-
自定义模块
-
模块的两种执行方式
-
name fiile all
-
模块的导入方式
-
相对导入
-
random:随机数模块
-
random.random() 0——1之间的浮点数
-
random.uniform(a,b) a,b 之间的浮点数
-
random.randint(a,b) a,b之间的整数
-
random.shuffie(x) :打乱顺序
-
二、今日内容
常用模块介绍
-
time、datetime
-
os、sys
-
hashlib、json、pickle、cillections
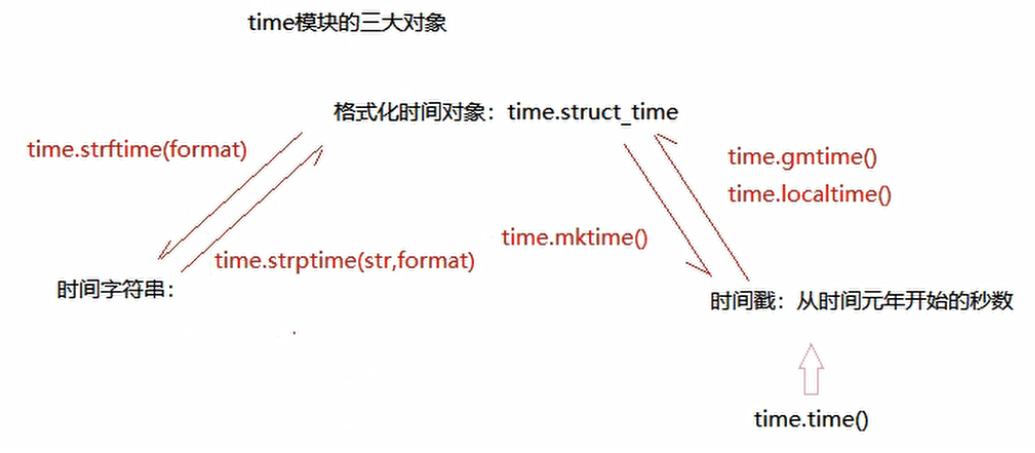
time:和时间相关
-
封装了获取时间戳和字符串形式的时间的一些方法
"""
time 模块
"""
import time
#如何获取一个时间戳
#时间戳:从时间元年 1970-01-01 00:00:00到现在经过的秒数
print(time.time())
#获取格式化时间对象
#默认参数是当前系统的时间戳
print(time.gmtime()) #time.struct_time(tm_year=2020, tm_mon=12, tm_mday=31, tm_hour=3, tm_min=17, tm_sec=13, tm_wday=3, tm_yday=366, tm_isdst=0)
print(time.localtime()) #time.struct_time(tm_year=2020, tm_mon=12, tm_mday=31, tm_hour=11, tm_min=17, tm_sec=31, tm_wday=3, tm_yday=366, tm_isdst=0)
#格式化时间对象和字符串时间的转换 strftime(时间格式,时间戳)
#时间戳不写,代表当前时间
s = time.strftime('%Y-%m-%d %H:%M:%S')
print(s) #2020-12-31 11:35:14
#把时间字符串转换成时间对象
time_obj = time.strptime('2020-10-10','%Y-%m-%d')
print(time_obj) #time.struct_time(tm_year=2020, tm_mon=10, tm_mday=10, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=5, tm_yday=284, tm_isdst=-1)
#time.sleep
for i in range(10):
print(time.strftime("%Y-%m-%d %H:%M:%S"))
time.sleep(1)
datetime :与计算相关
"""
datetime日期时间模块
封装了一些和日期、时间相关的类
date类
time类
timedalta类
"""
import datetime
# date 类
d = datetime.date(2020,10,10)
print(d) #2020-10-10
#其他操作方式
print(d.year)
print(d.month)
print(d.day)
# time类
t = datetime.time(12,0,0)
print(t)#12:00:00
#其他操作方式
print(t.hour)
print(t.minute)
print(t.second)
# datetime.timedelta的操作 主要是用于数学运算
td = datetime.timedelta(days = 1)
print(td)
d = datetime.date(2020,10,10)
res = d +td
print(res) #2020-10-11
t = datetime.datetime(2020,10,10,12,59,59)
td1 = datetime.timedelta(seconds = 3)
res1 = t + td1
print(res1) #2020-10-10 13:00:02
"""
只能和以下三种进行计算:datetime、date、timedelta
"""
json模块
-
已经成为一种简单的数据交换格式。
-
将数据转换成字符串,用于存储或网络传输
-
序列化:将内存中的数据转换成字节串保存文件或通过网络传输。
