欢迎关注个人公众号摸鱼范式,后台回复pdf获得全文的pdf文件

)
Hardware Description Languages
Verilog
[159] verilog中的阻塞赋值和非阻塞赋值有什么区别?
verilog支持阻塞与非阻塞两种赋值方式。使用阻塞赋值时,计算和赋值会立刻执行。因此但是顺序执行块中由多个阻塞赋值,他们会按照阻塞的方式顺序执行。如下所示。
always @(posedge clk)
begin
x = a|b;
y = a&b;
z = x|y;
end
在这个例子中,所有赋值都采用的时阻塞赋值,执行时会立刻进行计算,然后完成赋值操作。因此在第三条语句中,会将前两条语句中更新后的x和y用于第三条语句的计算并赋值。
在非阻塞赋值中,所有的赋值都将在当前的仿真时刻的最后执行。首先对右侧的表达式进行计算,然后才对左侧进行赋值,因此在下面的例子中,三条语句都先进行右侧语句的计算,然后再一起对左侧进行赋值操作。结果就是,第三条语句所采用的x和y是一个旧值,并不是前两条语句在这个仿真时刻改变后的值。
always @(posedge clk)
begin
x <= a|b;
y <= a&b;
z <= x|y;
end
[160] 下面的两个例子综合时需要多少个Flip-Flop?
1)
always @(posedge clk)
begin
B = A;
C = B;
end
2)
always @(posedge clk)
begin
B <= A;
C <= B;
end
1)一个;2)两个
第一种情况下,A的值赋予B,B更新后的值在同一个周期将赋予C,因此只需要一个触发器即可
第二种情况下,B更新后的值,在下一个周期才能赋予C,需要两个触发器实现
[161] 下列代码的输出是什么?
always @(posedge clk)
begin
a = 0;
a <=1;
$display("a=%0b", a);
end
由于非阻塞赋值只能在周期结束生效,而display语句打印的是当前值,所以结果是a=0。
[162] 编写verilog代码,交换两个寄存器的值,并且不使用中间寄存器
always @(posedge clk)
begin
A<=B;
B<=A;
end
[163] 下列代码的输出是?
module test;
int alpha,beta;
initial begin
alpha = 4;
beta = 3;
beta <= beta + alpha;
alpha <= alpha + beta;
alpha = alpha - 1;
$display("Alpha=%0d Beta=%0d", alpha,beta);
end
endmodule
这些赋值在一个没有任何时钟的initial块中,所以非阻塞赋值是不起作用的,因此只关心阻塞赋值。结果是:Alpha=3 Beta=3
[164] 下列两种情况下c的值会是多少(五个时间单位后)?
1)
initial begin
a=0;
b=1;
c = #5 a+b;
end
2)
initial begin
a=0;
b=1;
#5 c = a+b;
end
initial begin
a=0;
#3 a=1;
end
- c=1
- c=2
第一种情况下,c=a+b,但是需要五个时间单位的延迟以后才完成赋值
第二种情况下,在c=a+b赋值完成之前,另一个initial块中,第三个时间单位时,修改了a的值,所以在计算a+b时,a=1,因此最终结果为2
[165] 分析下面的代码,找出代码的错误
bit a, b, c, d, e;
always @(a, b, c) begin
e = a & b & c & d;
end
敏感列表缺失了d,这会导致仿真结果错误,而综合结果可能是正确的
[166] 编写verilog模块,使用“?:”运算符实现3:1mux
module mux31_2(inp0,inp1,inp2,sel0,sel1, outres);
input inp0, inp1, inp2, sel0, sel1;
output outres;
assign outres = sel1 ? inp2 : (sel0 ? inp1 : inp0);
endmodule
[167] 用下列两段代码进行建模,这两种代码风格有什么问题?
always @(posedge clk or posedge reset)
if (reset)
X1 = 0; // reset
else
X1 = X2;
always @(posedge clk or posedge reset)
if (reset)
X2 = 1;// set
else
X2 = X1;
verilog仿真器并不能保证always块的执行顺序,在上面的代码中,由于使用了阻塞赋值,因此会导致竞争现象。如果我们使用不同的仿真器,always块的执行顺序不同可能会导致不同的结果。推荐使用非阻塞赋值。
[168] 同步复位和异步复位之间有什么区别?如何使用verilog进行同步复位和异步复位建模?
上电以后,使用复位进行状态设定为一个确定状态。如果对复位在时钟的边沿进行采样,那么就是同步复位。如果不依赖于时钟边沿进行复位采用,则为异步复位。
下面的代码为同步复位
always @ (posedge clk) begin
if (reset) begin
ABC <=0;
end
end
下面的代码为异步复位
always @ (posedge clk or posedge reset ) begin
if (reset) begin
ABC <=0;
end
end
[169] “==”和“===”有什么区别?
两者都是相等或比较运算符。“==”测检查二值逻辑相等,而“===”运算符测试四值逻辑相等。
使用“==”比较四值逻辑,如果出现X或者Z,则结果为X。
使用“===”比较四值逻辑,如果出现X或Z,则结果为0或1,能够正确的进行比较。
[170] 如果A和B是两个3bit的变量:A = 3'b1x0 B = 3'b1x0 ,那么1)A==B 2)A===B的结果分别是?
