基于Arm64 linux-5.10
一、主要实现文件
1. preempt_count的位置
//arch/arm64/include/asm/preempt.h static inline int preempt_count(void) { return READ_ONCE(current_thread_info()->preempt.count); //(struct thread_info *)current->preempt.count }
注意:这是一个 per-task 的字段。
2. 相关实现
include/linux/preempt.h 仅保留可抢占和使用的部分:
//include/linux/preempt.h 仅保留可抢占和使用的部分 /* SPDX-License-Identifier: GPL-2.0 */ #ifndef __LINUX_PREEMPT_H #define __LINUX_PREEMPT_H /* * include/linux/preempt.h - macros for accessing and manipulating * preempt_count (used for kernel preemption, interrupt count, etc.) */ #include <linux/linkage.h> #include <linux/list.h> /* * We put the hardirq and softirq counter into the preemption * counter. The bitmask has the following meaning: * * - bits 0-7 are the preemption count (max preemption depth: 256) * - bits 8-15 are the softirq count (max # of softirqs: 256) * * The hardirq count could in theory be the same as the number of * interrupts in the system, but we run all interrupt handlers with * interrupts disabled, so we cannot have nesting interrupts. Though * there are a few palaeontologic drivers which reenable interrupts in * the handler, so we need more than one bit here. * * PREEMPT_MASK: 0x000000ff * SOFTIRQ_MASK: 0x0000ff00 * HARDIRQ_MASK: 0x000f0000 * NMI_MASK: 0x00f00000 * PREEMPT_NEED_RESCHED: 0x80000000 //bit31 int型最高bit,但<asm/preempt.h>中定义是BIT(32) !! */ #define PREEMPT_BITS 8 #define SOFTIRQ_BITS 8 #define HARDIRQ_BITS 4 #define NMI_BITS 4 #define PREEMPT_SHIFT 0 #define SOFTIRQ_SHIFT (PREEMPT_SHIFT + PREEMPT_BITS) //8 #define HARDIRQ_SHIFT (SOFTIRQ_SHIFT + SOFTIRQ_BITS) //16 #define NMI_SHIFT (HARDIRQ_SHIFT + HARDIRQ_BITS) //20 #define __IRQ_MASK(x) ((1UL << (x))-1) #define PREEMPT_MASK (__IRQ_MASK(PREEMPT_BITS) << PREEMPT_SHIFT) //bit0-bit7 0x000000ff #define SOFTIRQ_MASK (__IRQ_MASK(SOFTIRQ_BITS) << SOFTIRQ_SHIFT) //bit8-bit15 0x0000ff00 #define HARDIRQ_MASK (__IRQ_MASK(HARDIRQ_BITS) << HARDIRQ_SHIFT) //bit16-bit19 0x000f0000 #define NMI_MASK (__IRQ_MASK(NMI_BITS) << NMI_SHIFT) //bit20-bit23 0x00f00000 #define PREEMPT_OFFSET (1UL << PREEMPT_SHIFT) //1<<0 #define SOFTIRQ_OFFSET (1UL << SOFTIRQ_SHIFT) //1<<8 #define HARDIRQ_OFFSET (1UL << HARDIRQ_SHIFT) //1<<16 #define NMI_OFFSET (1UL << NMI_SHIFT) //1<<20 #define SOFTIRQ_DISABLE_OFFSET (2 * SOFTIRQ_OFFSET) //2*(1<<8) == 1<<9 #define PREEMPT_DISABLED (PREEMPT_DISABLE_OFFSET + PREEMPT_ENABLED) //1 + 1<<32 /* * Disable preemption until the scheduler is running -- use an unconditional * value so that it also works on !PREEMPT_COUNT kernels. * * Reset by start_kernel()->sched_init()->init_idle()->init_idle_preempt_count(). */ #define INIT_PREEMPT_COUNT PREEMPT_OFFSET //0 /* * Initial preempt_count value; reflects the preempt_count schedule invariant * which states that during context switches: * * preempt_count() == 2*PREEMPT_DISABLE_OFFSET * * Note: PREEMPT_DISABLE_OFFSET is 0 for !PREEMPT_COUNT kernels. * Note: See finish_task_switch(). */ #define FORK_PREEMPT_COUNT (2*PREEMPT_DISABLE_OFFSET + PREEMPT_ENABLED) //2 + 1<<32 /* preempt_count() and related functions, depends on PREEMPT_NEED_RESCHED */ #include <asm/preempt.h> #define hardirq_count() (preempt_count() & HARDIRQ_MASK) #define softirq_count() (preempt_count() & SOFTIRQ_MASK) #define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK | NMI_MASK)) /* * Are we doing bottom half or hardware interrupt processing? * * in_irq() - We're in (hard) IRQ context * in_softirq() - We have BH disabled, or are processing softirqs * in_interrupt() - We're in NMI,IRQ,SoftIRQ context or have BH disabled * in_serving_softirq() - We're in softirq context * in_nmi() - We're in NMI context * in_task() - We're in task context * * Note: due to the BH disabled confusion: in_softirq(),in_interrupt() really should not be used in new code. */ //各种上下文 #define in_irq() (hardirq_count()) #define in_softirq() (softirq_count()) #define in_interrupt() (irq_count()) #define in_serving_softirq() (softirq_count() & SOFTIRQ_OFFSET) #define in_nmi() (preempt_count() & NMI_MASK) #define in_task() (!(preempt_count() & (NMI_MASK | HARDIRQ_MASK | SOFTIRQ_OFFSET))) /* * The preempt_count offset after preempt_disable(); */ # define PREEMPT_DISABLE_OFFSET PREEMPT_OFFSET //1 /* * The preempt_count offset after spin_lock() */ #define PREEMPT_LOCK_OFFSET PREEMPT_DISABLE_OFFSET /* * The preempt_count offset needed for things like: * * spin_lock_bh() * * Which need to disable both preemption (CONFIG_PREEMPT_COUNT) and * softirqs, such that unlock sequences of: * * spin_unlock(); * local_bh_enable(); * * Work as expected. */ #define SOFTIRQ_LOCK_OFFSET (SOFTIRQ_DISABLE_OFFSET + PREEMPT_LOCK_OFFSET) /* * Are we running in atomic context? WARNING: this macro cannot * always detect atomic context; in particular, it cannot know about * held spinlocks in non-preemptible kernels. Thus it should not be * used in the general case to determine whether sleeping is possible. * Do not use in_atomic() in driver code. */ //判断是否在原子上下文 #define in_atomic() (preempt_count() != 0) /* * Check whether we were atomic before we did preempt_disable(): * (used by the scheduler) */ #define in_atomic_preempt_off() (preempt_count() != PREEMPT_DISABLE_OFFSET) #define preempt_count_add(val) __preempt_count_add(val) #define preempt_count_sub(val) __preempt_count_sub(val) #define preempt_count_dec_and_test() __preempt_count_dec_and_test() #define __preempt_count_inc() __preempt_count_add(1) #define __preempt_count_dec() __preempt_count_sub(1) #define preempt_count_inc() preempt_count_add(1) #define preempt_count_dec() preempt_count_sub(1) #define preempt_disable() \ do { \ preempt_count_inc(); \ barrier(); \ } while (0) #define