对于一个线性回归问题有
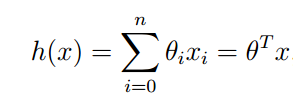
为了使得预测值h更加接近实际值y,定义
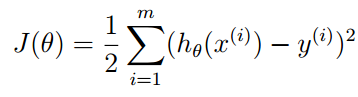
J越小,预测更加可信,可以通过对梯度的迭代来逼近极值
批梯度下降(batch gradient descent)(the entire training set before taking a single step)
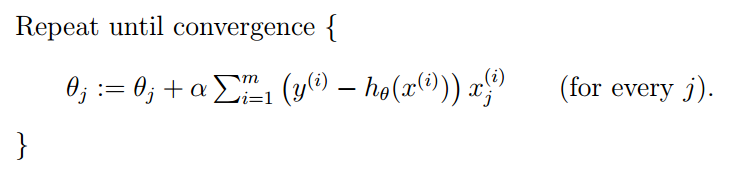
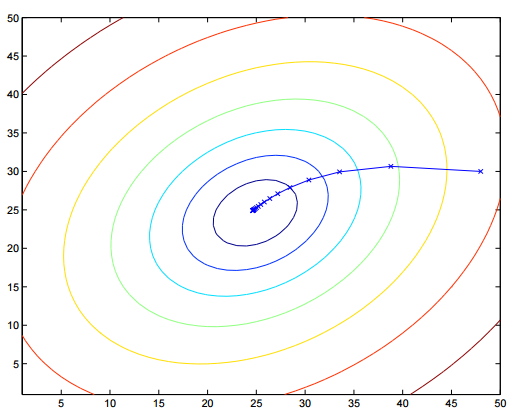
随机梯度下降(stochastic gradient descent)(gets θ “close” to the minimum much faster than batch gradient descent)
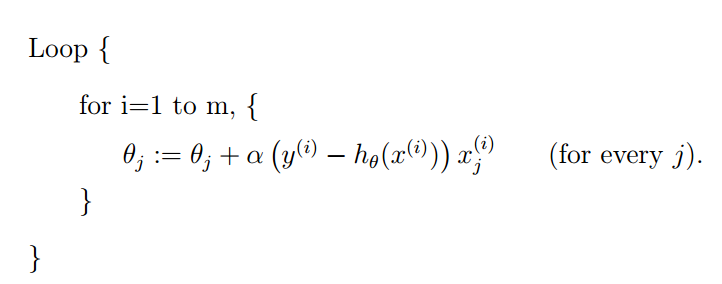
这里可以看到更详细的解释http://www.cnblogs.com/czdbest/p/5763451.html
也可以通过求J的梯度等于0向量来确定极值
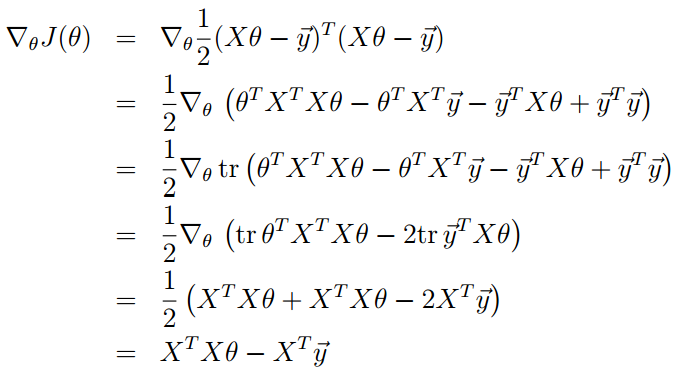
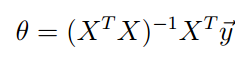
来自吴恩达机器学习