- A==B只能判断非X/Z,出现X或Z,最后的结果为X
- A===B能够判断X/Z,结果为1
[171] 用verilog建模Latch和Flip-Flop,并解释他们的不同
Flip-Flop,在时钟上下沿进行采样。Latch,在使能时,一直进行采样,输出跟随输入
D触发器
always @ (posedge clk) begin
if(reset) begin
Q <= 0;
Qbar <= 1;
end else begin
Q <= D;
Qbar <= ~D;
end
end
锁存器
always @ (D or Enable) begin
if(Enable) begin
Q <= D;
Qbar <= ~D;
end
end
[172] 编写verilog代码,检测序列10110
首先设计状态机。
- 没有检测到序列
- 检测到1
- 检测到10
- 检测到101
- 检测到1011
状态机如下

module seq_detector(z,x,clock,reset);
output z;
input x,clock;
input reset; //active high
reg [2:0] state,nextstate;
parameter s0=3'b000,s1=3'b001,s2=3'b010,s3=3'b011,s4=3'b100;
always @ (posedge clock) begin
if(reset) begin
state <=s0;
nextstate<=s0;
end else begin
state<=nextstate;
end
end
always @ (x or state)
case(state)
s0: if(x) nextstate=s1; else nextstate=s0;
s1: if(x) nextstate=s1; else nextstate=s2;
s2: if(x) nextstate=s3; else nextstate=s0;
s3: if(x) nextstate=s4; else nextstate=s2;
s4: if(x) nextstate=s1; else nextstate=s2;
endcase
always @ (x or state)
case(state)
s4: if(x) z=1'b0; else z=1'b1;
s0,s1,s2,s3: z=1'b0;
endcase
endmodule
[173] 写一段verilog代码,根据输入的n计算斐波那契数列
斐波那契数列是一种数列,每一项是通过将前两项相加而得到的。 从0和1开始,顺序为0、1、1、2、3、5、8、13、21、34,依此类推。 通常,表达式为xn = xn-1 + xn-2。 假设最大值n = 256,以下代码将生成第n个斐波那契数。 值“n”作为输入传递给模块(nth_number)
module fibonacci(input clock, reset, input [7:0] nth_number, output [19:0] fibonacci_number, output number_ready);
reg [19:0] previous_value, current_value;
reg [7:0] internal_counter;
reg number_ready_r;
always @(posedge clock or posedge reset) begin
if(reset) begin
previous_value <='d0; //1st Fibonacci Number
current_value <='d1; //2nd Fibonacci Number
internal_counter <='d1;
number_ready_r <= 0;
end else begin
if (internal_counter == (nth_number-2)) begin
number_ready_r <= 1;
end else begin
internal_counter <= internal_counter + 1;
current_value <= current_value + previous_value;
previous_value <= current_value;
number_ready_r <= 0;
end
end
end
assign fibonacci_number = current_value;
assign number_ready = number_ready_r
endmodule
[174] 写一段verilog代码,用半加器组成全加器
module half_adder(input_0, input_1, sum, carry);
input input_0, input_1;
output sum, carry;
assign sum = (input_0)^(input_1);
assign carry = (input_0)&(input_1);
endmodule
module full_adder(input_0, input_1, input_2, sum, carry);
input input_0, input_1, input_2;
output sum, carry;
reg sum_intermediate, carry_intermediate_0, carry_intermediate_1;
half_adder ha1(input0,input1,sum_intermediate,carry_intermediate_0);
half_adder ha2(sum_intermediate,input2,sum,carry_intermediate_1);
assign carry = (carry_intermediate_0)|(carry_intermediate_1);
endmodule
[175] verilog中的task和function有什么区别?
- function不能使用任何延时语句,task可以
- 由于1中的原因,function可以调用function,但是不能调用task。task可以调用task和funtion
- funtion可以综合,task不可以
- function需要有通过返回参数作为输出,但是有多个输入输出参数。task不能返回任何值,但是具有多个输入或者输出参数。
SystemVerilog
[176] systemverilog中的reg,wire和logic有什么区别?
reg和wire是Verilog中就存在的两种数据类型,而logic是SystemVerilog中引入的新数据类型。
- wire是一种数据类型,可以对物理导线进行建模以连接两个元素。 导线只能由连续赋值语句驱动,如果不驱动,则无法保持值。 因此,wire只能用于对组合逻辑进行建模。
- reg是可以为存储数据或状态建模的数据类型。 它们需要由always块驱动,而不能由连续赋值语句驱动。 reg可用于建模顺序逻辑和组合逻辑。
- logic是SystemVerilog中的一种新数据类型,可用于wire和reg建模,也是四值逻辑,可以被用作reg也可以wire。
[177] bit和logic有什么区别?
bit是只能存储0和1的二值逻辑,而logic能够储存0、1、X和Z的四值逻辑。
二值逻辑能够加速仿真速度,而如果用二值逻辑用于驱动或者采样来自RTL的信号,会导致错误采样X和Z
[178] logic[7:0] 和 byte 有什么区别?
byte是有符号类型,最大为127,而logic可以被声明为无符号,最大可以达到255.