sched_preempt_enable_no_resched() \ do { \ barrier(); \ preempt_count_dec(); \ } while (0) #define preempt_enable_no_resched() sched_preempt_enable_no_resched() #define preemptible() (preempt_count() == 0 && !irqs_disabled()) #define preempt_enable() \ do { \ barrier(); \ if (unlikely(preempt_count_dec_and_test())) \ __preempt_schedule(); \ } while (0) #define preempt_enable_notrace() \ do { \ barrier(); \ if (unlikely(__preempt_count_dec_and_test())) \ __preempt_schedule_notrace(); \ } while (0) #define preempt_check_resched() \ do { \ if (should_resched(0)) \ __preempt_schedule(); \ } while (0) #define preempt_disable_notrace() \ do { \ __preempt_count_inc(); \ barrier(); \ } while (0) #define preempt_enable_no_resched_notrace() \ do { \ barrier(); \ __preempt_count_dec(); \ } while (0) #define preempt_set_need_resched() \ do { \ set_preempt_need_resched(); \ } while (0) #define preempt_fold_need_resched() \ do { \ if (tif_need_resched()) \ set_preempt_need_resched(); \ } while (0) struct preempt_notifier; /** * preempt_ops - notifiers called when a task is preempted and rescheduled * @sched_in: we're about to be rescheduled: * notifier: struct preempt_notifier for the task being scheduled * cpu: cpu we're scheduled on * @sched_out: we've just been preempted * notifier: struct preempt_notifier for the task being preempted * next: the task that's kicking us out * * Please note that sched_in and out are called under different * contexts. sched_out is called with rq lock held and irq disabled * while sched_in is called without rq lock and irq enabled. This * difference is intentional and depended upon by its users. */ struct preempt_ops { void (*sched_in)(struct preempt_notifier *notifier, int cpu); void (*sched_out)(struct preempt_notifier *notifier, struct task_struct *next); }; /** * preempt_notifier - key for installing preemption notifiers * @link: internal use * @ops: defines the notifier functions to be called * * Usually used in conjunction with container_of(). */ struct preempt_notifier { struct hlist_node link; struct preempt_ops *ops; }; void preempt_notifier_inc(void); void preempt_notifier_dec(void); /* * tell me when current is being preempted & rescheduled. * sched/core.c中实现,kvm/kvm_main.c 中注册 */ void preempt_notifier_register(struct preempt_notifier *notifier); /* * no longer interested in preemption notifications. * sched/core.c中实现,kvm/kvm_main.c 中注册 */ void preempt_notifier_unregister(struct preempt_notifier *notifier); static inline void preempt_notifier_init(struct preempt_notifier *notifier, struct preempt_ops *ops) { INIT_HLIST_NODE(¬ifier->link); notifier->ops = ops; } /** * migrate_disable - Prevent migration of the current task * * Maps to preempt_disable() which also disables preemption. Use * migrate_disable() to annotate that the intent is to prevent migration, * but