欢迎关注WX公众号:【程序员管小亮】
专栏——TensorFlow学习笔记
文章目录
一、TensorFlow 2.0 和 Keras 的关系
如果你学过 Keras 的话,就会发现上面的实例中均使用了 Subclassing API 建立模型,不过在 TensorFlow 2.0 中,是对 tf.keras.Model 类进行扩展以定义自己的新模型,同时手工编写了训练和评估模型的流程。这种方式灵活度高,且与其他流行的深度学习框架(如 PyTorch、Chainer)共通(共通的意思不是可以一起使用,而是道理相同)。
如果在某些时候,只需要一个结构相对简单和典型的神经网络,比如上文中的 MLP(TensorFlow2.0 学习笔记(二):多层感知机(MLP))和 CNN(TensorFlow2.0 学习笔记(三):卷积神经网络(CNN)),则可以使用 Keras 来提供了另一套更为简单高效的内置方法来建立网络。

简单来说,就是 Keras 是在 TensorFlow 基础上构建的高层 API。
二、Keras Sequential/Functional API 模式建立模型
最典型和常用的神经网络结构就是将一堆层按特定顺序叠加起来,这样方便查看,也方便改动,即只需要提供一个层的列表,就能由 Keras 将它们自动首尾相连,形成模型,这便是 Keras 的 Sequential API 的魅力。
通过向 tf.keras.models.Sequential() 提供一个层的列表,就能快速地建立一个 tf.keras.Model 模型并返回:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(100, activation=tf.nn.relu),
tf.keras.layers.Dense(10),
tf.keras.layers.Softmax()
])
如上所见:
tf.keras.layers.Flatten()即Flatten层用于将最终特征映射转换为一个一维向量,展开之后可以在某些卷积/maxpool层之后使用全连接层,它结合了以前卷积层提取的所有局部特征;tf.keras.layers.Dense即全连接(dense)层是用于实现分类,即人工神经网络分类器;tf.keras.layers.Softmax()多用于分类,使得网络输出每个类别的概率分布。
不过,这种层叠结构并不能表示任意的神经网络结构,例如多输入 / 输出或存在参数共享的模型。其使用方法是将层作为可调用的对象并返回张量,并将输入向量和输出向量提供给 tf.keras.Model 的 inputs 和 outputs 参数,示例如下:
inputs = tf.keras.Input(shape=(28, 28, 1))
x = tf.keras.layers.Flatten()(inputs)
x = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)(x)
x = tf.keras.layers.Dense(units=10)(x)
outputs = tf.keras.layers.Softmax()(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
我们在 Kaggle竞赛实战系列(一):手写数字识别器(Digit Recognizer)得分99.53%、99.91%和100% 中通过 Keras 实现了一个神经网络,Keras 实现网络的实例如下:
# 设置CNN模型
model = Sequential()
model.add(Conv2D(filters = 32, kernel_size = (5,5),padding = 'Same',
activation ='relu', input_shape = (28,28,1)))
model.add(BatchNormalization())
model.add(Conv2D(filters = 32, kernel_size = (5,5),padding = 'Same',
activation ='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(256, activation = "relu"))
model.add(Dropout(0.5))
model.add(Dense(10, activation = "softmax"))
三、训练和评估模型
当模型建立完成后,通过 tf.keras.Model 的 compile 方法配置训练过程:
model = tf.keras.Model(inputs=inputs, outputs=outputs)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
如上所见,tf.keras.Model.compile 一共有 3 个重要的参数:
oplimizer即优化器,可从tf.keras.optimizers中选择;loss即损失函数,可从tf.keras.losses中选择;metrics即评估指标,可从tf.keras.metrics中选择。
接下来,可以使用 tf.keras.Model 的 fit 方法训练模型:
model = tf.keras.Model(inputs=inputs, outputs=outputs)
model.fit(data_loader.train_data, data_loader.train_label,
epochs=num_epochs, batch_size=batch_size, verbose = 1)