[179] 动态数组和关联数组,哪个更加适合模拟大型数组?例如32KB的巨大内存数组
关联数组更加适合用于大型数组的建模,因为只有在讲元素写入数组时才分配内存。而动态数组需要在使用之前分配和初始化内存。例如:如果要使用动态数组对32KB的内存数组进行建模,则首先需要分配32K的空间用于读/写。但是由于关联数组内部使用哈希进行元素的搜索,所以速度也是最慢的。
[180] 有一个动态数组通过下列代码进行初始化,写一段代码找出数组中所有大于3的元素
int myvalues [] = '{9,1,8,3,2,4,6},
int match_q[$];
match_q = myvalues.find with (item > 3);
[181] systemverilog中的union和struct有什么区别?
struct表示不同数据类型的集合。 例如:在下面的示例中,我们定义了一个名为instruction_s的struct,该struct由24位地址和8位操作码构成。
typedef struct {
bit [7:0] opcode;
bit [23:0] addr;
} instruction_s;
instruction_s current_instruction;
current_instruction.addr='h100;
可以直接引用instruction_s,也可以单独引用成员。存储struct所需的内存空间为成员之和,例如instruction_s需要32bit的空间。
union是一种数据类型,可以使用有且只有一种命名成员数据类型来访问它。 与struct不同,不能访问所有成员数据类型。 分配给union的内存将是成员数据类型所需的最大内存。 如果要对诸如寄存器之类的硬件资源建模,该寄存器可以存储不同类型的值,则union很有用。 例如:如果寄存器可以存储整数和实数值,则可以按以下方式定义union:
typedef union {
int data;
real f_data;
}state_u;
state_u reg_state;
reg_state.f_data = 'hFFFF_FFFF_FFFF_FFFF;
$display(" int_data =%h", reg_state.data);
在此示例中,state_u可以保存32位整数数据,也可以保存64位实数数据。 因此,为reg_state分配的内存将为64bit(两种数据类型中的较大者)。 由于所有成员数据类型都有共享内存,因此在上面的示例中,如果我们将64位值分配给reg_state.f_data,则我们也可以使用其他数据类型引用相同的32位。
[182] systemverilog的function和task中“ref”和“const ref”是什么意思?
ref关键字用于通过引用而不是值的方式传递参数。 子例程/函数与调用者共享句柄以访问值。 这是传递诸如类对象或对象数组之类的参数的有效方法,否则创建副本将消耗更多内存。 同样,由于调用方和function/task共享相同的引用,因此使用ref在函数内部完成的任何更改也对调用方可见。
例如:这是一个CRC函数的示例,该函数需要一个大数据包作为参数来计算CRC。 通过作为参考传递,每次调用CRC函数都不需要在存储器上创建数据包的副本。
function automatic int crc(ref byte packet [1000:1] );
for( int j= 1; j <= 1000; j++ ) begin
crc ^= packet[j];
end
endfunction
const关键字用于禁止函数修改传递的参数。例如:在同一个CRC函数中,可以将参数声明为“const ref”参数,如下所示,以确保原始数据包内容不会被CRC函数意外修改。
function automatic int crc(const ref byte packet [1000:1] );
for( int j= 1; j <= 1000; j++ ) begin
crc ^= packet[j];
end
endfunction
[183] 下面代码中参数a和b的方向是什么?
task sticky(ref int array[50], int a, b);
function和task的每一个参数都有他的方向,input,ouput,inout或者ref。如果没有显式声明,则默认与前面的参数保持一致,如果前面没有参数,则默认为输入。上述代码中,第一个参数array的方向为ref,而后续a和b没有显式声明,所以将延续前者的方向,即为ref。
[184] 压缩数组和非压缩数组的区别是?
压缩数组表示一组连续的bit,而非压缩数组不是。在声明上,有下面的区别
bit [7:0] data ; // packed array of scalar bit types
real latency [7:0]; // unpacked array of real types
压缩数组只能由一位数据类型(bit,logic,reg)或枚举类型组成。非压缩数组能够由任意类型组成
logic[31:0] addr; //packed array of logic type
class record_c;
record_c table[7:0]; //unpacked array of record objects
[185] packed struct和unpacked struct的区别是什么?
压缩结构体是一种可以将压缩位向量作为结构成员进行访问的方法。 换句话说,如果struct的所有成员仅由位字段组成并且可以无间隙地打包在内存中,则它可以是压缩结构。 例如:在下面的struct定义中,所有成员都可以表示为位向量(int等于32位,short int到16位,byte到8位),并且一个struct可以打包到单个连续内存56bit。
struct packed {
int a;
short int b;
byte c;
} pack1_s;
非压缩结构体不需要打包到连续的bit位中,因此在不同成员之间可以存在空隙。下面是一个无法压缩的结构体。
struct {
string name;
int age;
string parent;
} record_s
[186] 下面哪个是对的?
-
function不能消耗仿真时间
-
task不能消耗仿真时间
-
正确
-
错误
[187] 现有一个动态数组的大小为100,如何把他的大小定义为200,并且前100个元素为原来的数组?
动态数组使用new[]进行保留元素的内存分配。
integer addr[]; // Declare the dynamic array.
addr = new[100]; // Create a 100-element array.
………
// Double the array size, preserving previous values.
addr = new[200](addr);
[188] systemverilog中case,casex和casez的区别是?
case语句是选择语句,匹配表达式并执行对应的语句。下面是一个3:1MUX
case (select[1:0])
2'b00: out_sig = in0;
2'b01: out_sig = in1;
2'b10: out_sig = in2;
default: out_sig = 'x;
endcase
上面的例子中,如果表达式与指定的内容完全匹配,则执行后续语句,如果出现x或者z,将执行默认语句。
casez是case的一个特殊版本,通常在处理较少位的译码器中使用。下面的示例中,将3位中断申请队列解码位三个独立的中断引脚,只关心对应位,而其他位无关紧要。带有优先级。
casez (irq)
3'b1?? : int2 = 1'b1;
3'b?1? : int1 = 1'b1;
3'b??1 : int0 = 1'b1;
endcase
“ casex”是另一个特殊版本,除了无关项,在比较中它也忽略X和Z值。
[189] 在case、casez、casex中使用的是==还是===?