not necessarily preemption. * * Can be invoked nested like preempt_disable() and needs the corresponding * number of migrate_enable() invocations. */ static __always_inline void migrate_disable(void) { preempt_disable(); } /** * migrate_enable - Allow migration of the current task * * Counterpart to migrate_disable(). * * As migrate_disable() can be invoked nested, only the outermost invocation * reenables migration. * * Currently mapped to preempt_enable(). */ static __always_inline void migrate_enable(void) { preempt_enable(); } #endif /* __LINUX_PREEMPT_H */
二、preempt_count 各位段说明
1. 这个 per-任务的 counter 可以用来指示当前线程的状态、它是否可以被抢占,以及它是否被允睡眠。
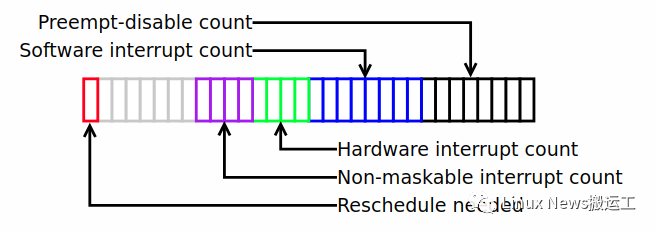
preempt_count 这个成员被用来判断当前进程是否可以被抢占。如果 preempt_count 不等于0(可能是代码调用preempt_disable显式的禁止了抢占,也可能是处于中断上下文等),说明当前不能进行抢占,如果 preempt_count 等于0,说明已经具备了抢占的条件(当然具体是否要抢占当前进程还是要看当前进程的 thread info 中的 flag 成员是否设定了 _TIF_NEED_RESCHED 这个标记,可能是当前的进程的时间片用完了,也可能是由于中断唤醒了优先级更高的进程)。
2. Preemption-disable Count 位段
占8bit,用来记录当前进程被显式的禁止抢占的嵌套的次数。也就是说,每调用一次 preempt_disable()就会加1,调用 preempt_enable(),就会减1。preempt_disable() 和 preempt_enable() 必须成对出现,可以嵌套,最大嵌套的深度是255,因为只有8bit。
3. Software interrupt count
占8bit,用来记录当前正在运行进程被软中断打断嵌套的次数。对此位段进行操作有两个场景:
(1) 也是在进入soft irq handler之前给此位段加1,退出soft irq handler之后给此位段减1。由于soft irq handler在一个CPU上是不会并发的,总是串行执行,因此,这个场景下只需要一个bit就够了,也就是上图中的bit8。通过该bit可以知道当前task是否在sofirq context。
(2) 由于内核同步的需求,进程上下文需要禁止 softirq。这时候,kernel提供了 local_bh_enable()和 local_bh_disable()这样的接口函数。这部分的概念是和preempt disable/enable 类似的,占用了bit9--bit15,最大可以支持127次嵌套。
注:local_bh_disable()中还有对 preempt_count 加上16,local_bh_enable()中减去16,目前还不明白为什么要这样做?
4. Hardware interrupt count 位段
占4bit,用来记录当前正在运行进程被硬中断打断嵌套的次数,用来描述当前中断handler嵌套的深度。对于ARM64平台的kernel-5.10,其中断部分的代码如下:
//kernel/irq/irqdesc.c int __handle_domain_irq(struct irq_domain *domain, unsigned int hwirq, bool lookup, struct pt_regs *regs) { ... struct irq_desc *desc; irq_enter(); generic_handle_irq_desc(desc); //desc->handle_irq(desc) irq_exit(); ... }
通用的IRQ handler被 irq_enter()和 irq_exit()这两个函数包围。irq_enter()说明进入到IRQ context,而 irq_exit()则说明退出IRQ context。在irq_enter()函数中会调用 preempt_count_add(HARDIRQ_OFFSET),为"Hardware interrupt count"的bit field增加1。在 irq_exit()函数中,会调用 preempt_count_sub(HARDIRQ_OFFSET) 减去1。占用了4bit说明硬件中断handler最大可以嵌套15层。
在旧的内核中,占12bit,支持4096个嵌套。当然,在旧的kernel中还区分fast interrupt handler和slow interrupt handler,中断handler最大可以嵌套的次数理论上等于系统IRQ的个数。在实际中,这个数目不可能那么大(内核栈就受不了),因此,即使系统支持了非常大的中断个数,也不可能各个中断依次嵌套,达到理论的上限。基于这样的考虑,后来内核减少为10bit(在general arch的代码中修改为10,实际上,各个arch可以redefine自己的hardirq count的bit数)。但是,当内核大佬们决定废弃slow interrupt handler的时候,实际上,中断的嵌套已经不会发生了。因此,理论上,hardirq count要么是0,要么是1。不过呢,不能总拿理论说事,实际上,万一有写奇葩或者老古董driver在handler中打开中断,那么这时候中断嵌套还是会发生的,但是,应该不会太多,因此,目前占用4bit,应付15个奇葩driver是妥妥的。
5. Reschedule needed位段
最高 bit31 这个"reschedule needed"位告诉内核,当前有一个优先级较高的进程应该在第一时间获得CPU。必须要在 preempt_count 为非零值的情况下,才会设置这个bit,否则的话内核早就可以直接对这个任务进行抢占,而没必要设置此bit并等待。
