这个
__ subclasshook__ 魔法。 这个 方法的作用是让抽象基类识别没有注册为子类的类, 你可以根据需要做 简单的或者复杂的测试——标准库的做法只是检查方法名称
继续拓展: