一 time模块
1.时间戳时间
(1)time.time()
(2)通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
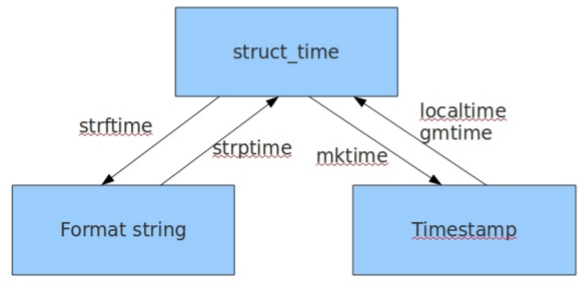
2.结构化时间
(1)time.localtime()
3.格式化时间/字符串时间
(1)time.strftime()
(2)struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
4.相互转化


import time s1 = time.localtime(15000000) s2 = time.strftime("%Y-%m-%d %H:%M:%S", s1) print(s1) print(s2) s3 = time.strptime("2018-08-08 08:08:08","%Y-%m-%d %H:%M:%S") s4 = time.mktime(s3) print(s3) print(s4)
二.sys模块
(1)sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
(2)sys.modules
(3)sys.paltform 返回操作系统平台名称
(4)sys.exits() 退出程序,正常退出时exit(0),错误退出sys.exit(1)
(5)sys.argv() 命令行参数List,第一个元素是程序本身路径
三. os模块
1.和工作目录有关的
(1)os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
(2)os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
(3)os.curdir 返回当前目录: ('.')
(4)os.pardir 获取当前目录的父目录字符串名:('..')
2.创建/删除文件夹
(1) os.mkdir() 创建一级目录
(2)os.makedirs() 创建多级目录
(3)os.rmdir() 删除单级目录
(4)os.removedirs() 删除多级目录,递归向上删除,直到遇见目录中有文件的停止删除
(5) os.listdir() 列表列出指定目录下的所有文件和子目录
3.操作系统的差异
(1)os.stat('path/filename') 获取文件/目录信息
(2)os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
(3)os.linesep 输出当前平台使用的行终止符,win下为" ",Linux下为" "
(4)os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
(5)os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
4.使用python来和操作系统命令交互
(1)os.system("bash command") 运行shell命令,直接显示
(2)os.popen("bash command).read() 运行shell命令,获取执行结果
(3)os.environ 获取系统环境变量
5.os.path
(1)os.path.abspath(path) 返回path规范化的绝对路径
(2)os.path.split(path) 将path分割成目录和文件名二元组返回
(3)os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
(4)os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素
(5)os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
(6)os.path.isabs(path) 如果path是绝对路径,返回True
(7)os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
(8)os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
(9)os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
(10)os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
(11)os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
(12)os.path.getsize(path) 返回path的大小
a = os.path.abspath("D:python14day 20") a1 = os.path.split(a) a2 = os.path.dirname(a) a3 = os.path.basename(a) a4 = os.path.exists(a) a5 = os.path.isabs(a) a6 = os.path.isfile("D:python14day 20热.py") a7 = os.path.isdir("D:python14") a8 = os.path.join("D:python14day 20热.py","aaa","fff") a9 = os.path.getatime("D:python14day 20热.py") a10 = os.path.getmtime("D:python14day 20热.py") a11 = os.path.getsize("D:python14day 20hudog.py")
四 .序列化模块
1 . json 模块
(1) json.dumps() 序列化 可以进行序列化的有list,dict,str,int
(2) json.loads() 反序列化
(3)json.dump()
(4) json.load()
英文序列化
ret = json.dumps(["中国人", "日本鬼子", "老毛子"]) print(ret) #["u4e2du56fdu4eba", "u65e5u672cu9b3cu5b50", "u8001u6bdbu5b50"] 序列化时中文变为bytes形式 ret1 = json.loads(ret) #ret = json.dumps(["中国人", "日本鬼子", "老毛子"], ensure_ascii=False) 这种形式序列化中文不会变 print(ret1) f = open("qq.py","w") json.dump(["中国人", "日本鬼子", "老毛子"], f,) f = open("qq.py",) ret = json.load(f) print(ret) import json data = {'username':['李华','二愣子'],'sex':'male','age':16} json_dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(',',':'),ensure_ascii=False) print(json_dic2) #sort_keys=True 以首字母对可以排序,indent=2缩进2
2.pickle模块
(1)pickle.dumps() 序列化,返回的是bytes类型
(2) pickle.loads()
(3) pickle.dump()
(4) pickle.load()
import pickle ret = pickle.dumps({"1":1,"2":2,"3":3,"4":4}) # 序列化 将list.dict转化为bytes类型 ret2 = pickle.dumps([1,"wert",132,"t43"]) print(ret2,type(ret2)) ret3 = pickle.loads(ret) #反序列化 将bytes类型转回list,dict类型 print(ret3) f = open("qq.py","wb",) pickle.dump({"1":1,"2":2,"3":3,"4":4}, f) #文件操作要以wb,rb形式写入 f = open("qq.py","rb") ret = pickle.load(f) print(ret) class Student: def __init__(self, name, age): self.name = name self.age = age s = Student("胡", 18) ret = pickle.dumps(s) #pickle能处理几乎所有的对象 print(ret) ret1 = pickle.loads(ret) print(ret1.name,ret1.age)
(5)json与pickle的区别
1.json只可以对dict,list,int,str等数据类型进行序列化,而pickle可以对任何数据类型进行序列化,还可以处理几乎所有的对象.
2.json是一种所有编程语言都能识别的一种数据类型. 而pickle只能被python这一种语言识别.
3.json用于字符串与python中的数据类型间进行转换,而pickle用于python中特有的类型和python中的数据类型进行交换
3.shelve模块
(1)shelve也是python提供给我们的序列化工具,比pickle用起来更简单一些。
(2)shelve只提供给我们一个open方法,是用key来访问的,使用起来和字典类似。
import shelve f = shelve.open('shelve_file') f['key'] = {'int':10, 'float':9.5, 'string':'Sample data'} #直接对文件句柄操作,就可以存入数据 f.close() import shelve f1 = shelve.open('shelve_file') existing = f1['key'] #取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错 f1.close() print(existing)