课本:第六章 进程的描述和进程的创建
- 操作系统内核实现操作系统的三大管理功能
- 进程管理
- 内存管理
- 文件系统
- 在操作系统原理中,通过进程控制块PCB描述进程;在Linux内核中,通过一个数据结构struct task_struct来描述进程。
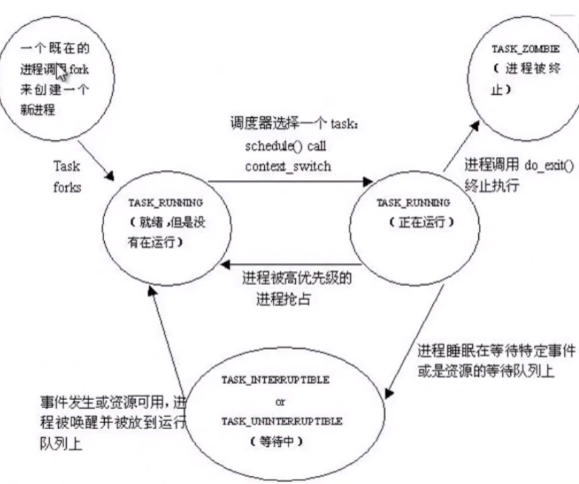
- 在操作系统原理中,进程有就绪态、运行态和阻塞态;在Linux内核中,就绪态和运行态都是相同的TASK_RUNNING状态另加上一个阻塞态。在Linux内核中,当进程是TASK_RUNNING状态时,它是可运行的,就是就绪态,是否在运行取决于它有没有获得CPU的控制权。
- 对于一个正在运行的进程,调用用户态库函数exit()会陷入内核执行该内核函数do_exit(),进程会进入TASK_ZOMBIE状态,即中止状态,Linux内核会在适当的时候把该进程处理掉,后释放进程描述符。一个正在运行的进程在等待特定事件或资源时会进入阻塞态,阻塞态分为两种:TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE。前者可以被信号和wake_up()唤醒,后者只能被wake_up()唤醒。进程状态转换图如下图所示:
- 在进程描述符中用pid和tgid标识进程。
- 在进程的创建时,0号进程init_task的初始化是通过硬编码方式固定下来的,除此之外,所有其他进程的初始化都是通过do_fork复制父进程的方式初始化的。
- Linux内核中,数据结构struct thread_struct用来保存进程上下文中CPU相关的一些状态信息,其内部最关键的是sp和ip,在x86-32位系统中,sp用来保存进程上下文中的ESP寄存器状态,ip用来保存进程上下文中的EIP寄存器状态。
- fork系统调用把当前进程又复制了一个子进程,也就一个进程变成了两个进程,两个进程执行相同的代码,只是fork系统调用在父进程和子进程中的返回值不同。
- fork、vfork和clone这三个系统调用和kernel_thread内核函数都可以创建一个新进程,而且都是通过do_fork函数来创建进程的,只不过传递的参数不同。
- do_fork函数的参数:
- clone_flags:子进程创建相关标志,通过此标志可以对父进程的资源进行有选择的复制。
- stack_start:子进程用户态堆栈的地址。
- regs:指向pt_regs结构体的指针。当发生系统调用时,int指令和SAVE_ALL保存现场等会将CPU寄存器中的值按顺序压入内核栈。为了便于访问操作,这部分数据被定义为pt_regs结构体。
- stack_size:用户态栈的大小,通常不必要,设置为0。
- parent_tidptr和child_tidptr:父进程、子进程用户态下的pid地址。