-
反序列化:从文件或网络中获取的数据,转换成内存当中原来的数据类型。
-
元组序列化后,变成列表
-
#序列化内存中
s = json.dumps([1,2,3])
print(s)
print(repr(s)) #真实的值 '[1, 2, 3]' -
#序列化到文件中
with open("a.txt",encoding="utf-8",mode="a") as f1:
json.dump([1,2,3],f1) -
#反序列化到内存中
res = json.dumps([1,2,3])
lst = json.loads(res)
print(lst) -
#从文件中反序列化
with open("a.txt",encoding="utf-8",mode="r") as f1:
res = json.load(f1)
print(res)
print(type(res)) -
json文件(文本文件) 通常一次性写,一次性读
-
使用其他方式可以实现多次读,多次写
pickle模块
-
定义:
-
将python中的所有数据类型转换成字节串,序列化过程
-
将字节串转换成python中的数据类型,反序列化过程
-
一次性写入一次性读取(最好不要多次写入,多次多写)
-
-
import pickle
# bys = pickle.dumps([1,2,3])
# print(bys) #b'x80x03]qx00(Kx01Kx02Kx03e.'
#元组可以转换成自身的数据类型
# bys = pickle.dumps((1,2,3))
# print(bys)
# res = pickle.loads(bys)
# print(res)
#集合
# bys = pickle.dumps(set('fhdjs'))
# print(bys)
# res = pickle.loads(bys)
# print(res)
#把pickle序列化内容写入文件中
# with open("c.txt",mode="ab") as f1:
# for i in range(5):
# pickle.dump([1, 2, 3], f1)
# #从文件当中反序列化数据
with open("c.txt",mode="rb") as f1:
for i in range(5):
res = pickle.load(f1)
print(res)
json与pickle的对比

hashlip模块
-
定义:封装一下用于加密的类
-
md5()
-
用于判断和验证,而并非解密
-
特点
-
把一个大数据,切分成不同的小块,分别对不同的快加密,汇总后,和直接对大数据进行加密结果是一致的
-
单向加密,不可逆
-
原始数据的变化,可导致加密结果差异非常大
"""
md5加密算法
"""
#给一个数据加密的三大步骤:
import hashlib
#获取加密对象
m = hashlib.md5()
#使用加密对象的update进行加密 :加密的对象是一个bytes类型,可以调用多次
m.update("abc中国".encode("utf-8")) #2b508b2a9ce59618f1f89a400277510f
m.update("dhf".encode("utf-8"))
res = m.hexdigest()
print(res) #5cef4d9effecd8d23a80500701df3225 -
-
可以给加密内容加盐
"""
md5加密算法
"""
#给一个数据加密的三大步骤:
import hashlib
#获取加密对象
m = hashlib.md5(b'fhdjsja') # 加盐
#使用加密对象的update进行加密 :加密的对象是一个bytes类型,可以调用多次
m.update("abc中国".encode("utf-8")) #2b508b2a9ce59618f1f89a400277510f
m.update("dhf".encode("utf-8"))
res = m.hexdigest()
print(res) #5cef4d9effecd8d23a80500701df3225
collections模块
-
定义:
-
namedtuple():命名元组
-
defaultdict():默认字典
-
Conunter():计数器
-
-

三、总结