一、什么是Hive
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
二、Hive的体系结构
下图一为官网提供的hive体系结构。
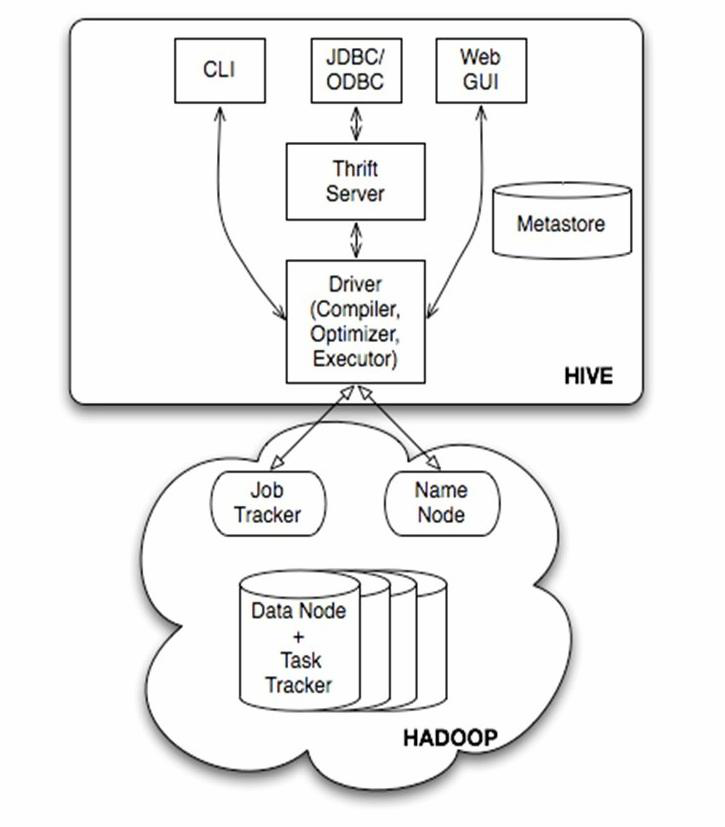
从体系结构上看,Hive是建立在 Hadoop 上的数据仓库基础构架。
1、hive的用户接口为:CLI,Hiveserver,WebUI。
①CLI为命令行客户端或者说是 命令行环境,客户端可以直接在命令行模式下进行操作。
②Hiveserver支持jdbc/odbc方式,Hive提供了Thrift服务,Thrift客户端目前支持C++/Java/PHP/Python/Ruby。
③webGUI接口,让hive提供了更加直观的web操作页面。但是处理大量数据的时候,不推荐使用。
2、Metastore 元数据存储,存储Hive所有的表与分区的结构化信息,包括列与列类型信息,序列化器与反序列化器,从而能够读写hdfs中的数据。
有三种存储方式。
①内嵌Derby方式
②Local方式
③Remote方式
关于三种存储方式,会在以后的博文中详细介绍。
3、Hadoop与Hive的关系
Hive是Hadoop的一个组件,作为数据厂库,Hive的数据是存储在Hadoop的文件系统中的,hive为Hadoop提供SQL语句,是Hadoop可以通过SQL语句操作文件系统中的数据。hive是依赖Hadoop而存在的。
在网上下载了一张图片,很明了的介绍了他们之间的关系,如下图:

三、Hive的安装
1,打开服务向导,选择安装Hive,在安装Hive之前,请安装好MapReduce。如下图

2,首先我们会看到,我们会为hive选择一组依赖关系。

3,自定义分配角色,根据实际情况,去分配角色。
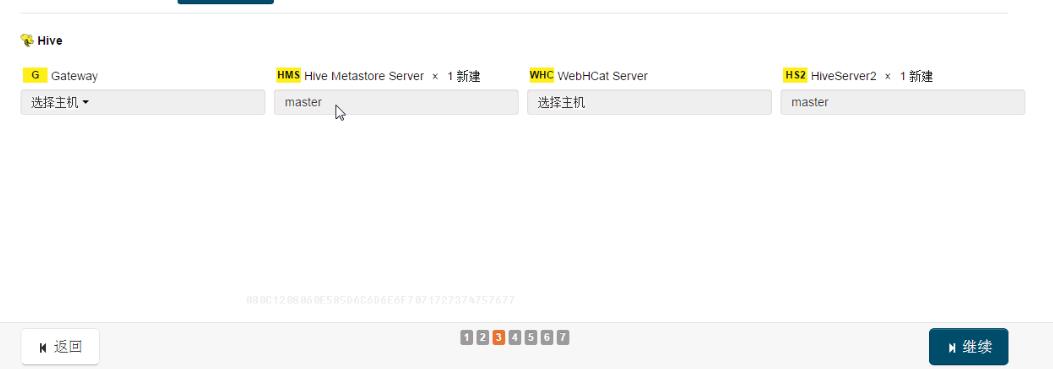
4,选择数据库,可以选选择嵌入式数据库,后期再去改。

测试连接,如果成功,点击继续。
5,安装进度。
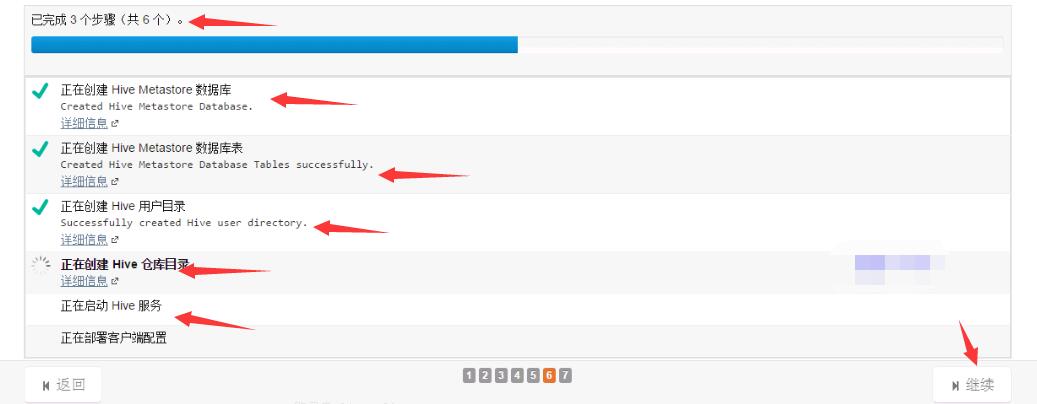
慢慢装吧,等到下一步,就成功了。
6,成功时候的界面。

完成了以后,我们也可以配置使用自定义的数据库了。