三者使用的都是===
[190] systemverilog中的display,write,monitor和strobe用什么区别?
- $display:执行时立刻打印内容
- $strobe:在当前的timestep结束时打印内容
- $monitor:在timestep结束时,如果内容改变了,则进行打印。如果多次调用,则新的覆盖旧的。
- $write:和$display一样,但是不会在结尾打印换行符
[191] 下面的systemverilog代码中有什么错误?
task wait_packet;
Packet packet;
event packet_received;
@packet_received;
packet = new();
endtask
function void do_print();
wait_packet();
$display("packet received");
endfunction
function中不能使用任何延时语句。上面的例子中,function调用了一个耗时的task,这是非法的。
[192] systemverilog中new()和new[]有什么区别?
new()时systemverilog中类的构造函数。他在类中定义,并初始化对象。
new[]用于动态数组的内存分配。
[193] 什么是systemverilog中的前置声明?
有时候,一个类有可能引用另一个尚未编译的类,这会导致编译错误。例如,如果按照下面的顺序编译Statistics和Packet,由于在编译Statistics时,Packet尚未定义,编译器将为报错。
class Statistics;
Packet p1;
endclass
class Packet; //full definition here
endclass
为了避免这个问题,类在完全定义之前,可以先进行前置声明。
typedef Packet; //forward declaration
class Statistics;
Packet p1;
endclass
class Packet; //full definition here
endclass
[194] 下面代码有什么问题?
task gen_packet(Packet pkt);
pkt = new();
pkt.dest = 0xABCD;
endtask
Packet pkt;
initial begin
gen_packet(pkt);
$display(pkt.dest);
end
这段代码在运行时,会产生空指针错误。task传入pkt句柄,而在内部为句柄创建了一个对象。在initial块中,调用了gen_packet,并修改了pkt.dest,但是对于task来说这些都是局部的。task的默认方向是input,在内部的修改句柄的指向并不能影响外部,尽管在task内部进行了对象例化并且修改了值,而实际上外部的pkt始终是空句柄。
[195] systemverilog中,类成员的private、public和protect属性是什么意思?
- private成员只允许在class内部进行访问。这些成员在派生类中也是不可见的。
- public成员在class内外都可以进行访问。这些成员在派生类中是可见的。
- protect成员只允许在class内部进行访问。这些成员在派生类中是可见的。
[196] systemverilog的类中,成员变量默认是public还是private?
与C++和Java中不一样,systemverilog的类成员默认为public。
[197] 什么是嵌套类?何时使用他?
当一个类的定义包含另一个类的定义,则该类为嵌套类。例如,下面代码中,StringList类定义包含另一个类Node的定义。
class StringList;
class Node; // Nested class for a node in a linked list.
string name;
Node link;
endclass
endclass
嵌套允许隐藏本地名称和资源的本地分配。 当需要新的类作为类实现的一部分时很有用。
[198] systemverilog中的interface是什么?
systemverilog中的接口用于将多个线网进行捆绑,有助于封装设计块之间的接口通信。接口可以在设计中实例化,并且可以使用单个名称进行连接,不需要显式声明所有的端口和连接。除了用于连接,接口内部还可以定义function,可以通过实例化接口调用function。接口还支持过程块和assign,这些对于协议检查和断言非常有用。下例是一个接口的简单示例:
interface simple_bus; // Define the interface
logic req, gnt;
logic [7:0] addr, data;
logic [1:0] mode;
logic start, rdy;
endinterface: simple_bus
[199] 什么是modport?
modport(模块端口的缩写)是接口中的一种构造,可用于分组信号并指定方向。 以下是如何使用Modport将接口进一步分组以连接到不同组件的示例。
interface arb_if(input bit clk);
logic [1:0] grant, request;
logic reset;
modport TEST (output request, reset, input grant, clk);
modport DUT (input request, reset, clk, output grant);
modport MONITOR (input request, grant, reset, clk);
endinterface
上面的示例中,相同的信号在不同的modport中具有不同的方向。
[200] interface是可综合的吗?
是可综合的。
[201] 什么是时钟块?在interface中使用时钟块有什么好处?
时钟块类似于modport,除了具备modport的信号方向指定,还能够建模信号的时序行为。下面是一个时钟块的例子。
clocking sample_cb @(posedge clk);
default input #2ns output #3ns;
input a1, a2;
output b1;
endclocking
在上面的示例中,定义了一个名为sample_cb的时钟块,关联的时钟为clk。default关键字定义默认的时钟偏斜,输入为2ns,输出为3ns。输入偏斜定义了时钟采样在时钟边沿前多少个时间单位。 输出偏斜定义了时钟驱动在时钟边沿后的多少个时间单位。
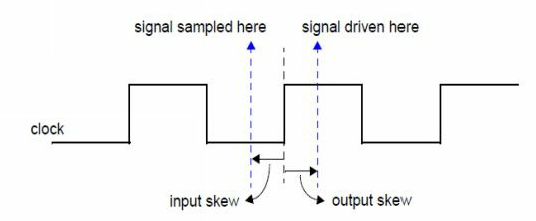
时钟块只能在module或者interface中定义
[202] 下面两种定义时钟偏斜的方式有什么不同?
