子查询优化思路
1、前提条件子查询是作为条件,作为一个结果集返回给外层,或者返回结果集让from表过滤条件的一种手段方式:分为where 后面子查询 和from后面或者join后面的子查询来加入语句中。
2、子查询由相关子查询和非相关子查询两种,尽量使用非相关子查询语句,这样查询只是用一次,作为一个整体结果集来使用。
3、子查询在join后面的话,也是一样的mysql 使用Nested Loop Join 算法,就是嵌套循环算法,查询出来的join(语句),也是作为一个整体结果集做过滤条件的,问题在于是否使用的关联的方式,如果使用关联的方式那么也是外面循环一次,里面查询也要依次循环一次,而作为一个整体结果集,就不会循环外层的参数了,尽量使用非相关子查询来使用。
4、尽可能的少关联使用join这个关键字,在表的数据量少的情况下可以使用,多的话,循环起来也是个麻烦的。
非相关子查询和相关子查询执行过程详解
1、非相关子查询:
select t.sno,t.sname,t.sage,t.sgentle,t.sbirth,t.sdept from student t
where t.sno in ( select f.sno from garde f where f.score=70 )
1、在grade表中找出成绩为70的学生学号sno,再将该学号返回到父查询作为where子句的条件。
2、在student表中找到该学号学生的其他基本信息
2、相关子查询:
select t.sno,t.sname,t.sage,t.sgentle,t.sbirth,sdept from student t
where 80<=( select f.score from grade f where f.sno=t.sno and f.cname='计算机基础' )
1、 先从父查询的student表中取出第一条记录的sno值,进入子查询中,比较其where子句的条件“where f.sno=t.sno and f.cname=’计算机基础’”,符合则返回score成绩。
2、 返回父查询,判断父查询的where子句条件80<=返回的score,如果条件为true,则返回第1条记录。
3、 从父查询的student表中取出第2条数据,重复上述操作,直到所有父查询中的表中记录取完为止。
mysql查询优化--临时表和文件排序(Using temporary; Using filesort问题解决)
先看一段sql:
- <span style="font-size:18px;">SELECT
- *
- FROM
- rank_user AS rankUser
- LEFT JOIN rank_user_level AS userLevel ON rankUser.id = userLevel.user_id
- LEFT JOIN rank_product AS product ON userLevel.new_level = product.level_id
- LEFT JOIN rank_product_fee AS fee ON userLevel.fee_id = fee.fee_id
- LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
- ORDER BY
- rankUser.create_time DESC
- LIMIT 10 OFFSET 0</span>
介绍一下这段sql的表的构成:一张主表:rank_user;两张跟rank_user直接关联(多张表通过同一字段最好是主键进行关联)的表:rank_user_level ,rank_user_login_stat ;两张跟rank_user非直接关联的表:rank_product ,rank_product_fee 。这段sql看似简单,但是执行时间却很长,我们来看一下执行计划:
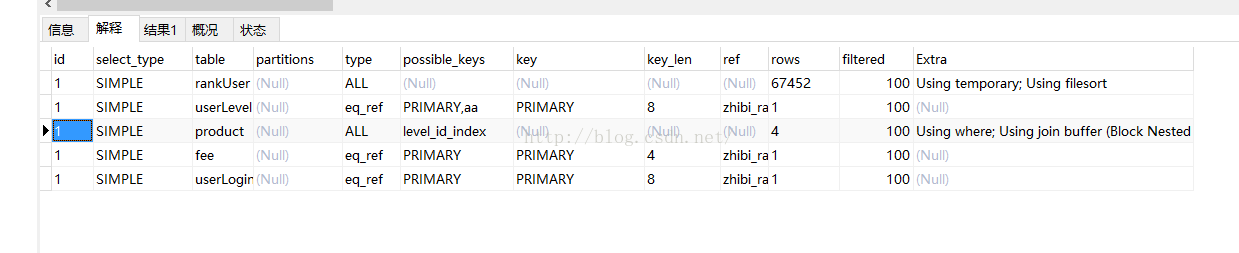
执行时间1.45s,可以看到,这段不仅仅扫描全表,而且使用了临时表,进行了文件排序。
为了找到原因,我们把排序去掉看一下:
- SELECT
- *
- FROM
- rank_user AS rankUser
- LEFT JOIN rank_user_level AS userLevel ON rankUser.id = userLevel.user_id
- LEFT JOIN rank_product AS product ON userLevel.new_level = product.level_id
- LEFT JOIN rank_product_fee AS fee ON userLevel.fee_id = fee.fee_id
- LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
- -- ORDER BY
- -- rankUser.create_time DESC
- LIMIT 10 OFFSET 0