- 进程的创建中几个关键函数:
- do_fork():创建进程
- copy_process():创建进程内容(调用dup_task_struct、信息检查、初始化、更改进程状态、复制其他进程资源、调用copy_thread初始化子进程内核栈、设置子进程pid等)
- dup_task_struct():复制当前进程(父进程)描述符task_struct,分配子进程内核栈
- copy_thread():内核栈关键信息初始化
实验:分析Linux内核创建一个新进程的过程
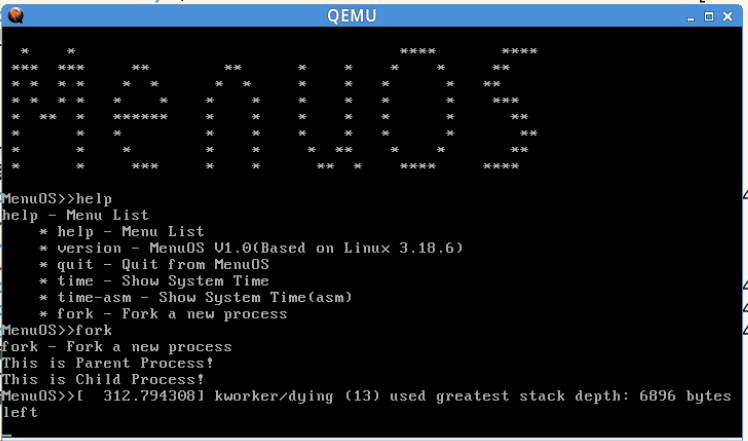
本次实验的主要目的是使用gdb跟踪创建一个新进程的过程,我们首先将fork命令加入到menuOS中,如下图所示:

先执行以下fork指令,指令可以正常运行,如下图所示:
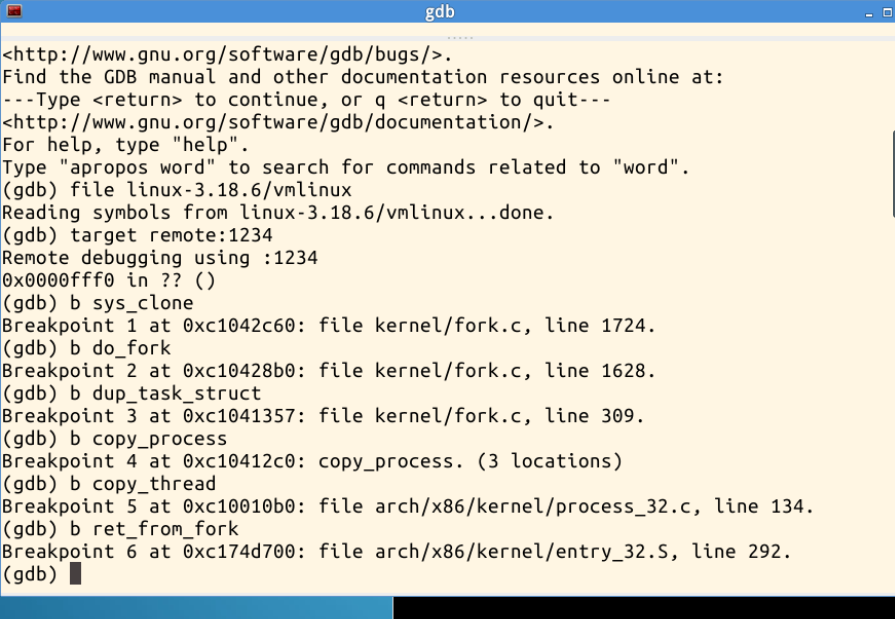
下面设置几个断点,fork指令实际上执行的就是sys_clone,我们可以在sys_clone、do_fork、dup_task_struct、copy_process、copy_thread、ret_from_fork处设置断点,如下图所示:
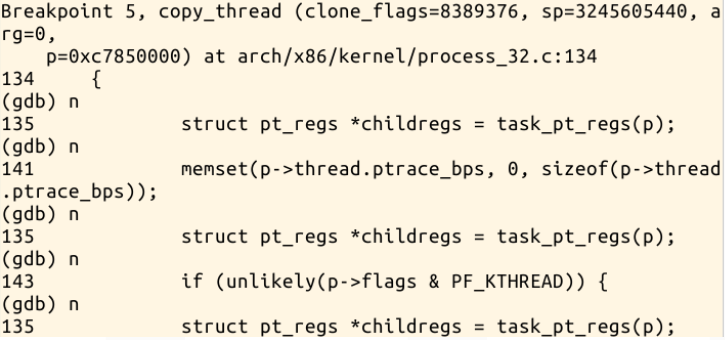
下面是部分调试执行步骤:

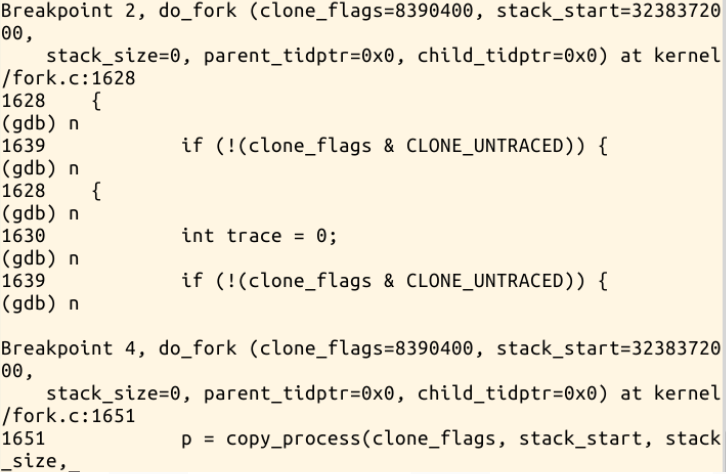

代码分析
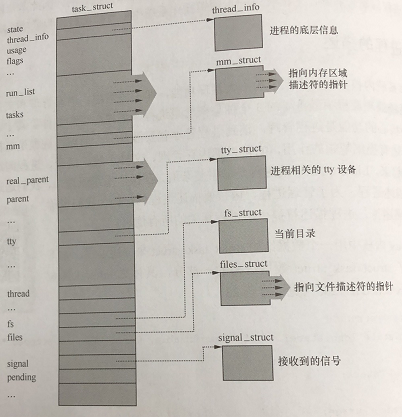
task_struct(部分)
struct task_struct {
volatile long state; /*进程状态 -1 unrunnable, 0 runnable, >0 stopped */
void *stack; /*堆栈*/
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
...
}
由于task_struct数据结构比较复杂,我们可以从以下示意图来大致了解其结构:
do_fork(关键代码部分)
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;//创建进程描述符指针
int trace = 0;
long nr;//子进程pid
...
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);//创建子进程的描述符和执行时所需的其他数据结构
if (!IS_ERR(p)) {//如果copy_process执行成功
struct completion vfork;//定义完成量
struct pid *pid;
...
pid = get_task_pid(p, PIDTYPE_PID);//获得task结构体中的pid