1) input #1 step req1;
2) input #1ns req1;
定义时钟偏斜有两种方式
- 以time step为单位,这是由全局的时间精度定义的,即`timescale
- 之间指明具体的时间长度
[203] systemveirlog仿真里在一个timestep中有哪些主要的阶段?
systemverilog仿真器是事件驱动的仿真器,明确定义了不同的阶段来计划和执行所有事件。在仿真中,所有的事件都以timeslot为单位进行。timeslot被划分为一组有序阶段,提供设计和测试代码之间的可预测交互。如下图所示,一个timeslot可以划分为五个主要阶段,每个阶段都可以进一步的被划分为细分的子阶段。
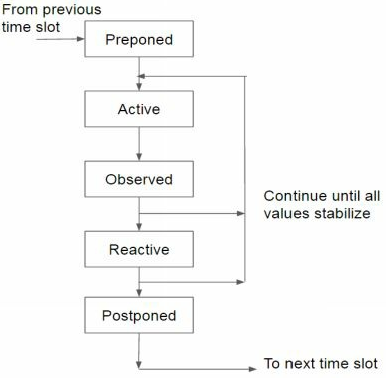
- Prepone:这是timeslot最先执行的阶段,并且只执行一次。来自测试平台对设计信号的采样发生在这个阶段。
- Active:Active阶段包括三个子阶段:Active,Inactive和NBA(Nonblocking assignment)阶段.RTL代码和行为代码在Active阶段执行。阻塞赋值在Active阶段执行。非阻塞赋值,RHS的计算在Active阶段执行,赋值操作在NBA阶段执行。如果由#0的赋值行为,则在inactive阶段执行。
- Observed:Observed用于计算property(并发断言中)表达式的触发行为。在property计算期间,通过或者失败的调度会在当前timeslot的Reactive阶段进行。
- Reactive:Reactive阶段包括三个子阶段:Re-Active,Re-Inactive和Re-NBA(Re-Nonblocking assignment)阶段。用于执行systemverilog中program块的阻塞赋值,#0阻塞赋值,非阻塞赋值。这个独立的响应阶段确保在测试代码执行之前,设计代码的状态已经稳定。使用OVM/UVM不需要程序块,因此Reactive阶段可能使用得不多。
- Postponed:Postponed阶段是当前timeslot的最后一个阶段。$monitor,$strobe和其他类似的事件在此区域执行。而$dislpay事件在Active 和 Reactive(如果在program块中调用)阶段执行
[204] 根据下面的约束,哪一个选项是错误的?
rand logic [15:0] a, b, c;
constraint c_abc {
a < c;
b == a;
c < 30;
b > 25;
}
- b可以取26-29之间的任意值
- c可以取0-29之间的任意值
- c可以取26-29之间的任意值
将约束内容取交集,c可以取27-30之间的任意值。
[205] 什么是systemverilog中的unique约束?
unique约束会令一组成员两两各不相同。下面是一个示例。
class Test;
rand byte a[5];
rand byte b;
constraint ab_cons { unique {b, a[0:5]}; }
endclass
[206] 如何选择性的激活或者关闭一个类中的约束?
//<object>.constraint_mode(0) :: 关闭对象中的所有约束
//<constraint>.constraint_mode(0) :: 选择性关闭某一个约束
class ABC;
rand int length;
rand byte SA;
constraint c_length { length inside [1:64];}
constraint c_sa {SA inside [1:16];}
endclass ABC abc = new();
abc.constraint_mode(0) // 关闭所有约束
abc.c_length.constraint_mode(0) // 只关闭约束c_length
[207] 现有下面的一个类,如何生成addr大于200的Packet对象?
class Packet;
rand bit[31:0] addr;
constraint c_addr { addr inside [0:100];}
endclass
大于200与内置约束冲突,所以需要先关闭内置约束,然后通过内联约束进行随机化
Packet p = new();
p.c_addr.constraint_mode(0);
p.randomize with {addr > 200;};
[208] 什么是pre_randomize()和post_randomize()函数?
这显示systemverilog内建的回调函数。在调用randomize之前会自动调用pre_randomize函数,之后会自动调用post_randomize函数。可以通过定义这两个函数,完成在随机化之前或者之后进行某些操作。
[209] 编写一个约束,为下面对象中的动态数组生成约束,使得每个元素都小于10,数组大小也小于10
class dynamic_array;
rand unsigned int abc[];
endclass
constraint c_abc_len {
abc.size() < 10;
foreach (abc[i])
abc[i] < 10;
}
[210] 编写约束,创建随机整数数组,使数组大小在10-16之间,并且数组按照降序排列
class array_abc;
rand unsigned int myarray[];
endclass
constraint c_abc_val {
myarray.size inside { [10:16] };
foreach (myarray[i])
if (i>0) myarray[i] < myarray[i-1];
}
[211] 如何对一个生成一个随机动态数组,并且元素两两各不相同?参考下面的代码
class TestClass;
rand bit[3:0] my_array[];//dynamic array of bit[3:0]
endclass
- 使用unique进行约束
constraint c_rand_array_uniq {
my_array.size == 6; //or any size constraint
unique {my_array}; //unique array values
}
- 不适用unique进行约束,使用post_randomize回调函数完成
constraint c_rand_array_inc {
my_array.size == 6 ;// or any size constraint
foreach (my_array[i])
if(i >0)
my_array[i] > my_array[i-1];
}
function post_randomize();
my_array.shuffle();
endfunction
[212] “fork - join”, “fork - join_any” 和“fork - join_none”之间有什么区别?