执行时间0.015s,扫描行数67452,果然是排序惹的祸。但是仅仅是排序惹的祸吗?别忘了这里有两张非直接关联的表,这样的查询,如果有查询条件或者排序分组的时候往往都需要创建临时表(这个没有办法,想想也知道)。为了验证这个观点,我们把两张非直接关联的表去掉看一下:
- SELECT
- *
- FROM
- rank_user AS rankUser
- LEFT JOIN rank_user_level AS userLevel ON rankUser.id = userLevel.user_id
- -- LEFT JOIN rank_product AS product ON userLevel.new_level = product.level_id
- -- LEFT JOIN rank_product_fee AS fee ON userLevel.fee_id = fee.fee_id
- LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
- ORDER BY
- rankUser.create_time DESC
- LIMIT 10 OFFSET 0
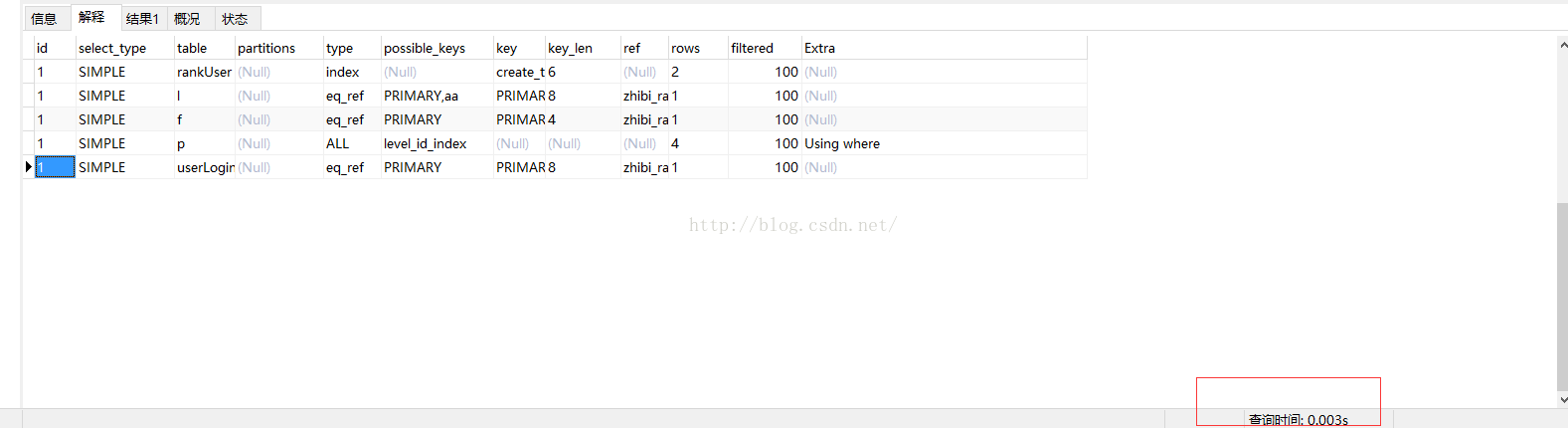
执行时间0.003s,扫描行数10,屌爆了有木有,mysql多表直接关联在没有其他筛选条件的情况下,查询速度大大提升,而且排序可以使用create_time这个索引,直接取到前十条。

到了这里,我想大家应该已经明白第一条sql查询时间很长的原因了:多表非直接关联的前提下还要排序。mysql查询往往最需要优化的地方就是临时表和文件排序了。这里总结一下教训:
1.mysql查询存在直接关联和非直接关联的问题,这两种查询效率差别很大;
2.mysql排序尽量使用索引;
3.mysql多表关联left join其他表的时候,如果以其他表的字段作为查询条件都会产生临时表;
4.mysql在非直接关联的基础上进行排序会很慢,需要进行优化;
知道了问题,我们就好优化了,这里我给出了两种方案:
第一种(子查询,适合子查询部分不作为查询条件):
- SELECT
- rankUser.id, rankUser.qq, rankUser.phone, rankUser.regip, rankUser.channel, rankUser.create_time, rankUser.qudao_key, rankUser.qq_openid, rankUser.wechat_openid,
- userLevel.recommend_count,userLevel.end_time,userLevel.new_level,userLevel.`level`,userLevel.new_recommend_count,userLevel.`is_limited`,
- (case when userLevel.new_level > 1 then 1 else 0 end) is_official_user,
- (select product_name from rank_product where level_id = userLevel.new_level) product_name,
- (select period from rank_product_fee where fee_id = userLevel.fee_id) period,
- userLoginInfo.last_login, userLoginInfo.login_count, userLoginInfo.login_seconds
- FROM rank_user AS rankUser
- LEFT JOIN rank_user_level as userLevel on userLevel.user_id=rankUser.id
- LEFT JOIN rank_user_login_stat as userLoginInfo ON rankUser.id = userLoginInfo.user_id
- ORDER BY
- rankUser.create_time DESC
- LIMIT 10 OFFSET 0

第二种(非直接关联转变成直接关联,这个要根据业务来定,我这里rank_product和rank_product_fee两张表只是为了查询rank_user_level表中的产品和产品费用信息,而rank_user_level是一张直接关联的表,故这里可以先将这三张表进行合并,然后再和rank_user表进行联合查询):
- SELECT
- *
- FROM
- rank_user AS rankUser
- LEFT JOIN (
- select
- l.*,p.product_name,f.period
- from
- rank_user_level l,rank_product p,rank_product_fee f
- where
- l.new_level = p.level_id
- and l.fee_id = f.fee_id
- ) AS userLevel ON rankUser.id = userLevel.user_id
- LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
- ORDER BY
- rankUser.create_time DESC
- LIMIT 10 OFFSET 0