为什么要优化
- 系统的吞吐量瓶颈往往出现在数据库的访问速度上
- 随着应用程序的运行,数据库的中的数据会越来越多,处理时间会相应变慢
- 数据是存放在磁盘上的,读写速度无法和内存相比
如何优化
- 设计数据库时:数据库表、字段的设计,存储引擎
- 利用好MySQL自身提供的功能,如索引等
- 横向扩展:MySQL集群、负载均衡、读写分离
- SQL语句的优化(收效甚微)
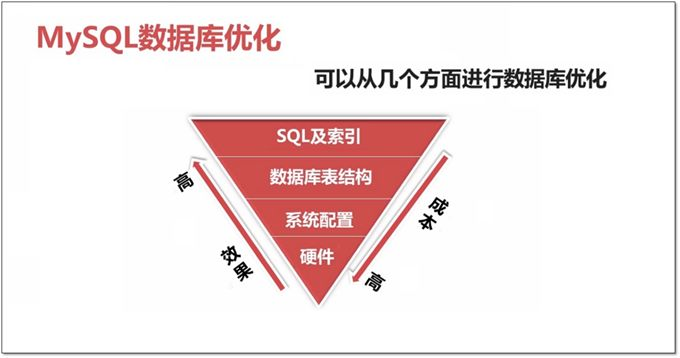
数据库优化维度有四个:
硬件、系统配置、数据库表结构、SQL及索引。
在数据库优化上有两个主要方面:即安全与性能。
-
安全->数据可持续性;
-
性能->数据的高性能访问。
存储、主机和操作系统方面:
-
主机架构稳定性;
-
I/O规划及配置;
-
Swap交换分区;
-
OS内核参数和网络问题。
应用程序方面:
-
应用程序稳定性;
-
SQL语句性能;
-
串行访问资源;
-
性能欠佳会话管理;
-
这个应用适不适合用MySQL。
数据库优化方面:
-
内存;
-
数据库结构(物理&逻辑);
-
实例配置。
- SQL优化方向:执行计划、索引、SQL改写
- 架构优化方向:高可用架构、高性能架构、分库分表
数据库结构:
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
第一范式1NF:原子性(不可拆分)
第二范式2NF:消除部分依赖(主键约束)
第三范式3NF:消除传递依赖(外键约束)
第一范式:具有原子性,确保每列保持原子性
第一范式就是属性不可分割,每个字段都应该是不可再拆分的。比如一个字段是姓名(NAME),在国内的话通常理解都是姓名是一个不可再拆分的单位,这时候就符合第一范式;但是在国外的话还要分为FIRST NAME和LAST NAME,这时候姓名这个字段就是还可以拆分为更小的单位的字段,就不符合第一范式了。
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式。
第二范式:主键列与非主键列遵循完全函数依赖关系,确保表中的每列都和主键相关
第二范式就是要求表中要有主键,表中其他其他字段都依赖于主键,因此第二范式只要记住主键约束就好了。比如说有一个表是学生表,学生表中有一个值唯一的字段学号,那么学生表中的其他所有字段都可以根据这个学号字段去获取,依赖主键的意思也就是相关的意思,因为学号的值是唯一的,因此就不会造成存储的信息对不上的问题,即学生001的姓名不会存到学生002那里去。
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
第三范式:非主键列之间没有传递函数依赖关系索引,确保每列都和主键列直接相关,而不是间接相关
第三范式就是要求表中不能有其他表中存在的、存储相同信息的字段,通常实现是在通过外键去建立关联,因此第三范式只要记住外键约束就好了。比如说有一个表是学生表,学生表中有学号,姓名等字段,那如果要把他的系编号,系主任,系主任也存到这个学生表中,那就会造成数据大量的冗余,一是这些信息在系信息表中已存在,二是系中有1000个学生的话这些信息就要存1000遍。因此第三范式的做法是在学生表中增加一个系编号的字段(外键),与系信息表做关联。
逆范式:逆范式是指打破范式,通过增加冗余或重复的数据来提高数据库的性能。
MySQL优化三大方向:
① 优化MySQL所在服务器内核(此优化一般由运维人员完成)。
② 对MySQL配置参数进行优化(my.cnf)此优化需要进行压力测试来进行参数调整。
③ 对SQL语句以及表优化。
MySQL参数优化
1:MySQL 默认的最大连接数为 100,可以在 mysql 客户端使用以下命令查看
mysql> show variables like 'max_connections';
2:查看当前访问Mysql的线程
mysql> show processlist;
3:设置最大连接数
mysql>set globle max_connections = 5000;
最大可设置16384,超过没用
4:查看当前被使用的connections
mysql>show globle status like 'max_user_connections'
对MySQL语句性能优化的16条经验:
① 为查询缓存优化查询
② EXPLAIN 我们的SELECT查询(可以查看执行的行数)
③ 当只要一行数据时使用LIMIT 1
④ 为搜索字段建立索引
⑤ 在Join表的时候使用相当类型的列,并将其索引
⑥ 千万不要 ORDER BY RAND ()
⑦ 避免SELECT *
⑧ 永远为每张表设置一个ID
⑨ 可以使用ENUM 而不要VARCHAR
⑩ 尽可能的使用NOT NULL
⑪ 固定长度的表会更快
⑫ 垂直分割
⑬ 拆分打的DELETE或INSERT语句
⑭ 越小的列会越快
⑮ 选择正确的存储引擎
⑯ 小心 "永久链接"