如上所见,tf.keras.Model.fit 一共有 5 个重要的参数:
x即训练数据;y即训练数据标签;epochs即将训练数据迭代次数;batch_size即批大小;validation_data即验证数据,可用于在训练过程中监控模型的性能;verbose即0, 1,默认为1,表示日志显示。verbose = 0在控制台没有任何输出;verbose = 1显示进度条。
最后,使用 tf.keras.Model.evaluate 评估训练效果,提供测试数据及标签即可:
model = tf.keras.Model(inputs=inputs, outputs=outputs)
model.evaluate(data_loader.test_data, data_loader.test_label,
batch_size=None, verbose=1, callbacks=None)
如上所见,tf.keras.Model.evaluate 一共有 5 个参数:
x即测试数据;y即测试数据标签;batch_size即批大小;verbose即0, 1,默认为1,表示日志显示。verbose = 0在控制台没有任何输出;verbose = 1显示进度条;callbacks即回调函数,用来回调参数。
除了上面提到的这些,还有 tf.keras.Model.fit_generator(),可以在数据生成器上拟合模型,可以减少内存消耗,
model.fit_generator(datagen.flow(X_train,Y_train, batch_size=batch_size),
epochs = epochs, validation_data,
verbose = 1, steps_per_epoch,
callbacks=None)
如上所见,tf.keras.Model.fit_generator() 一共有 8 个参数:
x即测试数据;y即测试数据标签;batch_size即批大小;epochs即将训练数据迭代次数;validation_data即验证数据,可用于在训练过程中监控模型的性能;verbose即0, 1,默认为1,表示日志显示。verbose = 0在控制台没有任何输出;verbose = 1显示进度条;steps_per_epoch即每个epoch的迭代步数;callbacks即回调函数,用来回调参数。
这些方法其实都是基于 Keras 实现的,不过现在都是 TensorFlow 的了。。。
四、自定义层
很明显除了系统默认的这些层,你一定会有自己想要定义的层。
那么怎么样来设置呢?
可以继承 tf.keras.layers.Layer 编写自己的层,并重写 __init__ 、 build 和 call 三个方法,如下所示:
class MyLayer(tf.keras.layers.Layer):
def __init__(self):
super().__init__()
# 初始化代码
def build(self, input_shape): # input_shape 是一个 TensorShape 类型对象,提供输入的形状
# 在第一次使用该层的时候调用该部分代码
# 在这里创建变量可以使得变量的形状自适应输入的形状
# 而不需要使用者额外指定变量形状。
# 如果已经可以完全确定变量的形状,也可以在__init__部分创建变量
self.variable_0 = self.add_weight(...)
self.variable_1 = self.add_weight(...)
def call(self, inputs):
# 模型调用的代码(处理输入并返回输出)
return output
例如,如果想要自己实现一个全连接层( tf.keras.layers.Dense ),可以按如下方式编写。此代码在 build 方法中创建两个变量,并在 call 方法中使用创建的变量进行运算:
class LinearLayer(tf.keras.layers.Layer):
def __init__(self, units):
super().__init__()
self.units = units
def build(self, input_shape): # 这里 input_shape 是第一次运行call()时参数inputs的形状
self.w = self.add_variable(name='w',
shape=[input_shape[-1], self.units], initializer=tf.zeros_initializer())
self.b = self.add_variable(name='b',
shape=[self.units], initializer=tf.zeros_initializer())
def call(self, inputs):
y_pred = tf.matmul(inputs, self.w) + self.b
return y_pred
在定义模型的时候,便可以如同 Keras 中的其他层一样,调用自定义的层 LinearLayer:
class LinearModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.layer = LinearLayer(units=1)
def call(self, inputs):
output = self.layer(inputs)
return output
五、自定义损失函数
在 TensorFlow2.0 学习笔记(三):卷积神经网络(CNN) 中我们是通过调用 tf.keras.losses 来实现损失函数的使用。

那么如果我想自定义一个损失函数呢?