systemverilog支持三种类型的动态进程,可以在运行时创建,并作为独立线程执行。
- fork-join:使用“ fork .. join”创建的进程作为单独的线程运行,但是父进程停滞不前,直到所有进程全部执行完。 如果我们看下面的示例:共有三个进程task1,task2和task3,它们将并行运行,并且只有在这三个进程全部完成之后,join语句之后的$display()才会执行。
initial begin
fork
task1; // Process 1
task2; // Process 2
task3; // Process 3
join $display(“All tasks finished”);
end
- fork-join_any:使用“ fork…join_any”创建的进程作为单独的进程运行,但是父进程会在任何一个子进程完成后继续。其余进程和父进程可以并行运行。 如果我们看下面的示例:有三个进程-task1,task2和task3将并行运行。 当task1 / task2 / task3之一完成时,join_any将完成,并在其他线程可能仍在运行时执行$ display()。
initial begin
fork
task1; // Process 1
task2; // Process 2
task3; // Process 3
join_any
$display(“Any one of task1/2/3 finished”);
end
- fork-join_none:使用“ fork…join_none”创建的进程将作为单独的进程运行,但是父进程不会停滞并且也将并行进行。 参考以下示例,其中有三个进程-task1,task2和task3,它们将与父进程并行运行。
initial begin
fork
task1; // Process 1
task2; // Process 2
task3; // Process 3
join_none
$display(“All tasks launched and running”);
end
[213] “wait fork”和“disable fork”的作用是什么?
在使用“ fork..join_none”或“ fork..join_any”时,有时候需要父进程和子进程进行同步,这可以通过wait fork完成。
initial begin
fork task1; // Process 1
task2; // Process 2
join_none
$display(“All tasks launched and running”);
wait fork;
$display(“All sub-tasks finished now”);
end
类似的,disable fork可以提前将子进程停止。
initial begin
fork
task1; // Process 1
task2; // Process 2
join_any
$display(“One of task1/2 completed ”);
disable fork;
$display(“All other tasks disable now”);
end
[214] 硬约束和软约束有什么区别?
systemverilog中编写的常规约束为硬约束,对成员的随机化必须始终满足约束,如果约束无解,则会导致错误。如果将约束定义为软约束,在没有外部约束的条件下,和硬约束一样,外部约束的优先级比软约束高。软约束通常用于指定随机变量的默认值和分布,并且可以被外部特定的约束覆盖。
class Packet;
rand int length;
constraint length_default_c {
soft length inside {32,1024};
}
endclass
Packet p = new();
p.randomize() with { length == 1512; }
上例中,如果约束没有定义为软约束,则随机化会失败。
[215] 下面每个线程的输出是什么?
initial begin
for (int j=0; j<3; j++) begin
fork
automatic int result;
begin
result= j*j;
$display("Thread=%0d value=%0d", j, value);
end
join_none
wait
fork;
end
end
由于“ j”不是每个线程的动态变量,因此在生成每个线程后它会不断递增,并且当所有线程开始执行时,每个线程将看到的j都是3。因此,每个线程都将输出9。 如果每个线程打算使用不同的值,则应将“ j”的值复制到一个自动变量,如下所示:
automatic int k = j;
begin
result = k*k;
end
[216] 下面的代码会产生多少个并行的线程?
fork
for (int i=0; i < 10; i++ ) begin
ABC();
end
join
for循环在fork join内,所以只有一个线程。
[217] 下面的约束有什么错误?
class packet;
rand bit [15:0] a, b, c;
constraint pkt_c { 0 < a < b < c; }
endclass
约束表达式中,至多只有一个关系运算符(<,<=,==,>=或>)。如果要实现变量的顺序约束,需要多个表达式。
constraint pkt_c { 0 < a; a < b ; b < c; }
[218] systemverilog中的虚方法和纯虚方法的区别是?
在类中将方法定义为虚方法,则在派生类中可以重写这个方法。基类可以定义具有实现或不实现的虚函数,在派生类中也可以选择覆盖或不覆盖。而纯虚函数只具备函数声明,没有具体实现,在派生类中必须有具体实现。纯虚函数常用在抽象类中使用,下面是一个示例。
virtual class BasePacket; // No implementation
pure virtual function integer send(bit[31:0] data);
endclass
class EtherPacket extends BasePacket;
virtual function integer send(bit[31:0] data);
// body of the function
// that implements the send
….…
endfunction
endclass
[219] 什么是Semaphores?何时使用?
Semaphores是用于控制对公用资源的机制。Semaphores可以视为在创建时具有多个钥匙的存储池,使用Semaphores访问资源时,首先要取得要是,然后才能够继续执行。通过这种机制,可以确保没有要是的进程一直等待到获取钥匙。Semaphores通常用于相互排斥,对公用资源进行访问控制以及简单同步。下面是简单的Semaphores的创建方法。
semaphore smTx;
smTx = new(1); //create the semaphore with 1 keys.
get()和try_get()分别是阻塞和非阻塞的获取钥匙的方法,put()用于返还钥匙。
[220] 下面两个约束有什么不同?