nr = pid_vnr(pid);//根据pid结构体中获得进程pid
...
//如果clone_flags包含CLONE_VFORK标志,就将完成量vfork赋值给进程描述符中的vfork_done字段,此处只是对完成量进行初始化
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);//将子进程添加到调度器的队列,使之有机会获得CPU
/* forking complete and child started to run, tell ptracer */
...
//如果clone_flags包含CLONE_VFORK标志,就将父进程插入等待队列直到子进程调用exec函数或退出,此处是具体的阻塞
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);//错误处理
}
return nr;//返回子进程pid(父进程fork函数返回值为子进程pid原因)
}
do_fork()函数主要完成了调用copy_process()复制父进程信息、获得pid、调用wake_up_new_task将子进程加入调度器队列等待获得分配CPU资源运行、通过clone_flags标志做一些辅助工作,其中copy_process()是创建一个进程内容的主要代码。
copy_process(太长,就主要分析一下其过程)
调用dup_task_struct复制当前进程(父进程)描述符task_struct、信息检查、初始化、更改进程状态为TASK_RUNNING(就绪态)、复制其他进程资源、调用copy_thread初始化子进程内核栈、设置子进程pid等。
dup_task_struct(关键代码部分)
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
int node = tsk_fork_get_node(orig);
int err;
tsk = alloc_task_struct_node(node);//为子进程创建进程描述符分配存储空间
...
ti = alloc_thread_info_node(tsk, node);//创建了两个页,一部分存放thread_info,一部分就是内核堆栈
...
err = arch_dup_task_struct(tsk, orig);//复制父进程的task_struct信息
...
tsk->stack = ti;//将栈底的值赋给新结点的stack
...
//对子进程的thread_info初始化(复制父进程thread_info,然后将task指针指向子进程的进程描述符)
setup_thread_stack(tsk, orig);
...
return tsk;//返回新创建的进程描述符指针
...