自定义损失函数需要继承 tf.keras.losses.Loss 类,重写 call 方法即可,输入真实值 y_true 和模型预测值 y_pred ,输出模型预测值和真实值之间通过自定义的损失函数计算出的损失值。
如果想使用官方定义的均方差损失函数,可以在 https://tensorflow.google.cn/api_docs/python/tf/keras/losses?hl=zh-cn 中查询,tf.keras.losses.mean_squared_error 即可,或者还有好多相同的写法:
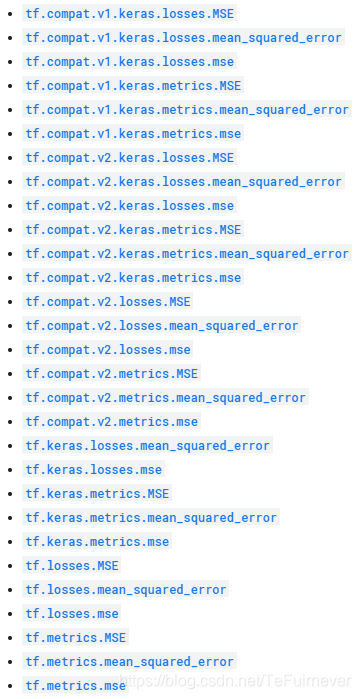
下面的示例为自定义的均方差损失函数:
class MeanSquaredError(tf.keras.losses.Loss):
def call(self, y_true, y_pred):
return tf.reduce_mean(tf.square(y_pred - y_true))
六、自定义评估指标
自定义评估指标需要继承 tf.keras.metrics.Metric 类,并重写 __init__ 、 update_state 和 result 三个方法。如果想要使用官方定义的评估指标,可以查询 https://tensorflow.google.cn/api_docs/python/tf/keras/metrics。
在 TensorFlow2.0 学习笔记(三):卷积神经网络(CNN) 中使用过如下评估指标:

可以通过调用函数 tf.keras.metrics.SparseCategoricalAccuracy 实现,或者还有其他写法:

下面的示例对 SparseCategoricalAccuracy 评估指标类做了一个简单的重实现:
class SparseCategoricalAccuracy(tf.keras.metrics.Metric):
def __init__(self):
super().__init__()
self.total = self.add_weight(name='total', dtype=tf.int32, initializer=tf.zeros_initializer())
self.count = self.add_weight(name='count', dtype=tf.int32, initializer=tf.zeros_initializer())
def update_state(self, y_true, y_pred, sample_weight=None):
values = tf.cast(tf.equal(y_true, tf.argmax(y_pred, axis=-1, output_type=tf.int32)), tf.int32)
self.total.assign_add(tf.shape(y_true)[0])
self.count.assign_add(tf.reduce_sum(values))
def result(self):
return self.count / self.total
七、Keras 概述
tf.keras 是 TensorFlow 对 Keras API 规范的实现,这可以使得你拥有使用 Keras 的机会,不至于牺牲掉 Keras 本身的灵活性和性能,使用如下语句进行 TensorFlow 程序设置的导入:
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
from tensorflow import keras
tf.keras 可以运行任何与 Keras 兼容的代码,但是要记得一下两件事:
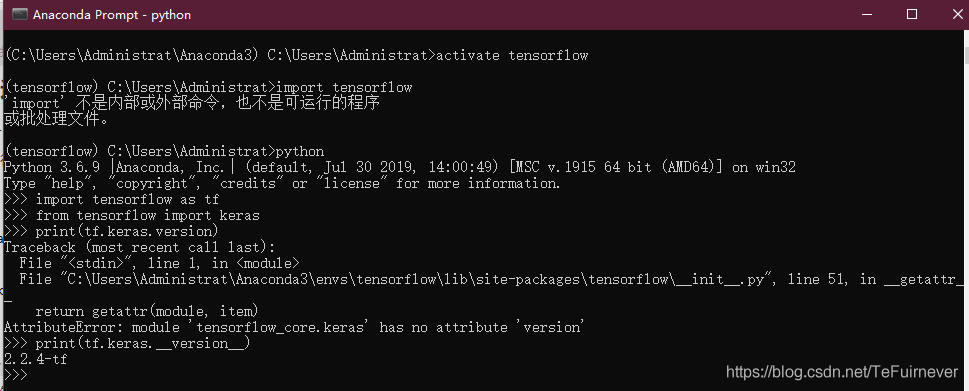
Tensorflow最新版本中的tf.keras版本可能与pypi中的最新Keras版本不同。你需要检查tf.keras.version,如下:
- 保存模型权重时,
tf.keras默认为checkpoint格式。使用save_format='h5'以使用HDF5格式(或以.h5结尾的文件名)。
近期会考虑在完成 TensorFlow2.0 和 pytorch 之后,完善 Keras 的教程,可以期待一下。
推荐阅读
- TensorFlow2.0 学习笔记(一):TensorFlow 2.0 的安装和环境配置以及上手初体验
- TensorFlow2.0 学习笔记(二):多层感知机(MLP)
- TensorFlow2.0 学习笔记(三):卷积神经网络(CNN)
- TensorFlow2.0 学习笔记(四):迁移学习(MobileNetV2)
- TensorFlow2.0 学习笔记(五):循环神经网络(RNN)
参考文章
- TensorFlow 官方文档
- 简单粗暴 TensorFlow 2.0