1)
class ABSolveBefore;
rand bit A;
rand bit [1:0] B;
constraint c_ab { (A==0) -> B==0; solve A before B; }
endclass
2)
class ABSolveBefore;
rand bit A;
rand bit [1:0] B;
constraint c_ab { (A==0) -> B==0; solve B before A; }
endclass
两种情况下,A都能取到0和1,B能取到0123,并且A为0时B都为0。但是求解顺序会导致两者的分布会不一致。
如果先求解A再求解B,那么概率分布表为
| A | B | 概率 |
|---|---|---|
| 0 | 0 | 0.5 |
| 0 | 1 | 0 |
| 0 | 2 | 0 |
| 0 | 3 | 0 |
| 1 | 0 | 0.5*0.25 |
| 1 | 1 | 0.5*0.25 |
| 1 | 2 | 0.5*0.25 |
| 1 | 3 | 0.5*0.25 |
如果先求解B再求解A,那么概率分布表为
| A | B | 概率 |
|---|---|---|
| 0 | 0 | 0.5*0.25 |
| 0 | 1 | 0 |
| 0 | 2 | 0 |
| 0 | 3 | 0 |
| 1 | 0 | 0.5*0.25 |
| 1 | 1 | 0.25 |
| 1 | 2 | 0.25 |
| 1 | 3 | 0.25 |
[221] 什么是mailbox?如何使用mailbox?
mailbox是一种通信机制,用于线程之间的数据交换。数据在一个线程存入mailbox中,在另一个线程中检索。下面是mailbox的声明与创建的示例:
mailbox mbxRcv;
mbxRcv = new();
将数据存入mailbox中可以使用put(阻塞)和peek(非阻塞)实现,从mailbox中取出数据可以使用get(阻塞)和try_get(非阻塞)方法,查询mailbox中的数据数量可以使用num()方法。
[222] 有限容量和无限容量的mailbox有什么区别?如何创建?
有限容量的mailbox是指邮箱在创建时就指定容量。
mailbox mbxRcv;
mbxRcv = new(10); //size bounded to 10
无限容量的mailbox是指邮箱再创建时不指定容量。
mailbox mbxRcv;
mbxRcv = new(); //size is unbounded or infinite
有限容量的mailbox如果存满,线程将无法继续存入数据,只到mailbox有空间。
[223] 什么是systemverilog中的event?如何触发event?
event类型的变量不用于存储数据,用于线程同步。可以使用"->"显式触发事件,而线程可以通过"@"来等待事件的触发,阻断线程只到事件被触发。event为两个或者多个同时运行的进程的同步提供强大而有效的手段。
下面的示例中,两个线程通过event进行同步。一旦发送请求,send_req()将会触发一个事件,而receive_response()检测到事件被触发以后就会继续执行任务。
module test;
event req_send;
initial begin
fork
send_req();
receive_response);
join
end
task send_req(); //create and send a req
-> req_send; //trigger event
endtask
task receive_response();
@req_send; //wait until a send event is triggered
//collect response
endtask
endmodule
[224] 如何合并两个event?
可以指将将一个event变量赋值给另一个event变量,此时两个event变量都指向同一个同步对象,可以认为两者合并。
[225] 什么是systemverilog中的std::randomize()方法?何时使用它?
std::randomize()是作用域随机化函数,无需定义类或者实例化类对象仅能对当前作用域中的数据进行随机化。如果某些需要随机化的变量不是类的成员,则需要使用std::randomize()。下面是一个示例。
module stim;
bit [15:0] addr;
bit [31:0] data;
function bit gen_stim();
bit success, rd_wr;
success = std::randomize(addr, data, rd_wr);
return rd_wr ;
endfunction
…
endmodule
std::randomize()和类的randomize()具有相似的功能,也可以使用约束,下面是一个通过with添加约束的示例。
success = std::randomize( addr, data, rd_wr ) with {rd_wr -> addr > 'hFF00;};
[226] 在派生类中可以覆盖基类中的约束嘛?如果可以,如何实现?
可以通过使用相同的约束名称在派生类中重写基类定义的约束。下面是一个示例
class Base;
rand int a ;
rand int b;
constraint c_a_b_const {a < b;}
endclass
class Derived extends Base;
constraint c_a_b_const {a > b;}
endclass
[227] 下面的systemverilog代码的调用有什么问题?
function int count_ones ( ref bit [9:0] vec );
for( count_ones = 0; vec != 0; vec = vec >> 1 )
begin
count_ones += vec & 1'b1;
end
endfunction
constraint C1 { length == count_ones( myvec ) ; }
在约束中,不允许调用方向为ref的函数,除非使用“const ref”,这保证函数在内部不会修改参数。
[228] 下面两个派生类有什么不同?
class Base;
virtual function printA();
endfunction
endclass
1)
class Derived extends Base;
function printA();
//new print implementation
endfunction
endclass
2)
class Derived extends Base;
virtual function printA();
//new print implementation
endfunction
endclass
两者并没有区别,在基类中如果定义了virtual关键字,那么派生类也会继承该属性,无论有没有显式的二次声明。
[229] 找出下面代码中的问题(如果有的话)
class Packet;
bit [31:0] addr;
endclass
class ErrPacket extends Packet;
bit err;
endclass
module Test;
initial begin
Packet p;
ErrPacket ep;
ep = new();
p = ep;
$display("packet addr=%h err=%b", p.addr, p.err);
end
endmodule
没有问题,基类句柄可以指向派生类对象,但是反过来是不允许的。
[230] 现有下面两个类,请问在示例代码中compute_crc函数的调用顺序是?