三、task的各种上下文
1. 各种context在 include/linux/preempt.h 中的定义:
/* * Are we doing bottom half or hardware interrupt processing? * * in_irq() - We're in (hard) IRQ context * in_softirq() - We have BH disabled, or are processing softirqs * in_interrupt() - We're in NMI,IRQ,SoftIRQ context or have BH disabled * in_serving_softirq() - We're in softirq context * in_nmi() - We're in NMI context * in_task() - We're in task context * * Note: due to the BH disabled confusion: in_softirq(),in_interrupt() really should not be used in new code. */ #define in_irq() (hardirq_count()) //preempt_count() & HARDIRQ_MASK #define in_softirq() (softirq_count()) //preempt_count() & SOFTIRQ_MASK #define in_interrupt() (irq_count()) //preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK | NMI_MASK) #define in_serving_softirq() (softirq_count() & SOFTIRQ_OFFSET) //preempt_count() & SOFTIRQ_OFFSET 只使用最低bit #define in_nmi() (preempt_count() & NMI_MASK) #define in_task() (!(preempt_count() & (NMI_MASK | HARDIRQ_MASK | SOFTIRQ_OFFSET)))
2. irq context 其实就是 hard irq context,也就是说明当前正在执行中断handler(top half),只要 preempt_count 中的 hardirq count 大于0(=1是没有中断嵌套,如果大于1,说明有中断嵌套),那么就是IRQ context。
3. softirq context 并没有那么的直接,一般人会认为当 sofirq handler 正在执行的时候就是 softirq context。这样说当然没有错,sofirq handler 正在执行的时候,会增加"Software interrupt count",当然是softirq context。不过,在其他context的情况下,例如进程上下文中,有可能因为同步的要求而调用local_bh_disable(),这时候,通过 local_bh_disable()/local_bh_enable() 保护起来的代码也是执行在 softirq context 中。当然,这时候其实并没有正在执行softirq handler。如果你确实想知道当前是否正在执行 softirq handler,可以使用 in_serving_softirq()来完成这个使命,这是通过操作 preempt_count 的bit8来完成的。
4. 所谓中断上下文,由 in_interrupt() 来表示,就是 IRQ context + softirq context + NMI context。
5. 进程上下文由 in_task() 表示,local_bh_disable()/local_bh_enable()保护的区间,仍然属于进程上下文,感觉与in_softirq()有冲突,此时就既属于软中断上下文又属于进程上下文了。
四、总结
1. 只要看一下 preempt_count() 的值,内核就可知道当前的情况如何,比如 preempt_count() 值是非零值,就表示当前线程不能被 scheduler 抢占,因为此时要么是抢占已经被明确被禁止了,要么是CPU当前正在处理某种中断。同理,非零值也表示当前线程不能睡眠(待确认!)。
2. preempt_disable()只适用于线程在kernel里运行的情况,而用户空间的代码则总是可以被抢占的。
3. 一个问题:如果配置为非抢占式内核,内核代码不能被抢占,那么就没有必要跟踪记录 preempt_disable()了,因为抢占是永远被关闭,不用浪费时间去维护这些信息,因此此时 preempt_count 的 preempt-disable 这几个 bit 总是为0,preemptible() 函数将总是返回 false。非抢占式内核中,在某些情况下,例如当 spin_lock 被持有时(这种情况确实是 atomic context),in_atomic()却会由于这个 preempt_count()==0 而返回 false。
4. might_sleep(): 指示当前函数可以睡眠。如果它所在的函数处于原子上下文(atomic context)中,将打印出堆栈的回溯信息。这个函数主要用来做调试工作,在你不确定不期望睡眠的地方是否真的不会睡眠时,就把这个宏加进去。对于内核Release版本,一般没有使能 CONFIG_DEBUG_ATOMIC_SLEEP,might_sleep() 就是一个空函数。
5. spin_lock()/spin_unlock()保护的区间不能休眠的原因
static __always_inline void spin_lock(spinlock_t *lock) { do { preempt_disable(); ___LOCK(&lock->rlock); } while (0); }
spin_lock 在获取不到锁的时候就会自旋等待。在尝试获取锁之前会先关抢占,若是一个进程A在获取到锁之后休眠了,此时调度器将调度其它任务B在当前CPU上运行,若任务B也获取这个锁,若是会获取不到从而进入自旋状态,此时又是关闭抢占的,此CPU始终无法调度其它任务到当前CPU上运行,则当前CPU则会死锁在任务B上。