}
copy_thread(关键代码)
int copy_thread(unsigned long clone_flags, unsigned long sp,
unsigned long arg, struct task_struct *p)
{
struct pt_regs *childregs = task_pt_regs(p);
struct task_struct *tsk;
int err;
p->thread.sp = (unsigned long) childregs;
p->thread.sp0 = (unsigned long) (childregs+1);
memset(p->thread.ptrace_bps, 0, sizeof(p->thread.ptrace_bps));
if (unlikely(p->flags & PF_KTHREAD)) {
/* kernel thread */
memset(childregs, 0, sizeof(struct pt_regs));
//如果创建的是内核线程,则从ret_from_kernel_thread开始执行
p->thread.ip = (unsigned long) ret_from_kernel_thread;
task_user_gs(p) = __KERNEL_STACK_CANARY;
childregs->ds = __USER_DS;
childregs->es = __USER_DS;
childregs->fs = __KERNEL_PERCPU;
childregs->bx = sp; /* function */
childregs->bp = arg;
childregs->orig_ax = -1;
childregs->cs = __KERNEL_CS | get_kernel_rpl();
childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
p->thread.io_bitmap_ptr = NULL;
return 0;
}
//复制内核堆栈(复制父进程的寄存器信息,即系统调用int指令和SAVE_ALL压栈的那一部分内容)
*childregs = *current_pt_regs();
childregs->ax = 0;//将子进程的eax置0,所以fork的子进程返回值为0
...
//ip指向ret_from_fork,子进程从此处开始执行
p->thread.ip = (unsigned long) ret_from_fork;
task_user_gs(p) = get_user_gs(current_pt_regs());
...
return err;
}
总结及问题
fork系统调用在我们实际的编码运用中看似执行的非常简单,实际上其过程涉及到多个调用函数和进行复杂的执行过程,想要完全理解起来是很困难的,望在今后的运用中可以慢慢理解。
在编写一个简单的fork运用时使用如下代码进行验证fork创建子进程:
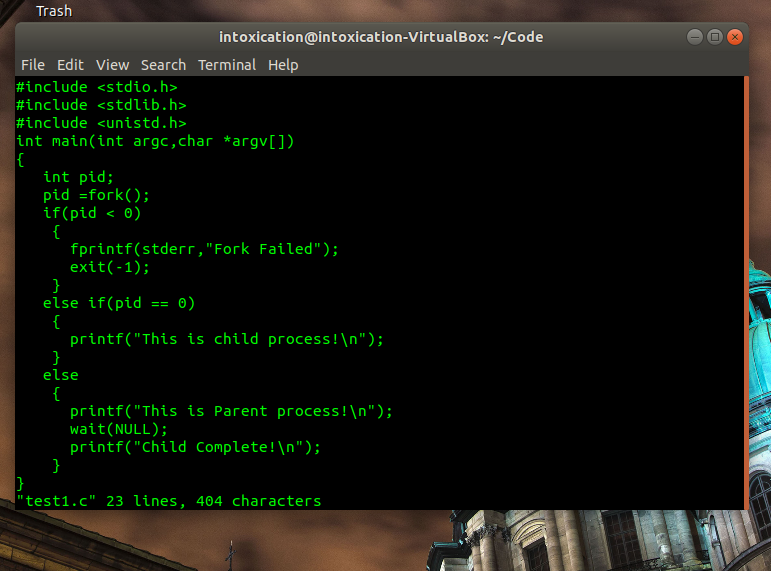
在运行时发现有时先打印父进程的输出信息,有时则先打印子进程的输出信息,如下图所示:
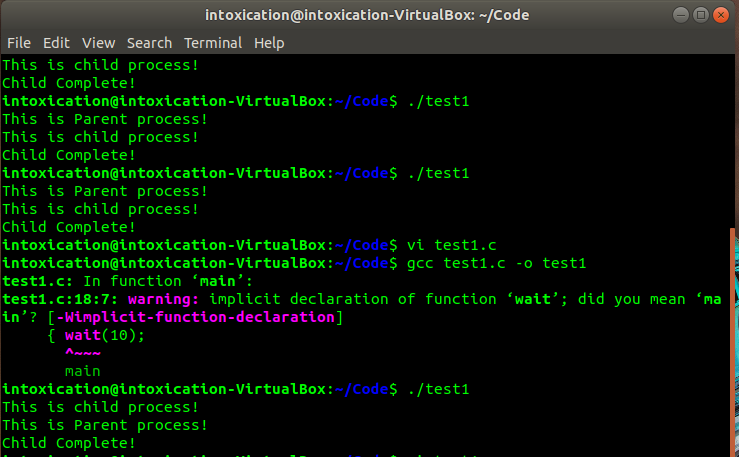
在查阅课本后了解到父子进程的执行顺序和调度算法密切相关,执行顺序是不确定的。