class Packet; //Base Class
rand bit [31:0] src, dst, data[8]; // Variables
bit [31:0] crc;
virtual function void compute_crc;
crc = src ^ dst ^ data.xor;
endfunction
endclass : Packet
class BadPacket extends Packet; //Derived class
rand bit bad_crc;
virtual function void compute_crc; //overriding definition
super.compute_crc(); // Compute good CRC
if (bad_crc) crc = ~crc; // Corrupt the CRC bits
endfunction
endclass : BadPacket
示例
Packet pkt;
BadPacket badPkt;
initial begin
pkt = new;
pkt.compute_crc; // 1) Which of compute_crc() gets called?
badPkt = new;
badPkt.compute_crc; // 2) Which of compute_crc() gets called?
pkt = badPkt; // Base handle points to ext obj
pkt.compute_crc; // 3) Which of compute_crc() gets called ?
end
- 调用了基类的compute_crc
- 调用了派生类的compute_crc
- 调用了派生类的compute_crc,虽然使用的是基类的句柄,但是方法定义为虚方法,所以要根据对象的类型进行调用
[231] 下面两种代码风格哪种更加好?为什么?
1)
for (i=0; i < length*count; i++) begin
a[i] = b[i];
end
2)
l_end = length * count;
for (i=0; i < l_end; i++) begin
a[i] = b[i]
end
2比1更好,在1中,每次迭代都需要计算length*count,2中只需要计算一次
[232] 下面的代码有什么错误?
class ABC;
local int var;
endclass
class DEF extends ABC;
function new();
var = 10;
endfunction
endclass
变量var具备local关键字,在派生类中是不可用的。
[233] 什么是虚接口,何时使用它?
虚接口是指向实际结构的变量。他在类中用于提供接口的连接点,通过虚接口可以访问接口中的信号。在下面的示例中,接口bus_if将多个信号整合起来。然后,BusTransactor类中定义了这一接口类型的虚接口,这个虚接口用于访问来自this.b_if的所有驱动或检测。实例化物理接口以后,通过构造函数将句柄传递给BusTransactor类。
interface bus_if; // A bus interface
logic req, grant;
logic [7:0] addr, data;
endinterface
class BusTransactor; // Bus transactor class
virtual bus_if bus; // virtual interface of type bus_if
function new( virtual bus_if b_if );
bus = b_if; // initialize the virtual interface
endfunction
task request(); // request the bus
bus.req <= 1'b1;
endtask
task wait_for_bus(); // wait for the bus to be granted
@(posedge bus.grant);
endtask
endclass
module top;
bus_if bif(); // instantiate interfaces, connect signals etc
initial begin
BusTransactor xactor;
xactor = new(bif); //pass interface to constructor
end
endmodule
[234] 工厂和工厂模式的意思是?
在面向对象编程中,工厂是用于创建原型或类的不同对象的方法或函数。不同的类在工厂中注册后,工厂方法可以通过调用相应的构造函数来创建任何已注册类类型的对象。创建对象不直接调用构造函数的模式称为工厂模式。使用基于工厂的对象创建而不是直接调用构造函数,允许在对象创建中使用多态性。这个概念是在UVM (Univers)中实现的。
[235] 回调函数(callback)的意义是什么?
“回调”是由另一个函数调用的任何函数,它以第一个函数为参数。大多数情况下,当某个“事件”发生时,会调用回调函数。在验证平台中,回调函数很多优点:
- 注入从驱动程序发送的事务错误
- 当一个模拟阶段准备结束时,调用一个函数来关闭所有序列/驱动程序中所有挂起的事务。
- 在一个特定的事件上调用一个覆盖率采样函数。
大多数情况下,回调函数是通过将它们注册到一个组件/对象中来实现的,该组件/对象会在某些定义的条件下回调。UVM中的phase_ready_to_end()就是回调函数,它在基类中实现,并注册到UVM_component类中。当当前仿真阶段准备结束时,将调用该函数。因此,用户可以通过覆盖此函数定义来实现需要在仿真阶段结束时执行的任何功能。
[236] 什么是DPI调用?
DPI是直接编程接口的缩写,它是SystemVerilog和C/C++等外语编程语言之间的接口。DPI允许在接口两边的语言之间直接进行跨语言函数调用。在C语言中实现的函数可以在SystemVerilog中调用(import),在SystemVerilog中实现的函数可以使用DPI层在C语言中调用(export)。DPI支持跨语言边界的function(零时间执行)和task(耗时执行)。SystemVerilog数据类型是惟一能够在任何方向上跨越SystemVerilog和外部语言之间的边界的数据类型。
[237] “DPI import” 和“DPI export”有什么区别?
import的DPI函数是用C语言实现并在SystemVerilog代码中调用的函数。
export的DPI函数是用SystemVerilog语言实现并导出到C语言的函数,这样就可以从C语言调用它。
函数和任务都可以导入或导出。
[238] 什么是系统函数?举例说明他们的作用
SystemVerilog语言支持许多不同的内置系统任务和函数,通常在任务/函数名称前加上“$”前缀。此外,语言还支持添加用户定义的系统任务和功能。下面是一些系统任务和功能的例子(根据功能分类)。对于完整的列表,可以参考LRM。
- 仿真控制函数 - ($finish), ($stop), ($exit)
- 转换函数 - ($bitstoreal), ($itor), ($cast)
- bit向量系统函数 - ($countones), ($onehot), ($isunknown)
- 安全系统函数 - ($error), ($fatal), ($warning)
- 采样值控制函数 - ($rose), ($fell), ($changed)
- 断言控制函数 - ($asserton), ($assertoff)