概述
环境
- Ubuntu 18.04
- CPU
- 代码地址
分类
根据不同的功能, 将所有的文件分成了5类
- 人脸检测:从图片中检测人脸
- 图片处理:图片数据增强、人脸分割等处理
- 人脸识别:如题所述
- 训练检测物体:自己动手训练一个简单的物体识别模型, 推荐图片打标网站ImageLab
- 其他:一些演示程序,找最优值,svm例子等等
人脸检测
cnn_face_detector.py
使用卷积神经网络训练的脸部检测器, 检测一张图片的人脸准确率比较高,遮挡较多不能检测, 在CPU上检测一张图片平均需要花费几秒钟。


face_detector.py
使用HOG特征,线性分类器训练得到的脸部检测器,准确率较高, 速度也很, 所以经常使用。

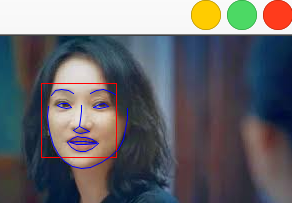
face_landmark_detection.py
68个landmark点。下面第二张图片显示了68个点的分布。

图片处理
face_aligment.py
利用5点landmark 将人脸图片截出来, 基本能够将所有人脸剪裁出来, 有时候会出现重复。
原图:

得到的人脸图:



.....省略其他图片.....
face_clustering.py
用5点landmark 得到脸型, 用resnet模型做人脸识别, 将所有图片中相似的图片聚类。
输入文件

输出文件

find_candidate_object_location.py
输入一张图片, 产生一系列的矩形, 这些矩形包括了任何可能需要检测的物体。

opencv_webcam_face_detection.py
结合opencv从视频中检测人脸, 使用的是HOG特征。
face_jitter.py
旋转、平移、缩放图像, 改变图像颜色等方法做数据增强。
原图

增强生成的一些图片。




人脸识别
face_recongnition.py
用5个landmark点, 检测一张人脸, 将人脸转化成128维的向量,记为人脸特征向量, 用欧几里得距离计算不同人脸特征向量的距离,判断是否是同一个人(阈值通常为0.6)。

训练检测物体
train_object_detector.py
利用hog特征,训练人脸图片,得到一个简单的物体检测模型。
训练完成, 得到detector.svm文件。

左图是HOG特征的可视化,右图是测试效果。

只有一个svm文件使用的是
dlib.simple_object_detector("detector.svm")
dets = detector(img)
如果有多个svm文件则使用
detector1 = dlib.fhog_object_detector("detector1.svm")
detector2 = dlib.fhog_object_detector("detector2.svm")
detectors = [detector1, detector2]
[boxes, confidences, detector_idxs] = dlib.fhog_object_detector.run_multiple(detectors, image, upsample_num_times=1, adjust_threshold=0.0)
train_shape_predictor.py
使用68个点训练。
训练完成:

训练结果:


其他
其他没有列出来的例子可以直接运行。由于这些例子都是一些演示,而且和我本人的研究无关,因此没有深入的研究下去了(狗头保命)。自己跑一下代码,看注释吧。